
6.1. 🚀 Massenscraping von Pressemitteilungen#
Feinlernziel(e) dieses Kapitels
Die Lernenden können mit Hilfe eines Jupyter Notebooks Python-Code zur Extraktion des Website-Texts ausführen.
Hinweise zur Ausführung des Notebooks
Dieses Notebook kann auf unterschiedlichen Levels erarbeitet werden (siehe Abschnitt “Technische Voraussetzungen”):
Book-Only Mode: Sie lesen das Notebook hier im “Jupyter Book”, ohne den Code selbst auszuführen.
Cloud Mode: Klicken Sie oben rechts in der Menüleiste auf das Raketen-Symbol 🚀 und wählen Sie “Colab”, um das Notebook auszuführen.
Local Mode: Klicken Sie oben rechts in der Menüleiste auf das Download-Symbol ↓ und wählen Sie “.ipynb”, um das Notebook lokal auszuführen.
6.1.1. Übersicht#
Im Folgenden werden alle Pressemitteilungen der Berliner Staatskanzlei gescraped
Dafür werden folgendene Schritte durchgeführt:
Wir werden die Struktur des Teils der Website untersuchen, der alle Pressemitteilungen enthält.
Wir werden die URL-Links zu allen Pressemitteilungen abrufen.
Abschließend werden wir alle Pressemitteilungen scrapen.
Show code cell content
# 🚀 Install libraries
!pip install requests tqdm lxml beautifulsoup4 pandas itables
Requirement already satisfied: requests in /opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages (2.32.3)
Requirement already satisfied: tqdm in /opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages (4.70.0)
Collecting lxml
Downloading lxml-6.1.1-cp311-cp311-manylinux_2_26_x86_64.manylinux_2_28_x86_64.whl.metadata (3.5 kB)
Requirement already satisfied: beautifulsoup4 in /opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages (4.12.3)
Requirement already satisfied: pandas in /opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages (3.0.5)
Collecting itables
Downloading itables-2.9.1-py3-none-any.whl.metadata (12 kB)
Requirement already satisfied: charset-normalizer<4,>=2 in /opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages (from requests) (3.3.2)
Requirement already satisfied: idna<4,>=2.5 in /opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages (from requests) (3.8)
Requirement already satisfied: urllib3<3,>=1.21.1 in /opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages (from requests) (2.2.2)
Requirement already satisfied: certifi>=2017.4.17 in /opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages (from requests) (2024.8.30)
