
7.4. 🚀 Korpusanalyse – Visualisierung der Textkomplexität#
Feinlernziel(e) dieses Kapitels
Sie können die Konzeption der Analyse beschreiben und andere Möglichkeiten des Korpus-Splitting entwerfen.
Sie können das Konzept eines Balkendiagramms erklären und das erstellte Diagramm interpretieren sowie die Gründe für Ihre Interpretation nennen.
Hinweise zur Ausführung des Notebooks
Dieses Notebook kann auf unterschiedlichen Levels erarbeitet werden (siehe Abschnitt “Technische Voraussetzungen”):
Book-Only Mode: Sie lesen das Notebook hier im “Jupyter Book”, ohne den Code selbst auszuführen.
Cloud Mode: Klicken Sie oben rechts in der Menüleiste auf das Raketen-Symbol 🚀 und wählen Sie “Colab”, um das Notebook auszuführen.
Local Mode: Klicken Sie oben rechts in der Menüleiste auf das Download-Symbol ↓ und wählen Sie “.ipynb”, um das Notebook lokal auszuführen.
7.4.1. Übersicht#
Im Folgenden wird die Textkomplexität der einzelnen Pressemitteilungen für unterschiedliche Zeitabschnitte (Monate, Jahre) zusammengefasst und visualisiert.
Einlesen der Tabelle mit den Textkomplexitätsscores
Zusammenfassung für Zeitabschnitte
Ergebnisse in einem Liniendiagramm visualisieren
Informationen zum Ausführen des Notebooks – Zum Ausklappen klicken ⬇️
Voraussetzungen zur Ausführung des Jupyter Notebooks
- Installieren der Bibliotheken
- 2. Laden der Daten (s.u.)
- 3. Pfad zu den Daten setzen
Show code cell content
# 🚀 Install libraries
! pip install pandas matplotlib bokeh requests
Show code cell content
# import libraries for table processing and for compuation of readability metrics
from pathlib import Path
import pandas as pd
import matplotlib.pyplot as plt
from bokeh.io import output_notebook, show
from bokeh.plotting import figure
from bokeh.layouts import column, row, layout
from bokeh.models import ColumnDataSource, CustomJS, TextInput, Div, RadioButtonGroup, Switch, TableColumn, DataTable
# Ensure Bokeh output is displayed in the notebook
output_notebook()
Bevor wir Daten herunterladen, definieren wir eine kleine Hilfsfunktion download_file. Sie lädt eine Datei plattformunabhängig – also auch unter Windows – aus dem Internet in einen Zielordner herunter und ersetzt damit das Kommando wget, das nicht auf allen Systemen verfügbar ist.
# helper: download a single file (cross-platform replacement for `! wget -P`)
import requests
from pathlib import Path
def download_file(url, target_dir):
"""Download the file at `url` into `target_dir`, keeping its original name."""
