
4.3. 🚀 Quellcode-Analyse einer Website#
Hinweise zur Ausführung des Notebooks
Dieses Notebook kann auf unterschiedlichen Levels erarbeitet werden (siehe Abschnitt “Technische Voraussetzungen”):
Book-Only Mode: Sie lesen das Notebook hier im “Jupyter Book”, ohne den Code selbst auszuführen.
Cloud Mode: Klicken Sie oben rechts in der Menüleiste auf das Raketen-Symbol 🚀 und wählen Sie “Colab”, um das Notebook auszuführen.
Local Mode: Klicken Sie oben rechts in der Menüleiste auf das Download-Symbol ↓ und wählen Sie “.ipynb”, um das Notebook lokal auszuführen.
4.3.1. Übersicht#
Im Folgenden wird exemplarisch der HTML-Code der Website der Senatskanzlei Berlin auf seine Struktur hin untersucht und es wird eine strukturierte Methode zur Inhaltsextraktion entwickelt.
Dafür werden folgende Schritte durchgeführt:
Strukturanalyse des HTML-Codes
Strukturiertes Parsen des HTML-Codes
Verlinkten Seiten nachgehen und parsen
Ergebnisse speichern
Informationen zum Ausführen des Notebooks – Zum Ausklappen klicken ⬇️
Voraussetzungen zur Ausführung des Jupyter Notebooks:
- Installieren der Bibliotheken
Show code cell content
# 🚀 Install libraries
! pip install requests beautifulsoup4 pandas
Show code cell content
# load libraries
from datetime import datetime
from pathlib import Path
import requests
from bs4 import BeautifulSoup, Tag, Comment
import pandas as pd
Bevor wir Daten herunterladen, definieren wir eine kleine Hilfsfunktion download_file. Sie lädt eine Datei plattformunabhängig – also auch unter Windows – aus dem Internet in einen Zielordner herunter und ersetzt damit das Kommando wget, das nicht auf allen Systemen verfügbar ist.
# helper: download a single file (cross-platform replacement for `! wget -P`)
import requests
from pathlib import Path
def download_file(url, target_dir):
"""Download the file at `url` into `target_dir`, keeping its original name."""