Requirement already satisfied: soupsieve>1.2 in /opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages (from beautifulsoup4) (2.6)
Requirement already satisfied: numpy>=1.26.0 in /opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages (from pandas) (2.1.1)
Requirement already satisfied: python-dateutil>=2.8.2 in /opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages (from pandas) (2.9.0.post0)
Requirement already satisfied: six>=1.5 in /opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages (from python-dateutil>=2.8.2->pandas) (1.16.0)
Downloading lxml-6.1.1-cp311-cp311-manylinux_2_26_x86_64.manylinux_2_28_x86_64.whl (5.2 MB)
?25l ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0.0/5.2 MB ? eta -:--:--
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 5.2/5.2 MB 237.9 MB/s 0:00:00
?25h
Downloading itables-2.9.1-py3-none-any.whl (1.6 MB)
?25l ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0.0/1.6 MB ? eta -:--:--
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.6/1.6 MB 259.7 MB/s 0:00:00
?25h
Installing collected packages: lxml, itables
?25l
━━━━━━━━━━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━ 1/2 [itables]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 2/2 [itables]
?25h
Successfully installed itables-2.9.1 lxml-6.1.1
Show code cell content
import requests, pathlib, time, re, logging, textwrap, csv
from bs4 import BeautifulSoup
import pandas as pd
from tqdm import tqdm
from itables import show
6.1.2. Abruf und Analyse der Suchseite für Pressemitteilungen#
Wir wissen bereits, dass das Suchmenü auf der Website Berlin.de gezielt die Auswahl der für uns interessanten Abteilungen ermöglicht.

Anschließend können wir mit den ausgewählten Abteilungen und einer leeren Suchanfrage suchen und so alle Pressemitteilungen dieser Abteilungen abrufen:
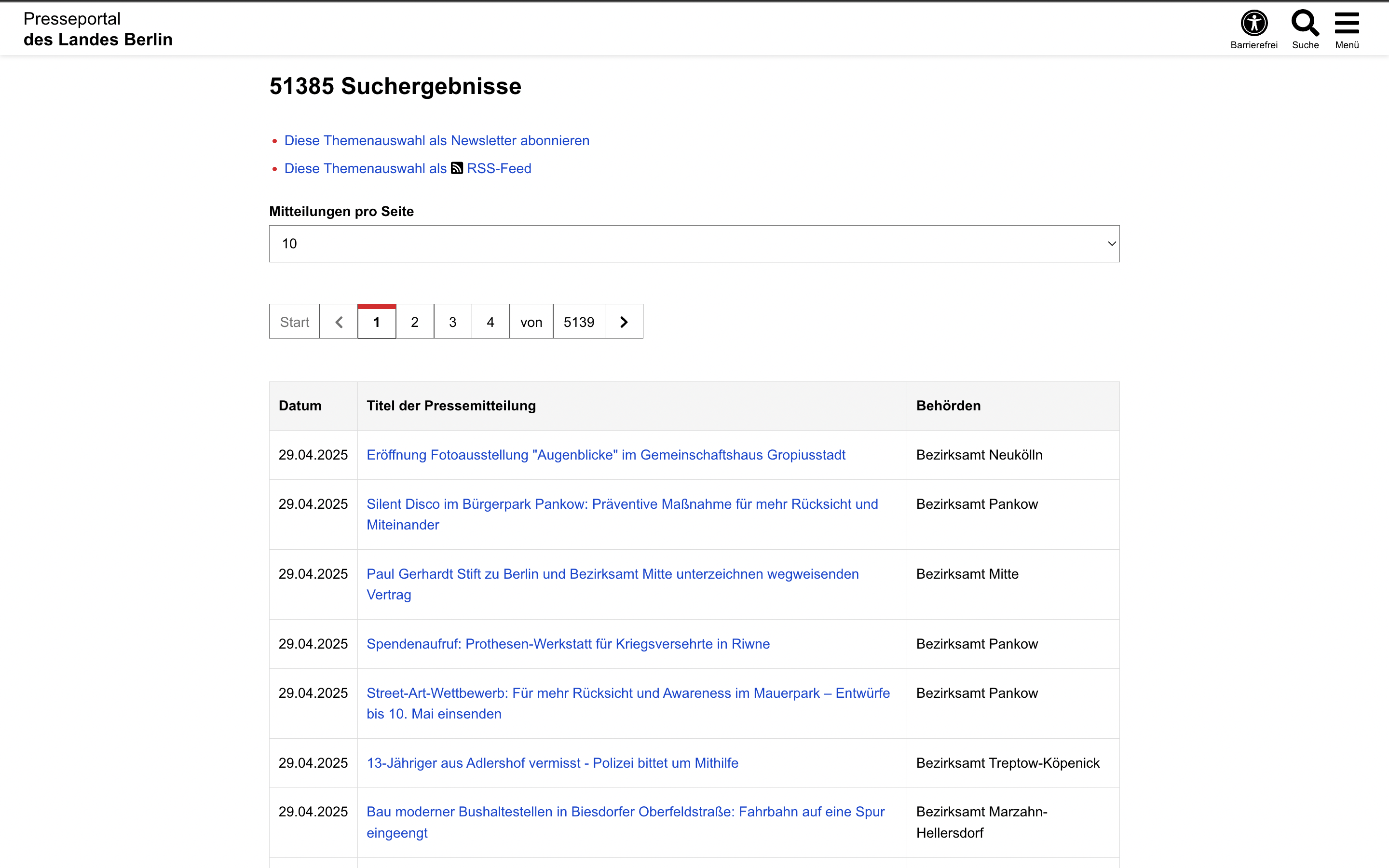
Wir sehen, dass die Links hier in einer Tabelle gespeichert sind. In HTML wird eine Tabelle mit dem <table>-Element dargestellt. Wenn wir den Quellcode dieser Seite betrachten, stellen wir fest, dass sie eine Tabelle enthält, in der alle Links aufgeführt sind:
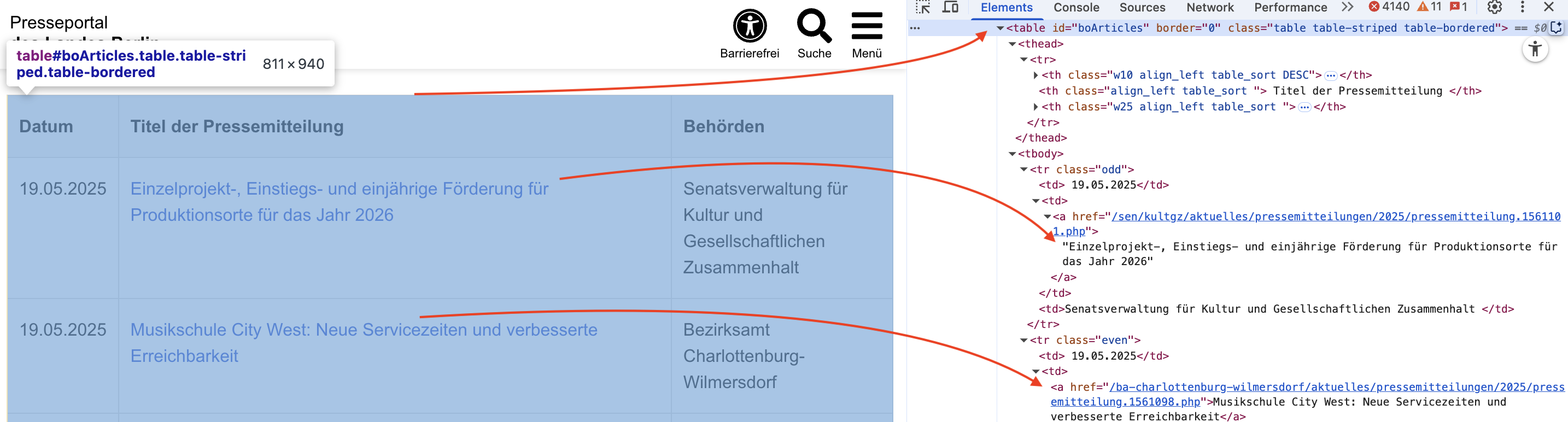
Um diese Links zu durchsuchen, können wir die grundlegenden HTML-Abfragefunktionen der bereits bekannten Bibliothek BeautifulSoup verwenden. Das machen wir im nächsten Abschnitt.
