Offene Daten im urbanen Raum: Datenportale, Metadaten und die Datenabfrage mit SPARQL#
Dieses JupyterBook möchte Kenntnisse zur Datenabfrage vermitteln, indem es relevante Datenportale vorstellt, über die Daten akquiriert werden können und Sie mit Metadaten, deren Qualität, Standards und Abfragesprachen vertraut macht.
Der thematische Fokus liegt auf der Arbeit mit Baumkatasterdaten. Daten zu Baumverteilungen oder -pflanzungen in Städten gewinnen zunehmend an Bedeutung, da Bäume das Mikroklima wesentlich beeinflussen. Das gestiegene Interesse der Bevölkerung an “ihren” Stadtbäumen zeigen Portale wie Gieß den Kiez, von denen wir uns zu dieser Fallstudie inspirieren lassen haben.
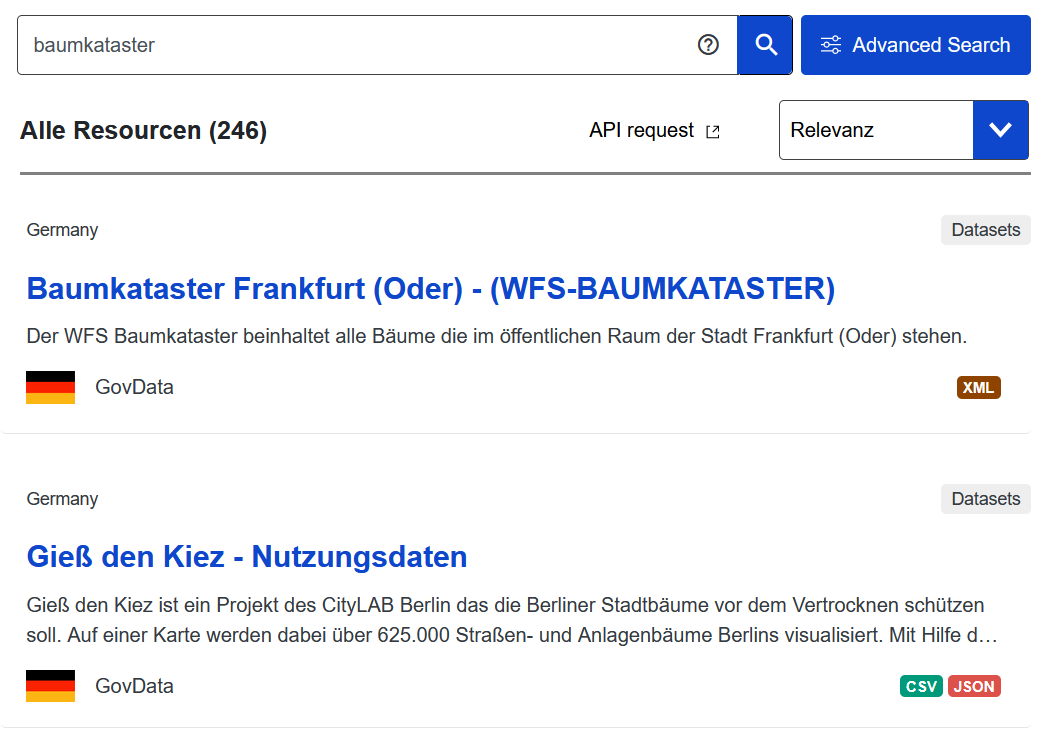
Fig. 1 Screenshot einer Suche nach dem Stichwort “Baumkataster” im europäischen Datenportal https://data.europa.eu vom 30.09.2025.#
Fokus#
Daten zu Baumbeständen sind wegen des Klimawandels vor allem in Städten aufgrund deren Auswirkung auf das Mikroklima von zentraler Bedeutung. In diesem Zusammenhang stellen Baumkataster eine wichtige Arbeitsgrundlage dar, da sie Informationen zu Baumarten, deren Standort, Alter und Zustand liefern. Doch wie gut sind diese Daten öffentlich zugänglich?
Story
Dr. Amir Weber, ein Verwaltungswissenschaftler mit Interesse an kommunalen Daten und Bürgerbeteiligung, möchte ein Dashboard zur Visualisierung von Baumbeständen erstellen, das auf offenen Datensätzen basiert. Dazu stellt sich Dr. Weber zunächst die folgende Frage:
Welche offenen Daten gibt es, die dazu beitragen, den Bewässerungsbedarf von Bäumen in einer bestimmten Region zu ermitteln?
Um diese Frage zu beantworten, vermittelt dieses JupyterBook Kenntnisse zu wichtigen Konzepten wie Semantic Web und Linked Data sowie Metadatenstandards und -qualität. Darüber hinaus erwartet Sie eine Einführung in die Benutzung der Abfragesprache SPARQL.