target_dir = Path(target_dir)
target_dir.mkdir(parents=True, exist_ok=True)
target_path = target_dir / url.split("/")[-1]
response = requests.get(url)
response.raise_for_status()
target_path.write_bytes(response.content)
return target_path
7.4.2. Einlesen der Textkomplexitätsscores#
Informationen zum Ausführen des Notebooks – Zum Ausklappen klicken ⬇️
Zuerst wird der Ordner angelegt, in dem die Textdateien gespeichert werden. Der Einfachheit halber wird die gleich Datenablagestruktur wie in dem GitHub Repository, in dem die Daten gespeichert sind, vorausgesetzt. Der Text wird aus GitHub heruntergeladen und in dem Ordner ../data/txt/ abgespeichert. Der Pfad kann in der Variable text_path angepasst werden. Die einzulesenden Dateien müssen die Endung `.txt` haben.# 🚀 Create result directory path
result_dir = Path(r"../results")
if not result_dir.exists():
result_dir.mkdir()
Show code cell content
# 🚀 Load the results file from GitHub
download_file("https://raw.githubusercontent.com/quadriga-dk/Text-Fallstudie-2/refs/heads/main/results/metadata_with_readability_scores.csv", "../results/")
result_path = result_dir / r"metadata_with_readability_scores.csv"
result_df = pd.read_csv(result_path, sep=",")
# Convert date to datetime
result_df['date'] = pd.to_datetime(result_df['DC.date'], dayfirst=True)
Die Anzahl der Einträge anzeigen lassen:
len(result_df)
51826
Erste 100 Zeilen angucken:
# Too slow if done with entire data frame
# Convert DataFrame to ColumnDataSource
source = ColumnDataSource(result_df[:100])
# Create Table Columns
columns = [TableColumn(field=col, title=col) for col in result_df.head().columns]
# Create DataTable
data_table = DataTable(source=source, columns=columns)
# Display DataTable
output_notebook() # Use this to render in Jupyter Notebook
show(layout([data_table]))
7.4.3. Analyse#
Übersicht über die Daten erhalten#
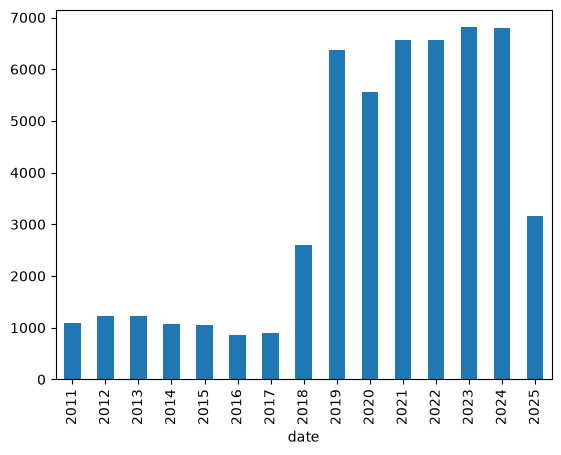
Wie viele Pressemitteilungen gab es pro Jahr?
result_df.groupby(pd.PeriodIndex(result_df['date'], freq="Y"))['n_tokens'].count().plot(kind="bar")
<Axes: xlabel='date'>
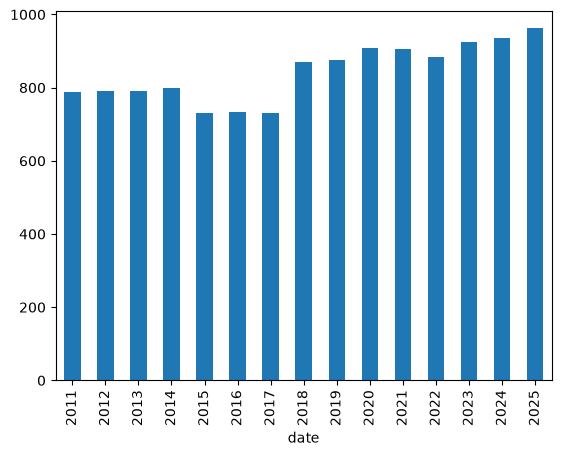
Wie lang sind die Pressemitteilungen im Schnitt in Wörtern?