6.1.3. Suchergebnisse scrapen und Pressemitteilungen extrahieren (auf einer Seite):#
Organisation der Ordnerstruktur#
# -- organise data ----------------------------------------------------
FIRST_OUTPUT_PAGE = (
"https://www.berlin.de/presse/pressemitteilungen/index/search/?searchtext=&boolean=0&startdate=&enddate=&alle-senatsverwaltungen=on&institutions%5B%5D=Presse-+und+Informationsamt+des+Landes+Berlin&institutions%5B%5D=Senatsverwaltung+für+Bildung%2C+Jugend+und+Familie&institutions%5B%5D=Senatsverwaltung+für+Finanzen&institutions%5B%5D=Senatsverwaltung+für+Inneres+und+Sport&institutions%5B%5D=Senatsverwaltung+für+Arbeit%2C+Soziales%2C+Gleichstellung%2C+Integration%2C+Vielfalt+und+Antidiskriminierung&institutions%5B%5D=Senatsverwaltung+für+Justiz+und+Verbraucherschutz&institutions%5B%5D=Senatsverwaltung+für+Kultur+und+Gesellschaftlichen+Zusammenhalt&institutions%5B%5D=Senatsverwaltung+für+Stadtentwicklung%2C+Bauen+und+Wohnen&institutions%5B%5D=Senatsverwaltung+für+Mobilität%2C+Verkehr%2C+Klimaschutz+und+Umwelt&institutions%5B%5D=Senatsverwaltung+für+Wirtschaft%2C+Energie+und+Betriebe&institutions%5B%5D=Senatsverwaltung+für+Wissenschaft%2C+Gesundheit+und+Pflege&alle-bezirksamt=on&institutions%5B%5D=Bezirksamt+Charlottenburg-Wilmersdorf&institutions%5B%5D=Bezirksamt+Friedrichshain-Kreuzberg&institutions%5B%5D=Bezirksamt+Lichtenberg&institutions%5B%5D=Bezirksamt+Marzahn-Hellersdorf&institutions%5B%5D=Bezirksamt+Mitte&institutions%5B%5D=Bezirksamt+Neukölln&institutions%5B%5D=Bezirksamt+Pankow&institutions%5B%5D=Bezirksamt+Reinickendorf&institutions%5B%5D=Bezirksamt+Spandau&institutions%5B%5D=Bezirksamt+Steglitz-Zehlendorf&institutions%5B%5D=Bezirksamt+Tempelhof-Schöneberg&institutions%5B%5D=Bezirksamt+Treptow-Köpenick&alle-landesbeauftragte=on&institutions%5B%5D=Beauftragte+des+Senats+für+Integration+und+Migration&institutions%5B%5D=Beauftragter+zur+Aufarbeitung+der+SED-Diktatur&institutions%5B%5D=Bürger-+und+Polizeibeauftragter+des+Landes+Berlin&institutions%5B%5D=Pflegebeauftragte+des+Landes+Berlin&institutions%5B%5D=Landestierschutzbeauftragte&institutions%5B%5D=Landeswahlleitung&bt="
)
DATA_DIR = pathlib.Path("../data")
HTML_DIR = DATA_DIR / "html"
TXT_DIR = DATA_DIR / "txt"
HTML_DIR.mkdir(parents=True, exist_ok=True)
TXT_DIR.mkdir(parents=True, exist_ok=True)
logging.basicConfig(level=logging.INFO, format="%(levelname)s: %(message)s")
Vorbereitung der Funktion, die die HTTP-Anfrage ausführt und die Antwort verarbeitet#
In dieser Code-Zelle unten definieren wir zwei kleine Hilfsfunktionen, die wir später beim Web-Scraping immer wieder verwenden werden.
Wichtig: In dieser Zelle wird noch nichts „gescrapet“ – wir bereiten nur Werkzeuge vor.
1️⃣ get_soup() – Webseiten zuverlässig abrufen
2️⃣ slugify() – Dateinamen aus Text erzeugen
# -- helper -----------------------------------------------------------------
def get_soup(
url: str,
*,
max_retries: int = 3,
sleep_s: float = 10,
) -> BeautifulSoup | None:
"""
Lädt eine Webseite (URL) und gibt den HTML-Inhalt als BeautifulSoup-Objekt zurück.
Warum braucht man das?
- Beim Web-Scraping treten oft temporäre Probleme auf (Netzwerk-Wackler, Server überlastet,
Rate-Limits). Diese Funktion versucht deshalb mehrere Male, eine Seite abzurufen, bevor sie aufgibt.
Parameter
----------
url : str
Die Zieladresse der Webseite.
max_retries : int (Standard: 3)
Wie viele *Versuche insgesamt* sollen gemacht werden, bevor wir aufgeben?
sleep_s : float (Standard: 10)
Wie viele Sekunden warten wir zwischen den Versuchen?
(Das ist höflich gegenüber dem Server und reduziert die Gefahr von Sperren.)
Rückgabewert
------------
BeautifulSoup | None
- BeautifulSoup: wenn der Abruf erfolgreich war (HTTP Status 200)
- None: wenn die Seite dauerhaft nicht verfügbar ist (z.B. 404/410) oder nach allen Versuchen
immer noch kein Erfolg möglich war.
Fehlerlogik (vereinfacht)
-------------------------
- 200 (OK): HTML parsen und zurückgeben.
- 404 (Not Found) / 410 (Gone): Seite existiert nicht (mehr) → sofort None.
- Alles andere (z.B. 500, 503, 429): vermutlich temporär → warten und erneut versuchen.
"""
# Wir wiederholen den Abruf bis zu max_retries Mal.
for attempt in range(1, max_retries + 1):
try:
# HTTP-Request:
# - timeout=20: nicht ewig hängen, sondern nach 20s abbrechen
# - User-Agent: viele Websites blocken "anonyme" Requests; ein klarer User-Agent ist fairer
r = requests.get(
url,
timeout=20,
headers={"User-Agent": "Mozilla/5.0 (QuadrigaScraper/1.0)"},
)
except requests.RequestException as err:
# Netzwerkfehler (z.B. DNS, Timeout, Verbindungsabbruch):
# → wir loggen das und versuchen es nach einer Pause erneut.
logging.warning(
"Netzwerkfehler %s – Versuch %d/%d", err, attempt, max_retries
)
time.sleep(sleep_s)
continue
# Erfolgsfall: HTTP 200 bedeutet "OK", Seite wurde geliefert.
if r.status_code == 200:
# BeautifulSoup baut aus HTML einen parsebaren Baum (z.B. für soup.select, soup.find, ...)
return BeautifulSoup(r.text, "lxml")
# Dauerhafte Fehler: Seite ist nicht da oder wurde entfernt.
# -> Hier bringt erneutes Probieren meistens nichts.
if r.status_code in (404, 410):
logging.info("❌ %s liefert %s – überspringe.", url, r.status_code)
return None
# Alle anderen HTTP-Statuscodes können temporär sein:
# - 429: zu viele Anfragen (Rate Limit)
# - 5xx: Serverfehler
# - 403: evtl. Block/Forbidden (kann auch dauerhaft sein, aber oft lohnt ein Retry)
logging.warning(
"Status %s auf %s – Versuch %d/%d, Wartezeit %ss",
r.status_code, url, attempt, max_retries, sleep_s
)
time.sleep(sleep_s)
# Wenn wir hier landen, sind alle Versuche gescheitert.
logging.error(
"🚨 %s nach %d Versuchen nicht erreichbar – überspringe.", url, max_retries
)
return None
def slugify(text_: str, maxlen: int = 60) -> str:
"""
Erzeugt aus einem beliebigen Text einen „dateinamen-tauglichen“ Slug.
