2.2. “Layer cake”-Architektur#
Die folgende Grafik (Abb. 2.3) zeigt eine Variante der geschichteten Architektur (“Layer Cake”-Architektur) des Semantic Web. Diese Struktur beschreibt, wie verschiedene Technologien und Konzepte zueinander in Bezug stehen, um das Web mit verständlichen und vernetzten Daten anzureichern. Zu diesem Modell gibt es mehrere Varianten, die im Lauf der Zeit zudem erweitert wurden. Die ursprüngliche Layer-Cake-Typologie des Semantic Web wurde vom W3C erarbeitet.
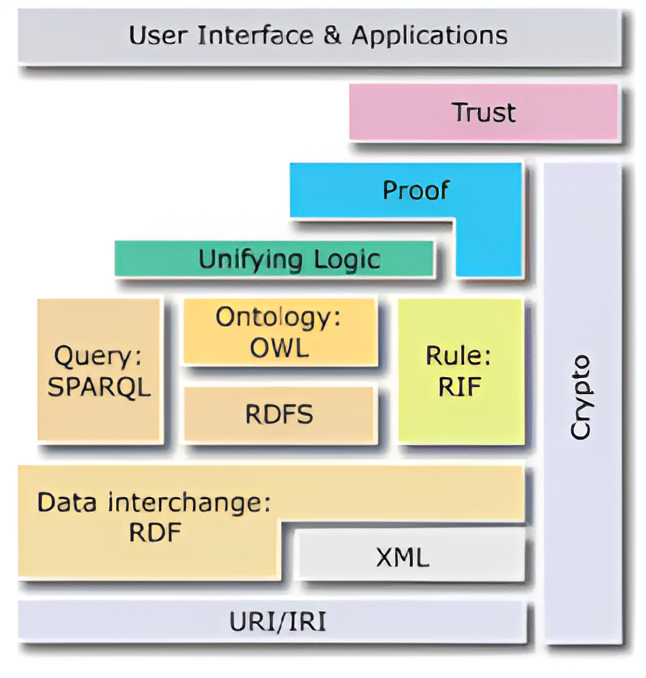
Fig. 2.3 The Semantic Web Layer Cake, (Sowa, 2011)#
Die abgebildete Variante von Sowa (2011) ist eine erweiterte Version dieses ursprünglichen Modells des W3C, die mehr Kästen und Überschneidungen zwischen den Stufen zulässt als das erste Modell. Beide erheben keinen Anspruch auf Vollständigkeit, sondern sind eher als kleinster gemeinsamer Nenner einer Vorstellung des Semantic Web zu verstehen.
Die Stufen des Modells lassen sich wie folgt von unten nach oben beschreiben:
URI (Universal Resource Indicator) / IRI (Internationalized Resource Identifier) - URI bzw. IRI stellen die Basis dar, denn sie dienen als eindeutige Adresse, um jede Ressource im Web identifizieren zu können.
XML (extensible Markup Language) - ist der Standard für die strukturierte Darstellung von Daten. In diese Ebene hinein ragt der
Datenaustausch: RDF (Resource Description Framework) - RDF ist ein Modell für die Darstellung von Daten als Tripel und erlaubt damit, Informationen so zu verknüpfen, dass Maschinen sie verstehen können.
In der Ebene darüber befindet sich mit ‘Query: SPARQL’ eine Abfragesprache für RDF-Daten, mit ‘Ontology: OWL’ und ‘RDFS’ (RDF Schema) zwei Schemata bzw. Ontologien, die es ermöglichen Beziehungen und logische Schlussfolgerungen darzustellen sowie mit ‘Rules: RIF’ ein Standard, der entwickelt wurde, um Regeln zwischen verschiedenen Regelsprachen und -systemen austauschbar zu machen.
Logic - Diese Schicht ermöglicht es, automatisierte Entscheidungen basierend auf den Daten zu treffen. Beispiel: „Wenn A wahr ist und B wahr ist, dann folgt C.“
Proof - die Prüfschicht stellt die Validität der Ergebnisse sicher, indem sie die Schritte überprüft, die zu einer Schlussfolgerung führen. Ähnlich wie bei einer mathematischen Beweisführung.
Trust - Diese Schicht definiert Vertrauen in die Daten, allerdings ist nicht abschließend geklärt, wie genau das erreicht werden kann.
User Interface & Applications - Ganz oben befinden sich Anwendungen, die auf den Semantic Web-Technologien aufbauen (z.B. intelligente Suchmaschinen).
Der Kryptografie-Balken steht für kryptografischen Technologien, die über digitale Signaturen hinausgehen.
Die Schichten bauen aufeinander auf, sind aber mehr ineinander verschränkt als ursprünglich entworfen.
Das Konzept von verlinkten Daten, oder Linked Data, ist essenziell für die vollständige Umsetzung einer erfolgreichen Semantic-Web-Struktur. In der ebenfalls vom Projekt Quadriga entworfenen Fallstudie “Reproduzierbarkeit von Datenanalysen: Ein Fallbeispiel aus dem Nationalen Bildungsbericht” finden Sie weitere Informationen zu Linked Data.
Literatur
Sowa, J. F. (2011). Future directions for semantic systems. In Tolk, A., & Jain, L. C. (Eds.), Intelligence-Based Systems Engineering (pp. 23–47). Berlin, Heidelberg: Springer Berlin Heidelberg.