6.1. Datenstruktur#
Die Veränderung von Datensätzen oder einzelnen Datenpunkten wird als Datenaufbereitung bezeichnet. Diese Aufbereitung oder Bereinigung kann in Form einer einfachen Abfrage an das System der Datenbankverwaltung erfolgen, in der nur bestimmte Daten zurückgegeben werden sollen. Außerdem fällt hierunter das gezielte Anpassen und Verändern von einzelnen Teilmengen des Datensatzes (Zehnder, 1987). Dieser Prozess ist ein entscheidender Bestandteil, um die Qualität und den Aufbau von Datensätzen zu evaluieren und zu verbessern. Nur durch eine gezielte Aufbereitung können aus Rohdaten nützliche Informationen gewonnen werden. Dafür ist das Erzeugen einer schlüssigen Datenstruktur von besonderer Bedeutung, denn nur so kann mit den Daten einfach und effektiv gearbeitet werden.
Die Struktur eines Datensatzes prägt maßgeblich dessen maschinelle Lesbarkeit und Auswertungsmöglichkeiten. Für eine effiziente Datenaufbereitung bedarf es eines gut strukturierten Datensatzes. Da Datensätze in der Regel sehr viele Daten enthalten, gilt es zuerst zu klären, worauf bei einer guten Datenorganisation und -strukturierung geachtet werden muss.
6.1.1. Datenorganisation#
Für eine gute Datenorganisation ist ein Kriterium elementar: Die Konsistenz. Denn Konsistenz innerhalb sowie über alle Datensätze hinweg spielt im Kontext der Verknüpfbarkeit von Datensätzen eine entscheidende Rolle (Broman and Woo, 2018, Groves and Harris-Kojetin, 2017). Wenn in unterschiedlichen Datensätzen verschiedene Informationen zu Personen gesammelt werden, kann eine effiziente Verknüpfung nur über eine in allen Datensätzen vorhandene konsistente Variable gesetzt werden. Diese Variable sollte im besten Fall einzigartig sein und eine Person klar identifizieren können. (Groves and Harris-Kojetin, 2017) zeigen die Wichtigkeit dieser Konsistenz am Beispiel der Namensgebung auf: Wenn die Person Dr. Max Tom Mustermann in verschiedenen Datensätzen mal als „Max Mustermann“ oder „Dr. Mustermann“ oder auch „Max Tom Mustermann“ abgespeichert wird, ist eine simple Verknüpfung der Informationen aus den Datensätzen mittels des Namens einer Person nicht möglich. Zudem ist zu beachten, dass sich Namen doppeln können und es sich hier nicht um eine einzigartige Variable handelt. Hier müssten weitere Variablen (z.B. Adresse, Ausweisnummer) in Kombination verwendet werden, um ein Individuum klar zu identifizieren und dessen Informationen zu aggregieren (Groves and Harris-Kojetin, 2017). Alternativ lassen sich Identifikationsnummern als eindeutige Variablen für Personen verwenden. Dies könnten beispielsweise die Steuer-ID oder Sozialversicherungsnummer, aber auch eine ORCID sein (s. Abschnitt 5.2. Persistent Identifier).
Außerdem sollten Sie für eine höhere Konsistenz Standardlösungen für verschiedene Szenarien entwerfen. Beispielsweise sollten fehlende Werte immer durch die gleiche Bezeichnung (z.B. „N/A“) kenntlich gemacht werden. Somit enthält die Datei auch keine leeren Zellen, welches bei der Auswertung ansonsten zu Problemen führen kann. Zudem sollten Sie Formate wie beispielsweise das Format der Datumsanzeige fest vergeben und diese immer einhalten (z.B. nach ISO 8601: YYYY-MM-DD).
Im Kontext der Datenorganisation ist es zudem ratsam, sich mit der Normalisierung von Datenbanken auseinanderzusetzen. Die Normalisierung von Datenbanken zielt darauf ab, Redundanzen zu minimieren und die Datenintegrität der Daten zu verbessern. Dies wird erreicht, indem die Daten in kleinere, gut strukturierte Tabellen aufgeteilt werden, die durch Beziehungen miteinander verbunden sind. Hierdurch wird jede Information nur einmal abgespeichert. Durch die Normalisierung können Probleme beim Einfügen, Löschen und Aktualisieren von Daten in der Datenbank vermieden werden, was dazu beiträgt, Fehlinformationen in der Datenbank zu vermeiden und die Konsistenz der Daten zu gewährleisten (Codd, 1971, Khodorovskii, 2002).