result_df.groupby(pd.PeriodIndex(result_df['date'], freq="Y"))['n_tokens'].mean().plot(kind="bar")
<Axes: xlabel='date'>
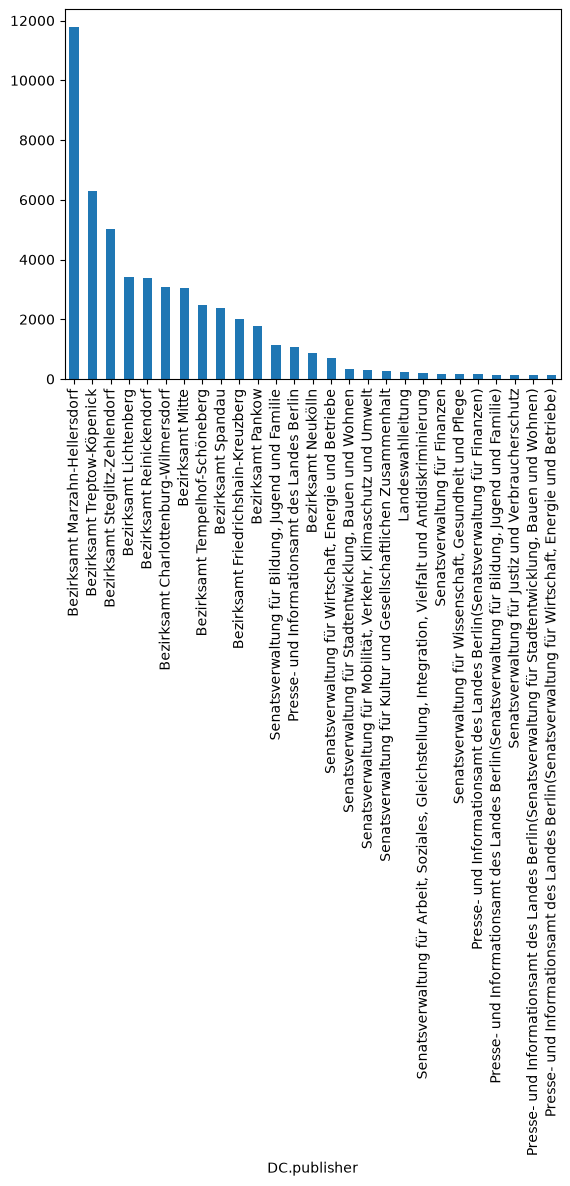
Wie viele Mitteilungen aus welcher Kategorie sind vorhanden? Da die Anzahl der Kategorien hoch ist, zeigen wir nur die Kategorien, die mit 100 Mitteilungen oder mehr vertreten sind.
counts = result_df['DC.publisher'].value_counts()
counts[counts > 100].plot(kind="bar")
<Axes: xlabel='DC.publisher'>
Extrahieren von schwierigsten und einfachsten Texten#
metrics = ["Flesch", "ARI", "Coleman_Liau", "Wiener_Sachtextformel"]
# TODO: prettify
for metric in metrics:
print(metric)
if metric == "Flesch":
print(f"Schwierigster Text: {result_df[result_df[metric] == result_df[metric].min()]['DC.identifier']}")
print(f"Leichester Text: {result_df[result_df[metric] == result_df[metric].max()]['DC.identifier']}\n")
else:
print(f"Schwierigster Text: {result_df[result_df[metric] == result_df[metric].max()]['DC.identifier']}")
print(f"Leichester Text: {result_df[result_df[metric] == result_df[metric].min()]['DC.identifier']}\n")
Flesch
Schwierigster Text: 22932 1139775
Name: DC.identifier, dtype: int64
Leichester Text: 41925 761243
Name: DC.identifier, dtype: int64
ARI
Schwierigster Text: 9444 1403106
Name: DC.identifier, dtype: int64
Leichester Text: 46803 334269
Name: DC.identifier, dtype: int64
Coleman_Liau
Schwierigster Text: 22932 1139775
Name: DC.identifier, dtype: int64
Leichester Text: 40337 796065
Name: DC.identifier, dtype: int64
Wiener_Sachtextformel
Schwierigster Text: 9444 1403106
Name: DC.identifier, dtype: int64
Leichester Text: 44727 627469
Name: DC.identifier, dtype: int64
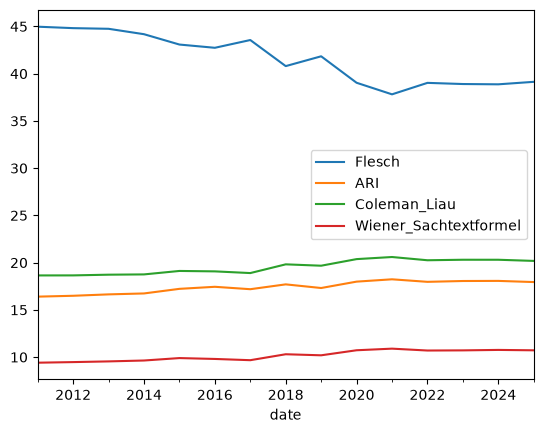
Wie zu sehen ist, überschneiden sich die Metriken in Bezug auf die Extremwerte (niedrigster und höchster Wert) nicht.