Wozu?
- Wenn wir z.B. eine Headline als Dateiname speichern wollen, dürfen darin keine
Sonderzeichen, Leerzeichen usw. sein. Diese Funktion macht daraus einen sicheren,
kurzen Namen.
Schritte
--------
1) Kleinschreibung
2) Alles, was nicht „Wortzeichen“ ist (Buchstaben/Ziffern/_) → wird durch '-' ersetzt
3) Führende/abschließende '-' entfernen
4) Auf maxlen Zeichen kürzen
5) Falls am Ende nichts übrig bleibt: 'untitled'
Hinweis: Das ist eine „rough“ Slugify-Funktion (ohne perfekte Unicode-Transliteration).
"""
text_ = re.sub(r"\W+", "-", text_.lower()).strip("-")
return text_[:maxlen] or "untitled"
Extrahieren von Pressemitteilungen aus einer Seite mit Suchausgabe#
📄 Eine Ergebnisseite auslesen und Detailseiten speichern#
In dieser Code-Zelle wird eine einzelne Ergebnisseite mit Pressemitteilungen ausgelesen.
Für jede gefundene Tabellenzeile wird die zugehörige Detailseite aufgerufen, der Haupttext extrahiert und lokal gespeichert.
# -- Schritt 1: genau **eine** Ergebnisseite parsen -----------------------
# Wir laden hier bewusst nur *eine* Ergebnisseite der Listenansicht.
# Jede Tabellenzeile auf dieser Seite entspricht einer Pressemitteilung.
search_soup = get_soup(FIRST_OUTPUT_PAGE)
# In der Ergebnisliste steckt jede Pressemitteilung in einer Tabellenzeile (<tr>)
rows = search_soup.select("table tbody tr")
# In dieser Liste sammeln wir später die Metadaten für unser DataFrame
records = []
print(f"Found {len(rows)} rows on the page.")
# -- Schritt 2: Alle Tabellenzeilen durchgehen ---------------------------
# tqdm zeigt einen Fortschrittsbalken an – hilfreich für längere Läufe
for tr in tqdm(rows, desc="Rows"):
# Jede Tabellenzeile besteht aus mehreren Zellen (<td>)
cells = tr.find_all("td")
# Sicherheitscheck:
# Wenn eine Zeile weniger als drei Zellen hat, handelt es sich meist
# um Footer-, Leer- oder Paginierungszeilen → überspringen
if len(cells) < 3:
continue
# --- Spalte 1: Veröffentlichungsdatum -------------------------------
# get_text(strip=True) entfernt Zeilenumbrüche und überflüssige Leerzeichen
date_txt = cells[0].get_text(strip=True)
# --- Spalte 2: Titel + Link zur Detailseite --------------------------
# In der zweiten Zelle befindet sich der klickbare <a>-Link
anchor = cells[1].find("a", href=True)
# Falls kein Link vorhanden ist, können wir diese Zeile nicht weiterverarbeiten
if anchor is None:
continue
# Sichtbarer Titel der Pressemitteilung
title = anchor.get_text(strip=True)
# Der Link ist relativ → wir ergänzen die Basis-URL
pr_url = "https://www.berlin.de" + anchor["href"]
# --- Spalte 3: herausgebende Behörde („Ressort“) ---------------------
ressort = cells[2].get_text(strip=True)
# --- Eindeutige ID aus der URL ableiten ------------------------------
# Beispiel: /pressemitteilung.1570469.php → ID = 1570469
# Diese ID verwenden wir später als Dateinamen
uid = anchor["href"].split("/")[-1].split(".")[-2]
# -- Schritt 3: Detailseite herunterladen -----------------------------
# Wir speichern jede Pressemitteilung lokal:
# - einmal als rohe HTML-Datei
# - einmal als bereinigten Text
html_file = HTML_DIR / f"{uid}.html"
txt_file = TXT_DIR / f"{uid}.txt"
# Idempotenz-Prinzip:
# Wenn die HTML-Datei bereits existiert, laden wir nichts neu herunter.
if not html_file.exists():
# Detailseite abrufen
pr_soup = get_soup(pr_url)
# Rohes HTML speichern (für spätere Nachvollziehbarkeit)
html_file.write_text(str(pr_soup), encoding="utf-8")
# --- Haupttext extrahieren --------------------------------------
# Die Seitenstruktur hat sich über die Jahre geändert.
# Deshalb probieren wir mehrere mögliche Container:
body = (
pr_soup.select_one("#article") or # neues Layout (ca. ab 2024)
pr_soup.select_one("#content") or # älteres Layout
pr_soup # Fallback: ganze Seite
)
# Textinhalt extrahieren:
# - Leerzeichen statt Zeilenumbrüche
# - führende / folgende Leerzeichen entfernen
clean_text = body.get_text(" ", strip=True)
# Bereinigten Text separat speichern
txt_file.write_text(clean_text, encoding="utf-8")
else:
# Falls die Datei schon existiert:
# Text aus der gespeicherten TXT-Datei lesen
clean_text = txt_file.read_text(encoding="utf-8")
# -- Schritt 4: Metadaten für spätere Analyse sammeln -----------------
# Alles landet als Dictionary in der records-Liste
records.append(
dict(
date=date_txt,
ressort=ressort,
title=title,
pr_url=pr_url,
filename_html=html_file.name,
filename_txt=txt_file.name,
# einfache Token-Schätzung über Wortanzahl
n_tokens=len(clean_text.split())
)
)
# Kleine Höflichkeitspause:
# reduziert Serverlast und Risiko von Sperren
time.sleep(0.4)
# -- Schritt 5: Metadaten in ein DataFrame überführen ---------------------
# Aus der Liste von Dictionaries wird ein Pandas-DataFrame
df = pd.DataFrame(records)
# Interaktives Anzeigen der Tabelle
show(df)
Found 10 rows on the page.