target_dir = Path(target_dir)
target_dir.mkdir(parents=True, exist_ok=True)
target_path = target_dir / url.split("/")[-1]
response = requests.get(url)
response.raise_for_status()
target_path.write_bytes(response.content)
return target_path
4.3.2. Laden des HTML-Codes#
Im Folgenden laden wir den HTML Code der Website des Berliner Senats (https://www.berlin.de/rbmskzl/) vom 06.06.2025, den wir im Vorhinein in einer .html-Datei gespeichert haben.
Informationen zum Ausführen des Notebooks – Zum Ausklappen klicken ⬇️
Zuerst wird der Ordner angelegt, in dem die HTML-Datei gespeichert wird. Der Einfachheit halber wird die gleiche Datenablagestruktur wie in dem GitHub Repository, in dem die Daten gespeichert sind, vorausgesetzt. Der Text wird aus GitHub heruntergeladen und in dem Ordner ../data/html/ abgespeichert. Der Pfad kann in der Variable text_path angepasst werden. Die einzulesenden Daten müssen die Endung `.html` haben.Show code cell content
# 🚀 Create data directory path
corpus_dir = Path("../data/html")
corpus_dir.mkdir(parents=True, exist_ok=True)
Show code cell content
# 🚀 Load the html file from GitHub
download_file("https://raw.githubusercontent.com/quadriga-dk/Text-Fallstudie-2/refs/heads/main/data/html/2025-06-06-Senatskanzlei.html", "../data/html")
# Set file paths
path_to_html_doc = Path("../data/html/2025-06-06-Senatskanzlei.html")
# Read the text
html_text = path_to_html_doc.read_text(encoding="utf-8")
# Parse the html structure
soup = BeautifulSoup(html_text)
Der obere Teil der Website und der korrespondierende HTML-Code sahen zum Zeitpunkt der Speicherung so aus:
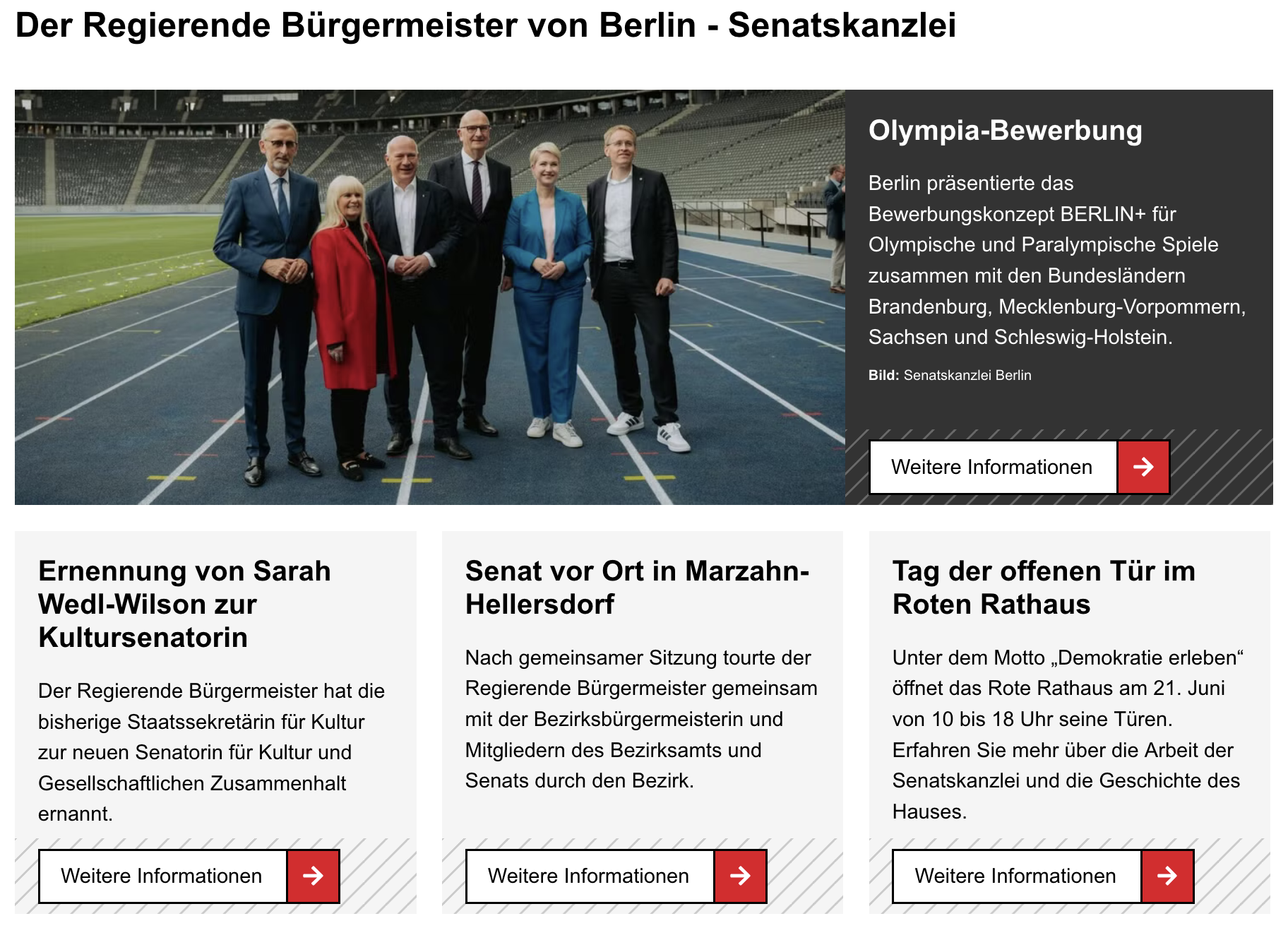

Orange Markierungen zeigen in welchen HTML-Tags der sichtbare Text gespeichert ist. Blaue Markierungen zeigen an, worauf die Links unter “Weitere Informationen” verweisen.