7.4.4. Entwicklung über Zeit#
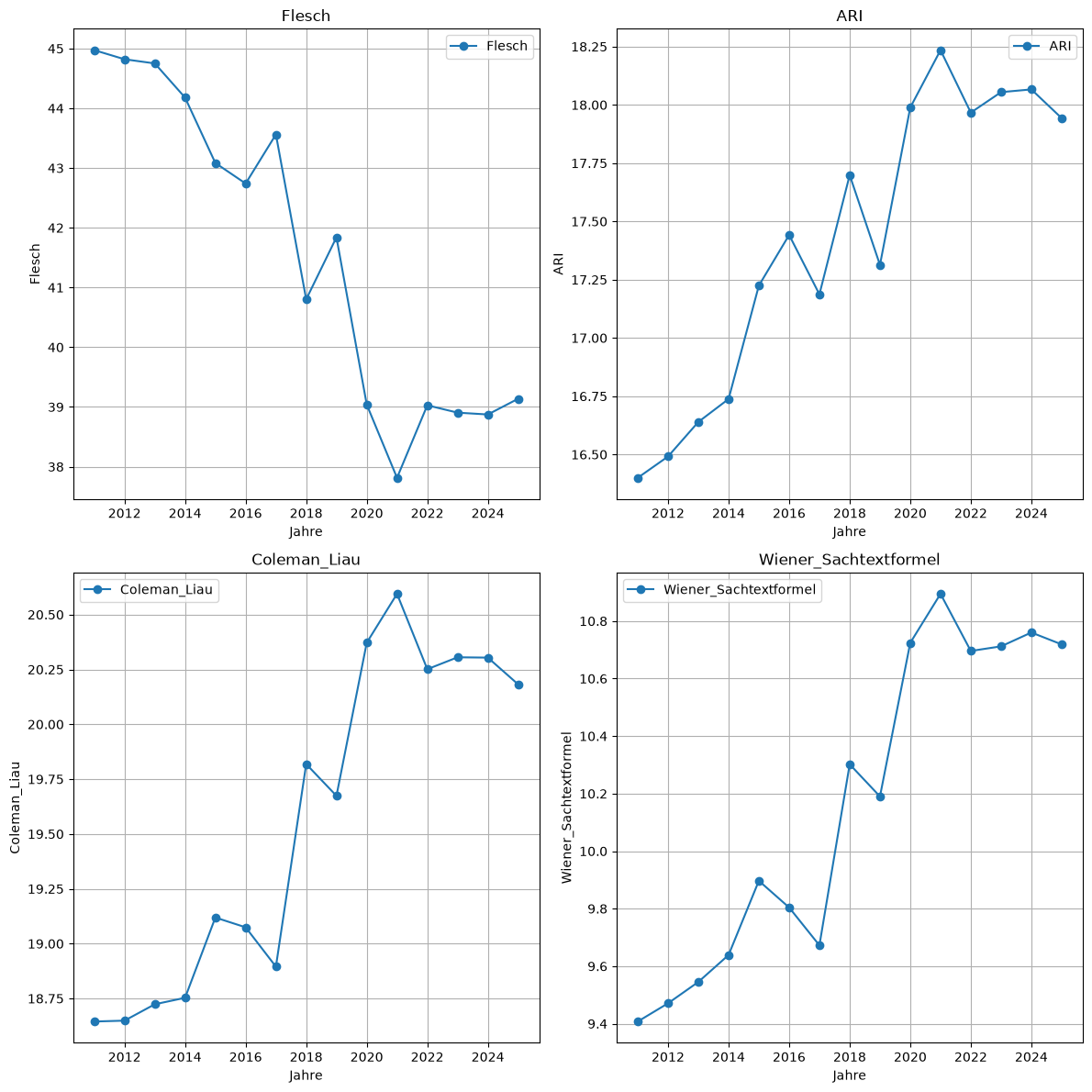
Vergleich der Metriken-Entwicklung über die Jahre
metric_mean_year_df = result_df.groupby(pd.PeriodIndex(result_df['date'], freq="Y"))[metrics].mean()
metric_mean_year_df.plot()