Rows: 0%| | 0/10 [00:00<?, ?it/s]
Rows: 10%|█ | 1/10 [00:00<00:07, 1.28it/s]
Rows: 20%|██ | 2/10 [00:01<00:06, 1.30it/s]
Rows: 30%|███ | 3/10 [00:02<00:05, 1.30it/s]
Rows: 40%|████ | 4/10 [00:03<00:04, 1.31it/s]
Rows: 50%|█████ | 5/10 [00:03<00:03, 1.30it/s]
Rows: 60%|██████ | 6/10 [00:04<00:03, 1.27it/s]
Rows: 70%|███████ | 7/10 [00:05<00:02, 1.29it/s]
Rows: 80%|████████ | 8/10 [00:06<00:01, 1.30it/s]
Rows: 90%|█████████ | 9/10 [00:06<00:00, 1.30it/s]
Rows: 100%|██████████| 10/10 [00:07<00:00, 1.30it/s]
Rows: 100%|██████████| 10/10 [00:07<00:00, 1.30it/s]
| Loading ITables v2.9.1 from the internet... (need help?) |
| ⓘdate | ressort | title | pr_url | filename_html | filename_txt | n_tokens |
|---|---|---|---|---|---|---|
| 29.07.2026 | Bezirksamt Friedrichshain-Kreuzberg | Unterzeichnung der Kooperationsvereinbarung Stadtteilarbeit im Bezirk Friedrichshain-Kreuzberg | https://www.berlin.de/ba-friedrichshain-kreuzberg/aktuelles/pressemitteilungen/2026/pressemitteilung.1698445.php | 1698445.html | 1698445.txt | 1552 |
| 29.07.2026 | Bezirksamt Reinickendorf | Migrationsbeirat Reinickendorf veröffentlicht Stellungnahme zum CSD 2026 | https://www.berlin.de/ba-reinickendorf/aktuelles/pressemitteilungen/2026/pressemitteilung.1698444.php | 1698444.html | 1698444.txt | 1030 |
| 29.07.2026 | Bezirksamt Tempelhof-Schöneberg | Start der Wahlwerbung am 2. August 2026: Ordnungsamt kontrolliert Einhaltung | https://www.berlin.de/ba-tempelhof-schoeneberg/aktuelles/pressemitteilungen/2026/pressemitteilung.1698381.php | 1698381.html | 1698381.txt | 967 |
| 29.07.2026 | Bezirksamt Tempelhof-Schöneberg | BSR-Kieztag am 5. August 2026 am Dürerplatz | https://www.berlin.de/ba-tempelhof-schoeneberg/aktuelles/pressemitteilungen/2026/pressemitteilung.1698368.php | 1698368.html | 1698368.txt | 1165 |
| 29.07.2026 | Bezirksamt Steglitz-Zehlendorf | Neuauflage des Hitzeaktionsplans für Steglitz-Zehlendorf | https://www.berlin.de/ba-steglitz-zehlendorf/aktuelles/pressemitteilungen/2026/pressemitteilung.1698357.php | 1698357.html | 1698357.txt | 1131 |
| 29.07.2026 | Bezirksamt Marzahn-Hellersdorf | Katrin Rohnstock über Treuhand-Erfahrungen: Gespräch in der Mark-Twain-Bibliothek in Marzahn-Hellersdorf | https://www.berlin.de/ba-marzahn-hellersdorf/aktuelles/pressemitteilungen/2026/pressemitteilung.1698350.php | 1698350.html | 1698350.txt | 763 |
| 29.07.2026 | Bezirksamt Reinickendorf | Hitzewarnung für Berlin: Hinweise zum Schutz vor Hitze | https://www.berlin.de/ba-reinickendorf/aktuelles/pressemitteilungen/2026/pressemitteilung.1698344.php | 1698344.html | 1698344.txt | 710 |
| 29.07.2026 | Bezirksamt Tempelhof-Schöneberg | Neues aus der Volkshochschule Tempelhof-Schöneberg | https://www.berlin.de/ba-tempelhof-schoeneberg/aktuelles/pressemitteilungen/2026/pressemitteilung.1698282.php | 1698282.html | 1698282.txt | 1076 |
| 29.07.2026 | Bezirksamt Lichtenberg | Lichtenberg investiert rund 4,4 Millionen Euro in leistungsfähige Straßen und barrierefreie Wege | https://www.berlin.de/ba-lichtenberg/aktuelles/pressemitteilungen/2026/pressemitteilung.1698295.php | 1698295.html | 1698295.txt | 1363 |
| 29.07.2026 | Bezirksamt Treptow-Köpenick | Neuer Flyer stärkt den Sprachaustausch: Sprachcafés in Treptow-Köpenick neu aufgelegt | https://www.berlin.de/ba-treptow-koepenick/aktuelles/pressemitteilungen/2026/pressemitteilung.1698285.php | 1698285.html | 1698285.txt | 985 |
Ziel dieser Zelle ist es, strukturierte Textdaten für die anschließende Analyse zu erzeugen.
6.1.4. Massenscraping von Pressemitteilungen#
Implementierung der Logik zum Finden der letzten Seite in der Suchausgabe#
# -- Pagination-Hilfsfunktionen -------------------------------------------
# Diese Funktionen helfen uns dabei,
# 1) die *letzte* verfügbare Ergebnisseite zu finden und
# 2) URLs für beliebige Seitenzahlen korrekt zu erzeugen.
#
# Wichtig: Die Basis-URL enthält bereits alle Suchfilter
# (z.B. Zeitraum, Ressort usw.) als Query-Parameter.
# Diese dürfen beim Blättern NICHT verloren gehen.
SEARCH_ROOT = FIRST_OUTPUT_PAGE # erste Ergebnisseite inkl. aller Filter
def last_page_number() -> int:
"""
Bestimmt die höchste verfügbare Ergebnisseiten-Nummer.
Vorgehen:
- Die erste Suchseite wird geladen.
- Im Navigationsbereich (<nav>) suchen wir gezielt nach dem Link
„zur letzten Seite“.