4.3.3. Strukturelle Analyse#
Vorgehen#
Im nächsten Schritt soll ein kleines Programm entwickelt werden, dass den Text der Website sowie die Links zu den vollen Artikeln extrahiert. Da der Text schon in einer strukturierten Form vorliegt, soll von dieser Gebrauch gemacht werden und Titel von Teaser getrennt extrahiert werden.
Wir können mit Hilfe der Python-Bibliothek beautifulsoup die geschachtelte Struktur des HTML-Codes navigieren. Dafür gucken wir zuerst:
Ist die visuelle Aufteilung der Seite in den Tags abgebildet?
Welche Tags (mit Attribut) unterteilen die Abschnitte?
Sind die Tags für den gegebenen Abschnitt einzigartig?
Wie sind die Tags hierarchisch strukturiert?
Ausschnitt identifizieren#
Wir sehen, dass der links abgebildete Inhalt dem div-Container <div> mit CSS class 'herounit-homepage herounit-homepage--default' untergeordnet ist und können diesen und alle untergeordneten Tags (sogenannte “children”) mit beautifulsoup extrahieren.
# get all tags that are children of the div tag with matching CSS class
topdiv = soup.find("div", {"class": "herounit-homepage herounit-homepage--default"})
# print the content of the topdiv
print(topdiv.prettify())
<div class="herounit-homepage herounit-homepage--default">
<h1 class="title">
Der Regierende Bürgermeister von Berlin - Senatskanzlei
</h1>
<div class="modul-buehne buehne--tileslayout">
<ul class="buhne__list--teaser">
<li>
<div class="modul-teaser_buehne" data-add-clickable-area="smart">
<div class="teaser_buehne__left">
<div class="image">
<!-- Image.view -->
<div class="image__image image__image" style="">
<img alt="Vorstellung der Olympiabewerbung" class="jpg" data-orig="/rbmskzl/aktuelles/media/crop_1321.1499938964844_660.5749969482422_80.85000610351562_425.58331298828125_1500_1195_0f74a246bdaf1eef1ad8b390ceb4b34f_img_4988-min.jpg" loading="lazy" src="/imgscaler/lts6lo0GIkkJajrWNaA4k-MFCScIR86PoiDCWI95q-E/rbig2zu1/L3N5czExLXByb2QvcmJtc2t6bC9ha3R1ZWxsZXMvbWVkaWEvY3JvcF8xMzIxLjE0OTk5Mzg5NjQ4NDRfNjYwLjU3NDk5Njk0ODI0MjJfODAuODUwMDA2MTAzNTE1NjJfNDI1LjU4MzMxMjk4ODI4MTI1XzE1MDBfMTE5NV8wZjc0YTI0NmJkYWYxZWVmMWFkOGIzOTBjZWI0YjM0Zl9pbWdfNDk4OC1taW4uanBn.jpg?ts=1748424972"/>
</div>
<p class="image__copyright">
Bild: Senatskanzlei Berlin
</p>
<!-- /Image.view -->
</div>
</div>
<div class="teaser_buehne__right">
<div class="inner">
<h2 class="title">
Olympia-Bewerbung
</h2>
<p class="text">
Berlin präsentierte das Bewerbungskonzept BERLIN+ für Olympische und Paralympische Spiele zusammen mit den Bundesländern Brandenburg, Mecklenburg-Vorpommern, Sachsen und Schleswig-Holstein.
</p>
<span class="action">
<a aria-label="Olympia-Bewerbung" class="more" href="/rbmskzl/aktuelles/media/vorstellung-der-olympiabewerbung-1564707.php" title="Olympia-Bewerbung">
Weitere Informationen
</a>
</span>
<span class="image__copyright">
<strong>
Bild:
</strong>
Senatskanzlei Berlin
</span>
</div>
</div>
</div>
</li>
<li>
<div class="modul-teasertile_buehne" data-add-clickable-area="full">
<h2 class="title">
Ernennung von Sarah Wedl-Wilson zur Kultursenatorin
</h2>
<p class="text">
Der Regierende Bürgermeister hat die bisherige Staatssekretärin für Kultur zur neuen Senatorin für Kultur und Gesellschaftlichen Zusammenhalt ernannt.