<Axes: xlabel='date'>
# Create subplots -- attention, they don't start with 0!
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(12, 12))
axes = axes.flatten()
for i, col in enumerate(metrics):
axes[i].plot(metric_mean_year_df.index.year, metric_mean_year_df[col], marker='o', label=col)
axes[i].set_title(f'{col}')
axes[i].set_xlabel('Jahre')
axes[i].set_ylabel(col)
axes[i].legend()
axes[i].grid(True)
plt.tight_layout() # Adjust layout to prevent overlap
plt.show()
3.2 Interaktive Analysedaten vorbereiten#
Wir wollen die Daten nun nach den Parametern der Metrik und der Granularität der Zeitschiene einteilen.
columns_to_keep = []
columns_to_keep.extend(metrics)
columns_to_keep.append("date")
print(columns_to_keep)
['Flesch', 'ARI', 'Coleman_Liau', 'Wiener_Sachtextformel', 'date']
results_filtered = result_df[columns_to_keep]
Show code cell content
def plot_with_js(results_filtered_df: pd.DataFrame) -> None:
"""
:param pd.DataFrame merged_df: The merged dataframe of all annotations
"""
frequency_parameters = ["Y", "M", "W-MON"]
metrics_to_time_frame = {}
for metric in metrics:
metrics_to_time_frame[metric] = {}
for option in frequency_parameters:
result = results_filtered.groupby(pd.PeriodIndex(results_filtered['date'], freq=option))[metric].mean()
metrics_to_time_frame[metric][option] = {"x": result.index.to_timestamp(), "y": result.values}
# Set year as default for the plot
line_source = ColumnDataSource(data=metrics_to_time_frame["Flesch"]["Y"])
# Create a plot
p = figure(title=f"Lesbarkeitsmaß", x_axis_type="datetime", x_axis_label='Zeit',
y_axis_label='Durschnittlicher Score', width=700, height=400)
line = p.line('x', 'y', source=line_source, line_width=2, color='blue')
# RadioButtonGroup to select mode
radio_button_group_time = RadioButtonGroup(labels=["Yearly", "Monthly", "Weekly"], active=0)
radio_button_group_metric = RadioButtonGroup(labels=["Flesch", "ARI", "Coleman_Liau", "Wiener_Sachtextformel"], active=0)
# Callback to update the data based on selected mode
callback = CustomJS(
args=dict(
line=line,
sources=metrics_to_time_frame,
radio_button_group_time=radio_button_group_time,
radio_button_group_metric=radio_button_group_metric
),
code="""
// Access the value of the switch
// const sources = switch_element.active ? relative_sources : absolute_sources;
// Access the value of the RadioButtonGroup Time
const mode = radio_button_group_time.active;
// Access the value of the RadioButtonGroup
const base = radio_button_group_metric.active;
// Retrieve the selected frequency
const freq = ["Y", "M", "W-MON"][mode];
// Retrieve the selected metric
const metric = ["Flesch", "ARI", "Coleman_Liau", "Wiener_Sachtextformel"][base];
// update data source and emit change event
line.data_source.data = sources[metric][freq];
line.data_source.change.emit();
""",
)
# Attach the callback to both widgets
radio_button_group_time.js_on_change('active', callback)
radio_button_group_metric.js_on_change('active', callback)
# Layout the RadioButtonGroup and plot
layout = column(row(radio_button_group_metric, radio_button_group_time), p)
show(layout)
plot_with_js(results_filtered)