- Aus dessen URL wird die Seitenzahl extrahiert.
Rückgabewert
------------
int
Nummer der letzten Ergebnisseite (z.B. 5239)
"""
# Erste Ergebnisseite laden
soup = get_soup(SEARCH_ROOT)
# Der Link zur letzten Seite steckt im <li>-Element
# mit der Klasse "pager-skip-to-last"
last_link = soup.select_one("li.pager-skip-to-last a")
if not last_link:
raise RuntimeError(
"Konnte die letzte Seite nicht finden – CSS-Selector prüfen."
)
# href hat typischerweise die Form:
# ".../search/page/5239?<gleiche Filterparameter>"
m = re.search(r"/page/(\d+)", last_link["href"])
if not m:
raise RuntimeError("Seitenzahl nicht im href gefunden.")
return int(m.group(1))
def page_url(page_num: int) -> str:
"""
Erzeugt die URL für eine bestimmte Ergebnisseite.
Idee:
- Wir nehmen die Basis-Such-URL
- ersetzen "/search/" durch "/search/page/<nr>/"
- alle Filter (Query-Parameter) bleiben unverändert erhalten
Parameter
---------
page_num : int
Gewünschte Seitennummer (beginnt bei 1)
"""
if page_num < 1:
raise ValueError("Seitennummern beginnen bei 1.")
return SEARCH_ROOT.replace(
"/search/", f"/search/page/{page_num}/"
)
Vorbereitung der Funktion für das Massenscraping#
Diese Zelle lädt alle Trefferseiten der Pressemitteilungen nacheinander.
Die Detailseiten werden verarbeitet, Texte gespeichert und Metadaten laufend in eine CSV-Datei geschrieben, sodass der Crawl jederzeit sicher unterbrochen und fortgesetzt werden kann.
# Diese Zelle enthält einen „Bulk-Crawler“, der *alle* Ergebnisseiten
# nacheinander verarbeitet und Metadaten schrittweise in eine CSV-Datei schreibt.
META_CSV = DATA_DIR / "metadata.csv"
# Wie viele Datensätze sammeln wir im Speicher,
# bevor wir sie sicher in die CSV-Datei schreiben?
BUFFER_SIZE = 100
def crawl_all_pages(
pages: int | None = None,
sleep_s: float = 0.4,
buffer_size: int = BUFFER_SIZE,
) -> pd.DataFrame:
"""
Crawlt alle Trefferseiten der Pressemitteilungen und speichert Metadaten
inkrementell in einer CSV-Datei.
Zentrale Idee
-------------
- Die Ergebnisseiten werden nacheinander abgearbeitet.
- Für jede Pressemitteilung wird die Detailseite geladen (falls nötig).
- HTML und bereinigter Text werden lokal gespeichert.
- Metadaten werden *schrittweise* in eine CSV geschrieben (Autosave).
Vorteile dieses Ansatzes
------------------------
- Der Crawl kann jederzeit unterbrochen und später fortgesetzt werden.
- Bereits vorhandene Datensätze werden nicht doppelt verarbeitet.
- Auch bei Fehlern geht nur wenig Arbeit verloren.
Parameter
---------
pages : int | None
Wie viele Ergebnisseiten sollen verarbeitet werden?
None bedeutet: automatisch die letzte verfügbare Seite ermitteln.
sleep_s : float
Wartezeit zwischen Detailseiten-Requests (Server-Höflichkeit).
buffer_size : int
Anzahl der Datensätze, die gepuffert werden, bevor sie in die CSV geschrieben werden.
"""
# Wenn keine Seitenzahl angegeben ist, bestimmen wir sie automatisch
if pages is None:
pages = last_page_number()
print(f"→ Letzte Trefferseite lautet {pages}")
# --------------------------------------------------------------
# Vorbereitung der CSV-Datei
# --------------------------------------------------------------
# Erwarteter Spaltenkopf der Metadaten-Datei
EXPECTED_HEADER = [
"DC.identifier", "DC.source", "DC.date", "DC.title",
"DC.publisher", "filename_html", "filename", "n_tokens"
]
# In dieser Menge merken wir uns alle bereits bekannten IDs (UIDs)
# → wichtig, um den Crawl später fortsetzen zu können
existing_uids: set[str] = set()
# Standardannahme: Header fehlt (wird ggf. korrigiert)
need_header = True
# Falls metadata.csv bereits existiert und nicht leer ist:
if META_CSV.exists() and META_CSV.stat().st_size > 0:
# Prüfen, ob der Header schon korrekt vorhanden ist
with open(META_CSV, newline="", encoding="utf-8") as fh:
first_line = fh.readline().strip()
need_header = first_line.split(",") != EXPECTED_HEADER
# Nur wenn ein korrekter Header vorhanden ist,
# lesen wir die bestehenden IDs ein
if not need_header:
with open(META_CSV, newline="", encoding="utf-8") as fh:
reader = csv.DictReader(fh)
# The original code had row["id"] here, but it should be DC.identifier
existing_uids = {row["DC.identifier"] for row in reader}
logging.info(
"⚙️ %d vorhandene Datensätze erkannt.", len(existing_uids)
)
else:
logging.warning(
"☝️ metadata.csv hat noch keinen Header – wird ergänzt."