</p>
<span class="action">
<a aria-label="Ernennung von Sarah Wedl-Wilson zur Kultursenatorin" class="more" href="/rbmskzl/aktuelles/pressemitteilungen/2025/pressemitteilung.1562402.php" title="Ernennung von Sarah Wedl-Wilson zur Kultursenatorin">
Weitere Informationen
</a>
</span>
</div>
</li>
<li>
<div class="modul-teasertile_buehne" data-add-clickable-area="full">
<h2 class="title">
Senat vor Ort in Marzahn-Hellersdorf
</h2>
<p class="text">
Nach gemeinsamer Sitzung tourte der Regierende Bürgermeister gemeinsam mit der Bezirksbürgermeisterin und Mitgliedern des Bezirksamts und Senats durch den Bezirk.
</p>
<span class="action">
<a aria-label="Senat vor Ort in Marzahn-Hellersdorf" class="more" href="/rbmskzl/aktuelles/media/senat-vor-ort-berliner-senat-zu-besuch-im-bezirk-marzahn-hellersdorf-1561815.php" title="Senat vor Ort in Marzahn-Hellersdorf">
Weitere Informationen
</a>
</span>
</div>
</li>
<li>
<div class="modul-teasertile_buehne" data-add-clickable-area="full">
<h2 class="title">
Tag der offenen Tür im Roten Rathaus
</h2>
<p class="text">
Unter dem Motto „Demokratie erleben“ öffnet das Rote Rathaus am 21. Juni von 10 bis 18 Uhr seine Türen. Erfahren Sie mehr über die Arbeit der Senatskanzlei und die Geschichte des Hauses.
</p>
<span class="action">
<a aria-label="Tag der offenen Tür im Roten Rathaus" class="more" href="/offenes-rotes-rathaus" title="Tag der offenen Tür im Roten Rathaus">
Weitere Informationen
</a>
</span>
</div>
</li>
</ul>
</div>
</div>
Titel extrahieren#
Wir sehen, dass alle Überschriften unter h2-Tags stehen. Diese können wir im nächsten Schritt extrahieren. Wir gehen dabei von dem bereits extrahierten Top-Div aus und extrahieren nur h2-Tags, die diesem Tag untergeordnet sind.
topdiv_h2titles = topdiv.find_all('h2')
# get all h2 content that is a child of the top div
topdiv_h2titles = topdiv.find_all('h2')
# retrieve the content and clean it
topdiv_h2titles = [entry.text.strip() for entry in topdiv_h2titles]
print(topdiv_h2titles)
['Olympia-Bewerbung', 'Ernennung von Sarah Wedl-Wilson zur Kultursenatorin', 'Senat vor Ort in Marzahn-Hellersdorf', 'Tag der offenen Tür im Roten Rathaus']
Kurzbeschreibungen extrahieren#
Wir sehen weiter, dass alle Kurzbeschreibungen als paragraphs <p> ausgezeichnet sind. Im Folgenden extrahieren wir alle Paragraphen und lassen uns das Ergebnis anzeigen.