Bedeutung dieses Lehrbuchs für die Verwaltungswissenschaft#
Die Auffindbarkeit von Daten wird durch Metadaten wesentlich vereinfacht, wenn nicht erst ermöglicht. Ein grundlegendes Verständnis von Metadaten ist daher von entscheidender Relevanz für die Arbeit mit Daten. In Bezug zur Verwaltung(swissenschaft) gilt dies insbesondere für DCAT-AP - den gemeinsamen Metadatenstandard für offene Verwaltungsdaten. Des Weiteren lassen sich durch Abfragesprachen wie SPARQL passgenaue Informationen herausfiltern, was die Suche nach Datensätzen erleichtern kann.
Zielgruppe#
Dieses JupyterBook wurde für Verwaltungswissenschaftler:innen entworfen, da die Daten, die hier via SPARQL abgefragt werden, Daten aus der öffentlichen Verwaltung sind (Baumkatasterdaten). Diese Daten können selbstverständlich auch in anderen wissenschaftlichen Kontexten oder für Laien von Bedeutung bzw. Interesse sein. Dieses Lehrbuch steht daher allen Interessierten bzw. Forschenden offen, die wissen möchten, wie man via SPARQL Daten abfragt oder generell Interesse an der Funktionsweise von Abfragesprachen haben.
Struktur der Fallstudie#
Die Fallstudie ist in 4 Schritte aufgeteilt, die den Kapiteln entsprechen (s. Abb. 2). Dabei wird ein Bogen geschlagen von der Einführung in grundlegende Konzepte über den in der Verwaltung wichtigen Metadatenstandard DCAT-AP und das Messen der Qualität von Metadaten bis zur Suche nach Daten mithilfe der Abfragesprache SPARQL. Basierend auf den verfügbaren offenen Datenquellen werden dann Abfragen entwickelt, um relevante Informationen zu extrahieren. Diese können eine strukturierte Analyse der Daten ermöglichen, um spezifische Antworten zum Baumbestand zu erhalten.
Die Nutzung und erste Schritte mit SPARQL werden in dieser Fallstudie anschaulich erläutert.

Fig. 2 Visualisierung der 4 Schritte dieser Fallstudie.#
1. Technologien verstehen: Semantic Web & Linked Data
Wir greifen in dieser Fallstudie auf Metadaten aus dem europäischen Metadatenportal data.europa zurück. Daher werden zuerst die grundlegenden Technologien erläutert, die gängige Metadatenschemata ausmachen, nämlich Semantic Web und Linked Data.
2. Werkzeuge kennenlernen: DCAT-AP Metadatenstandard
Wir machen Sie mit einem der zentralen Werkzeug für Datenportale im Public Sector vertraut: dem DCAT-AP-Standard, der auch die politisch-administrativen Aspekte im Kontext von öffentlicher Verwaltung und Open Data einbezieht.
3. Datenqualität messen: Metadata Quality Assessment
Sie lernen, wie Sie Metadaten anhand von Maßnahmen zur Qualitätsmessung überprüfen können, um sicherzustellen, dass diese den Qualitätsanforderungen entsprechen. Dazu stellen wir Ihnen die verschiedenen Qualitätskriterien des Metadata Quality Assessment (MQA) vor.
4. Praxis anwenden: SPARQL-Abfragen
Im letzten Schritt der Fallstudie widmen wir uns der praktischen Anwendung und erläutern, wie Metadaten mithilfe von SPARQL abgefragt werden können. Dabei vermitteln wir zunächst die grundlegende Funktionsweise von SPARQL, einschließlich der Syntax und zentraler Befehle. Im Anschluss führen wir gezielte Abfragen durch, die auf unsere Fragestellung ausgerichtet sind und evaluieren kritisch, in welchem Maß die aktuellen Implementierungen erfolgreich sind oder Optimierungspotenzial aufweisen.
Die Gliederung der Fallstudie in Kapitel und Unterkapitel können Sie immer in der Menüleiste auf der linken Seite nachvollziehen. Die rechte Menüleiste zeigt Ihnen an, in welchem Abschnitt eines Kapitels Sie sich gerade befinden. Die einzelnen Kapitel sind so gestaltet, dass Sie sie sowohl nacheinander als auch separat voneinander durchgehen können.
Das JupyterBook lässt sich in zwei Hauptblöcke gliedern:
Block |
Inhalte |
Bearbeitungszeit |
|---|---|---|
Block 1 |
Kapitel 2, 3, 4: Grundlagen des Semantic Web, Metadatenstandards und Metadatenqualität |
ca. 3 x 20-30 Min pro Kapitel |
Block 2 |
Kapitel 5: Praktische Anwendung von SPARQL: Abfrage von Daten zur Beantwortung der Forschungsfrage |
ca. 40 Min |