)
# CSV-Datei im passenden Modus öffnen:
# - append ("a"), wenn sie existiert
# - write ("w"), wenn sie neu ist
mode = "a" if META_CSV.exists() else "w"
csvfile = open(META_CSV, mode, newline="", encoding="utf-8")
writer = csv.DictWriter(csvfile, fieldnames=EXPECTED_HEADER)
# Falls nötig, schreiben wir den Header jetzt
if need_header:
writer.writeheader()
csvfile.flush()
# Puffer für neue Datensätze (Autosave-Mechanismus)
buffer: list[dict] = []
# --------------------------------------------------------------
# Hauptschleife: alle Ergebnisseiten durchlaufen
# --------------------------------------------------------------
for p in tqdm(range(1, pages + 1), desc="Result pages"):
# HTML der aktuellen Ergebnisseite abrufen
list_soup = get_soup(page_url(p))
# Falls die ganze Seite nicht erreichbar ist → überspringen
if list_soup is None:
continue
# Jede Tabellenzeile entspricht einer Pressemitteilung
for tr in list_soup.select("table tbody tr"):
cells = tr.find_all("td")
if len(cells) < 3:
continue # Footer-/Leerzeilen ignorieren
# --- Basis-Metadaten aus der Tabelle -------------------------
date_txt = cells[0].get_text(strip=True)
anchor = cells[1].find("a", href=True)
if anchor is None:
continue
ressort = cells[2].get_text(strip=True)
pr_url = "https://www.berlin.de" + anchor["href"]
# UID aus der URL extrahieren (z.B. pressemitteilung.1570469.php)
uid = anchor["href"].split(".")[-2]
# Bereits bekannte Datensätze überspringen (Resume-Funktion)
if uid in existing_uids:
continue
# --- Dateipfade festlegen -----------------------------------
html_fp = HTML_DIR / f"{uid}.html"
txt_fp = TXT_DIR / f"{uid}.txt"
# --- Detailseite laden --------------------------------------
pr_soup = get_soup(pr_url)
# 404 / 410 → keine Detailseite → kein Datensatz
if pr_soup is None:
continue
# HTML und Text nur neu erzeugen, wenn noch nicht vorhanden
if not html_fp.exists():
html_fp.write_text(str(pr_soup), encoding="utf-8")
body = (
pr_soup.select_one("#article") or
pr_soup.select_one("#content") or
pr_soup
)
clean = body.get_text(" ", strip=True)
txt_fp.write_text(clean, encoding="utf-8")
else:
clean = txt_fp.read_text(encoding="utf-8")
# --- Metadaten-Record bauen ---------------------------------
# Corrected to match EXPECTED_HEADER keys
rec = {
"DC.identifier": uid,
"DC.date": date_txt,
"DC.title": anchor.get_text(strip=True),
"DC.source": ressort,
"DC.publisher": "", # Added, assuming no direct extraction for it
"filename_html": html_fp.name,
"filename": txt_fp.name,
"n_tokens": len(clean.split())
}
buffer.append(rec)
existing_uids.add(uid) # sofort merken (wichtig bei Abbruch)
time.sleep(sleep_s)
# --- Autosave: Puffer in CSV schreiben ----------------------
if len(buffer) >= buffer_size:
writer.writerows(buffer)
csvfile.flush()
buffer.clear()
# Optionales Sicherheits-Flush nach jeder Ergebnisseite
if buffer:
writer.writerows(buffer)
csvfile.flush()
buffer.clear()
# --------------------------------------------------------------
# Aufräumen & Rückgabe
# --------------------------------------------------------------
csvfile.close()
logging.info("✅ Crawl abgeschlossen, CSV geschlossen.")
# CSV erneut einlesen, um direkt im Notebook weiterzuarbeiten
return pd.read_csv(META_CSV, encoding="utf-8")
Massenscraping#
Testlauf mit 3 Seiten:#
# Testlauf mit 3 Seiten
df_test = crawl_all_pages(pages=3)
INFO: ⚙️ 51826 vorhandene Datensätze erkannt.
Result pages: 0%| | 0/3 [00:00<?, ?it/s]
Result pages: 33%|███▎ | 1/3 [00:09<00:18, 9.25s/it]
WARNING: Status 429 auf https://www.berlin.de/ba-treptow-koepenick/aktuelles/pressemitteilungen/2026/pressemitteilung.1698194.php – Versuch 1/3, Wartezeit 10s
Result pages: 67%|██████▋ | 2/3 [00:29<00:15, 15.97s/it]
Result pages: 100%|██████████| 3/3 [00:42<00:00, 14.26s/it]
Result pages: 100%|██████████| 3/3 [00:42<00:00, 14.05s/it]
INFO: ✅ Crawl abgeschlossen, CSV geschlossen.
show(df_test)
| Loading ITables v2.9.1 from the internet... (need help?) |
| ⓘDC.identifier | DC.source | DC.date | DC.title | DC.publisher | filename_html | filename | n_tokens |
|---|---|---|---|---|---|---|---|
| 1571189 | https://www.berlin.de/rbmskzl/aktuelles/pressemitteilungen/2025/pressemitteilung.1571189.php | 18.06.2025 | Mehr Sicherheit für Daten und Digitalisierungsprojekte – der neue Data-Governance-Wegweiser | Presse- und Informationsamt des Landes Berlin | 1571189.html | 1571189.txt | 786 |
| 1571151 | https://www.berlin.de/ba-spandau/aktuelles/pressemitteilungen/2025/pressemitteilung.1571151.php | 18.06.2025 | Aufruf zur Teilnahme: Online-Befragung Spandauer Unternehmen zur Entwicklung eines bezirklichen Wirtschaftsflächenkonzepts gestartet | Bezirksamt Spandau | 1571151.html | 1571151.txt | 713 |
| 1571106 | https://www.berlin.de/ba-marzahn-hellersdorf/aktuelles/pressemitteilungen/2025/pressemitteilung.1571106.php | 18.06.2025 | Marzahn-Hellersdorf sucht freie Räume für bürgerschaftliches Engagement | Bezirksamt Marzahn-Hellersdorf | 1571106.html | 1571106.txt | 671 |
| 1571032 | https://www.berlin.de/ba-lichtenberg/aktuelles/pressemitteilungen/2025/pressemitteilung.1571032.php | 18.06.2025 | 4. Queere Kunst- und Kulturtage in Lichtenberg | Bezirksamt Lichtenberg | 1571032.html | 1571032.txt | 828 |