# get all paragraphs that are children of the top div
topdiv_texts = topdiv.find_all('p')
topdiv_texts
[<p class="image__copyright">
Bild: Senatskanzlei Berlin </p>,
<p class="text">
Berlin präsentierte das Bewerbungskonzept BERLIN+ für Olympische und Paralympische Spiele zusammen mit den Bundesländern Brandenburg, Mecklenburg-Vorpommern, Sachsen und Schleswig-Holstein. </p>,
<p class="text">
Der Regierende Bürgermeister hat die bisherige Staatssekretärin für Kultur zur neuen Senatorin für Kultur und Gesellschaftlichen Zusammenhalt ernannt. </p>,
<p class="text">
Nach gemeinsamer Sitzung tourte der Regierende Bürgermeister gemeinsam mit der Bezirksbürgermeisterin und Mitgliedern des Bezirksamts und Senats durch den Bezirk. </p>,
<p class="text">
Unter dem Motto „Demokratie erleben“ öffnet das Rote Rathaus am 21. Juni von 10 bis 18 Uhr seine Türen. Erfahren Sie mehr über die Arbeit der Senatskanzlei und die Geschichte des Hauses. </p>]
Wir extrahieren zwar so alle Kurzbeschreibungen, unsere Liste beinhaltet allerdings auch die Beschreibung eines Bilds. Da sich das class-Attribut der Kurzbeschreibung von dem des Bilds unterscheidet, können wir durch das zusätzliche Abgleichen des Attributs eine Liste erstellen, in der nur die Kurzbeschreibungen vorhanden sind:
# get all short description from the p for which the attribute "class" equals "text"
topdiv_texts = topdiv.find_all('p', {"class":"text"})
# retrieve the content and clean it
topdiv_texts = [entry.text.strip() for entry in topdiv_texts]
# print the extracted content
topdiv_texts
['Berlin präsentierte das Bewerbungskonzept BERLIN+ für Olympische und Paralympische Spiele zusammen mit den Bundesländern Brandenburg, Mecklenburg-Vorpommern, Sachsen und Schleswig-Holstein.',
'Der Regierende Bürgermeister hat die bisherige Staatssekretärin für Kultur zur neuen Senatorin für Kultur und Gesellschaftlichen Zusammenhalt ernannt.',
'Nach gemeinsamer Sitzung tourte der Regierende Bürgermeister gemeinsam mit der Bezirksbürgermeisterin und Mitgliedern des Bezirksamts und Senats durch den Bezirk.',
'Unter dem Motto „Demokratie erleben“ öffnet das Rote Rathaus am 21. Juni von 10 bis 18 Uhr seine Türen. Erfahren Sie mehr über die Arbeit der Senatskanzlei und die Geschichte des Hauses.']
Links extrahieren#
Auf die gleiche Weise können wir alle Hyperlinks, die in <a>-Tags gespeichert sind extrahieren. Der Hyperlink selbst steht in dem Attribut href, dessen Wert wir gezielt abfragen.
topdiv_links = topdiv.find_all('a')
topdiv_links = [entry.get('href') for entry in topdiv_links]
# print the extracted links
topdiv_links
['/rbmskzl/aktuelles/media/vorstellung-der-olympiabewerbung-1564707.php',
'/rbmskzl/aktuelles/pressemitteilungen/2025/pressemitteilung.1562402.php',
'/rbmskzl/aktuelles/media/senat-vor-ort-berliner-senat-zu-besuch-im-bezirk-marzahn-hellersdorf-1561815.php',
'/offenes-rotes-rathaus']
Wir sehen, dass die Links keine vollständigen URLs sind, da sie weder mit www. noch mit https:// anfangen. Diese Links nennen wir relative URLs. Sie verweisen auf Unterseiten der aktuellen Seite (die Startseite der Senatskanzlei). Die Adresse der Unterseiten wird relativ zur aktuellen Seite angegeben.
Die Abfrage dieser relativen URLs in einem Browser funktioniert nicht, es wird ein File not found-Error zurückgegeben, da der Browser versucht eine Datei im lokalen Dateisystem zu öffnen und die angegebene Datei nicht findet. Um die Website abfragen zu können, müssen wir die relativen URLs in absolute URLs umwandeln. Beim Umwandeln wird das Präfix der aktuellen Seite vorangestellt werden, in unserem Fall “https://www.berlin.de/”.
# create absolute URLs
def make_links_absolute(link_list, prefix="https://www.berlin.de"):
absolute_links = []
for link in link_list:
if not link.startswith("https"):
absolute_links.append(prefix + link)
else:
absolute_links.append(link)
return absolute_links
topdiv_absolute_links = make_links_absolute(topdiv_links)
topdiv_absolute_links
['https://www.berlin.de/rbmskzl/aktuelles/media/vorstellung-der-olympiabewerbung-1564707.php',
'https://www.berlin.de/rbmskzl/aktuelles/pressemitteilungen/2025/pressemitteilung.1562402.php',
'https://www.berlin.de/rbmskzl/aktuelles/media/senat-vor-ort-berliner-senat-zu-besuch-im-bezirk-marzahn-hellersdorf-1561815.php',
'https://www.berlin.de/offenes-rotes-rathaus']
4.3.4. Zusammenfügen der Daten#
Wir haben nun unterschiedliche drei Listen mit zusammenhängende Daten aus dem HTML-Code extrahiert:
Titel
Teaser-Text
URLs zu den vollständigen Artikeln
Diese wollen in einem nächsten Schritt zusammenfügen. Dafür prüfen wir zuerst die Vollständigkeit der Daten, das heißt, ob alle Listen die gleiche Länge haben. Da wir die Daten immer in derselben Reihenfolge abgeschritten sind, können wir die Reihenfolge der Listen nutzen, um sie zusammenzufügen.
Wir speichern zusätzlich ein weiteres Metadatum und zwar das Datum der Extraktion.
Die Daten bilden wir in einer Tabelle ab, da sich diese Datenstruktur gut für relationale Daten eignet.
# check if lists have the same length
if len(topdiv_h2titles) == len(topdiv_texts) == len(topdiv_absolute_links):
# create
top_section_data = {"DC.title": topdiv_h2titles,
"Text":topdiv_texts,
"DC.source":topdiv_absolute_links,
"DC.date": datetime.today().strftime('%d.%m.%Y') }
else:
print("Die Listen haben nicht dieselbe Länge:")
print(f"Titel: {len(topdiv_h2titles)}; Teaser: {len(topdiv_texts)}; URLS: {len(topdiv_absolute_links)}")
top_section_data = None
top_section_data_df = pd.DataFrame(top_section_data)
top_section_data_df
| DC.title | Text | DC.source | DC.date | |
|---|---|---|---|---|
| 0 | Olympia-Bewerbung | Berlin präsentierte das Bewerbungskonzept BERL... | https://www.berlin.de/rbmskzl/aktuelles/media/... | 29.07.2026 |
| 1 | Ernennung von Sarah Wedl-Wilson zur Kultursena... | Der Regierende Bürgermeister hat die bisherige... | https://www.berlin.de/rbmskzl/aktuelles/presse... | 29.07.2026 |
| 2 | Senat vor Ort in Marzahn-Hellersdorf | Nach gemeinsamer Sitzung tourte der Regierende... | https://www.berlin.de/rbmskzl/aktuelles/media/... | 29.07.2026 |
| 3 | Tag der offenen Tür im Roten Rathaus | Unter dem Motto „Demokratie erleben“ öffnet da... | https://www.berlin.de/offenes-rotes-rathaus | 29.07.2026 |
Aufbauend auf dieser Tabelle könnten wir nun automatisch die Volltexte der Artikel extrahieren, indem wir die gespeicherten URLs automatisch abfragen und den Text extrahieren. Dafür müssen wir auf Methoden des Web-Scraping (siehe folgendes Kapitel „Scraping als Methode zum Korpusaufbau“) zurückgreifen.
4.3.5. Ergebnisse speichern#
Schlussendlich speichern wir die Ergebnisse. Da wir keine Volltexte extrahiert haben und somit nur Metadaten extrahiert haben, speichern wir diese gesammelt in einer Tabelle.
Ergebnis-Ordner und Dateipfad festlegen#
Ordner zum Speichern der Ergebnistabelle festlegen:
output_dir = Path(r"../data")
output_dir.mkdir(parents=True, exist_ok=True)
Dateinamen erstellen:
date = datetime.today().strftime('%Y-%m-%d')
fn = f"{date}_Senatskanzlei_Aktuelles.csv"
fp = output_dir / fn
Speichern der Daten#
top_section_data_df.to_csv(fp, index=False)
print("Datei ", fn, " gespeichert!")
Datei 2026-07-29_Senatskanzlei_Aktuelles.csv gespeichert!