| 1571030 | https://www.berlin.de/ba-neukoelln/aktuelles/pressemitteilungen/2025/pressemitteilung.1571030.php | 18.06.2025 | Online-Umfrage zur Sauberkeit und Ordnung in Berlin | Bezirksamt Neukölln | 1571030.html | 1571030.txt | 978 |
| 1571042 | https://www.berlin.de/ba-friedrichshain-kreuzberg/aktuelles/pressemitteilungen/2025/pressemitteilung.1571042.php | 18.06.2025 | Lesung von Mareike Barmeyer mit „Lauf, Mama, lauf! Geschichten mit Kindern“ in der Bezirkszentralbibliothek | Bezirksamt Friedrichshain-Kreuzberg | 1571042.html | 1571042.txt | 1524 |
| 1571021 | https://www.berlin.de/ba-steglitz-zehlendorf/aktuelles/pressemitteilungen/2025/pressemitteilung.1571021.php | 18.06.2025 | 24. öffentliche Sitzung des Ausschusses für Gebäude, Wirtschaft, Inklusion, Verwaltungsmodernisierung, Digitalisierung | Bezirksamt Steglitz-Zehlendorf | 1571021.html | 1571021.txt | 703 |
| 1570984 | https://www.berlin.de/ba-spandau/aktuelles/pressemitteilungen/2025/pressemitteilung.1570984.php | 18.06.2025 | Presseeinladung: Hissen der Prideflagge am 09.07.2025 vor dem Rathaus Spandau | Bezirksamt Spandau | 1570984.html | 1570984.txt | 633 |
| 1571001 | https://www.berlin.de/ba-friedrichshain-kreuzberg/aktuelles/pressemitteilungen/2025/pressemitteilung.1571001.php | 18.06.2025 | JazzOrchester X-berg (JOX) gewinnt 1. Platz beim Deutschen Orchesterwettbewerb 2025 | Bezirksamt Friedrichshain-Kreuzberg | 1571001.html | 1571001.txt | 1493 |
| 1570968 | https://www.berlin.de/ba-treptow-koepenick/aktuelles/pressemitteilungen/2025/pressemitteilung.1570968.php | 18.06.2025 | Sommerzeit ist Badezeit: Der FEZ-Badesee startet in die Saison | Bezirksamt Treptow-Köpenick | 1570968.html | 1570968.txt | 944 |
| (51,846 more rows not shown) | |||||||
Alle Seiten crawlen:#
# Achtung: Das kann > 1 Stunde dauern und tausende Dateien erzeugen!
# Alle Seiten crawlen
df_all = crawl_all_pages(pages=None) # None → auto-detect
df_all.head()
Hilfscode zum Entfernen unnötiger Teile des HTML-Textes
Show code cell content
## Hilfscode zum Entfernen unnötiger Teile des HTML-Textes
BACKUP_DIR = DATA_DIR / "txt_backup" # Sicherheitskopien
BACKUP_DIR.mkdir(exist_ok=True)
def extract_release(soup: BeautifulSoup) -> str | None:
"""Gibt den bereinigten Text einer Pressemitteilung zurück (oder None)."""
h1 = soup.select_one("#layout-grid__area--herounit h1, h1.title")
main = soup.select_one("#layout-grid__area--maincontent")
if not main:
return None
title = h1.get_text(" ", strip=True) if h1 else ""
body = main.get_text(" ", strip=True)
# Doppelte Überschrift am Anfang entfernen
if body.lower().startswith(title.lower()):
body = body[len(title):].lstrip()
return (title + "\n\n" + body).strip()
changed = skipped = failed = 0
for html_fp in tqdm(sorted(HTML_DIR.glob("*.html")), desc="Rebuild"):
soup = BeautifulSoup(html_fp.read_text(encoding="utf-8"), "lxml")
text = extract_release(soup)
if text is None:
failed += 1
logging.warning("⚠️ %s: kein maincontent-Div gefunden", html_fp.name)
continue
txt_fp = TXT_DIR / f"{html_fp.stem}.txt"
if txt_fp.exists() and txt_fp.read_text(encoding="utf-8").strip() == text:
skipped += 1
continue
# Sicherheitskopie der alten Datei
if txt_fp.exists():
txt_fp.rename(BACKUP_DIR / txt_fp.name)
txt_fp.write_text(text, encoding="utf-8")
changed += 1
print(f"✔️ {changed:,} Dateien bereinigt – {skipped:,} bereits ok – "
f"{failed:,} ohne passenden Layout-Block")
6.1.5. Ergebnisse#
Der Dataframe ‘df_all’ und die Datei metadata.csv enthalten nun die Metadaten für das Pressemitteilungskorpus, während der Ordner txt die Texte der Pressemitteilungen enthält.
Korpusumfang (23. 06. 2025)#
Pressemitteilungen: ≈ 51 800
Zeitspanne: 2011 – 2025
Ø Länge: 430 Tokens (Median 394)
Sie können nun mit computergestützten Methoden untersucht werden.
6.1.6. Zusammenfassung des technischen Workflow#
Filter setzen im Online‑Formular → über die Checkboxen werden gezielt alle Institutionen der Berliner Exekutive angehakt (Senatsverwaltungen, Bezirksämter und Landesbeauftragte); zusammen mit einer leeren Suchanfrage liefert die Suche so sämtliche Pressemitteilungen dieser Institutionen. Die vollständige Such‑URL inklusive aller Filter ist in der Notebook‑Konstante
FIRST_OUTPUT_PAGEhinterlegt (die im Pagination‑Code alsSEARCH_ROOTweiterverwendet wird).Letzte Ergebnisseite ermitteln via CSS‑Selektor
li.pager-skip-to-last a(Stand Juni 2025: Seite 5239).Pagination ablaufen
Trefferzeilen auslesen (
table tbody tr).Detailseiten abrufen; Haupttext steckt verlässlich in
#layout-grid__area--maincontent(Fallback:#articleoder#content).HTML + bereinigter Plain‑Text unter
data/html/<id>.htmlbzw.data/txt/<id>.txtspeichern.Metadaten (Datum, Titel, Ressort, Dateinamen, Token‑Zahl) inkrementell in
data/metadata.csvanhängen (Autosave alle 100 Datensätze).
Resume‑Fähigkeit: Vor jedem Lauf werden vorhandene UIDs aus der CSV eingelesen → keine Dubletten, unterbrochene Crawls lassen sich fortsetzen.
Hinweis
404‑Seiten werden nach drei Fehlversuchen übersprungen und im Log markiert.