Beispielhafte simple Form der Datennormalisierung:
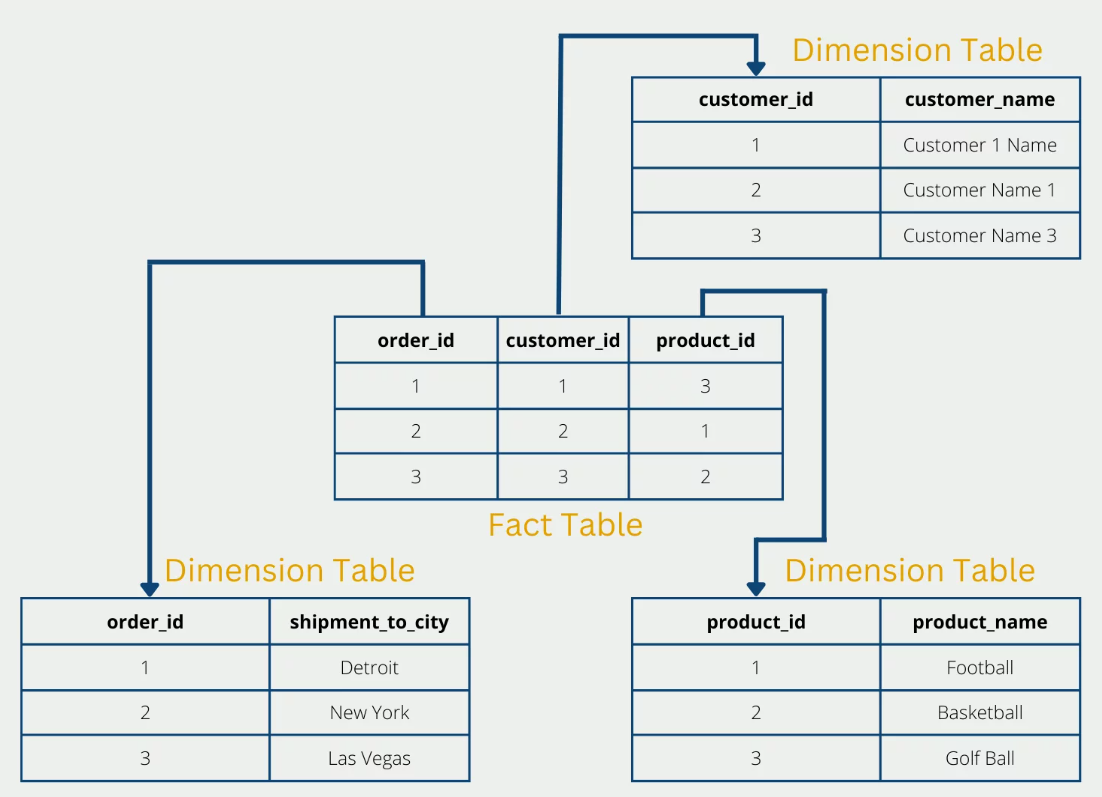
Fig. 6.2 Datennormalisierung nach Niklas Lang.#
Bildquelle: (Lang, 2023)
Weitere Informationen
Weitere Informationen erhalten Sie im Blog Data Base Camp, von dem wir die obige Grafik nachgenutzt haben.
6.1.2. Tidy-Data-Struktur#
Eine sinnvolle Struktur für Ihre Daten ist unerlässlich. Ein weitverbreiteter Standard für diese Struktur setzt das sogenannte „Tidy Dataset“ (Wickham, 2014). Ein Datensatz wird als „Tidy“ bezeichnet, wenn er folgende Struktur erfüllt:
Jede Variable ist eine Spalte
Jede Beobachtung ist eine Zeile
jeder einzelne Wert (Datenpunkt) wird einer Variable und einer Beobachtung zugeordnet.
Nach dieser Struktur enthält jede Zelle exakt einen Wert und ist klar einer einzigen Variable zuzuordnen. Es entsteht ein rechteckiges Layout. Eine saubere Datei enthält nur eine einzige ausgefüllte Tabelle. Außerdem ist in der Raw-Data Datei auf jegliche Formen von optischen Hervorhebungen (z.B. Fettdruck, farbliche Markierungen, etc.) zu verzichten (Broman and Woo, 2018, Wickham, 2014). Wenn Sie Berechnungen auf Basis der Tabellendaten durchführen möchten, sollte dies nie innerhalb der Raw-Data Datei erfolgen (so zu sehen in Abb. 6.3 Zeile 9).
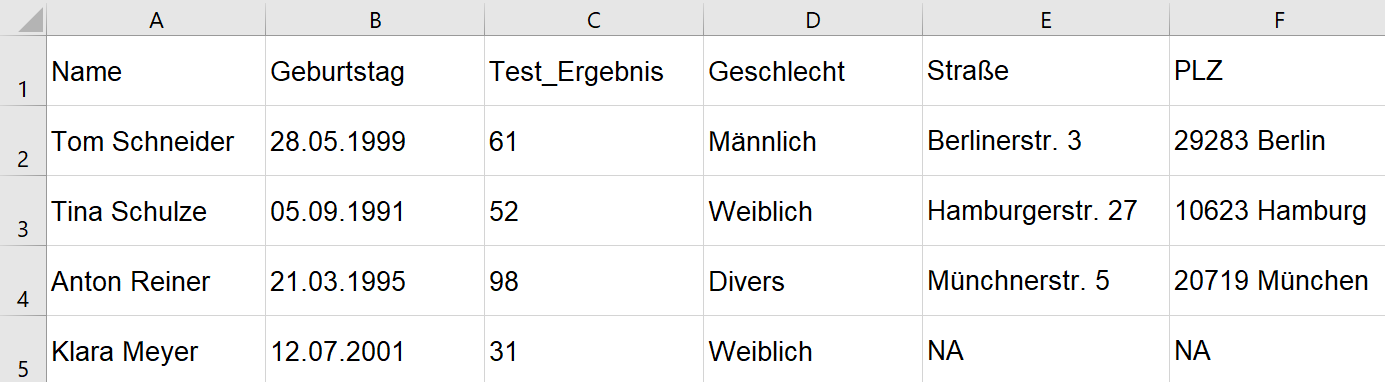
Fig. 6.3 Beispiel für eine gute Tidy-Data-Struktur.#
Durch Einhaltung dieser Struktur entsteht eine Tabelle, die eine schnelle, einfache und vor allem konsistente Datenaufbereitung und -auswertung ermöglicht (Broman and Woo, 2018, Wickham, 2014). In der oben zu sehenden Abbildung 6.2 ist ein Beispiel für eine gut strukturierte Tabelle zu sehen. In der folgenden Abbildung 6.3 ist ein Negativbeispiel zu sehen.
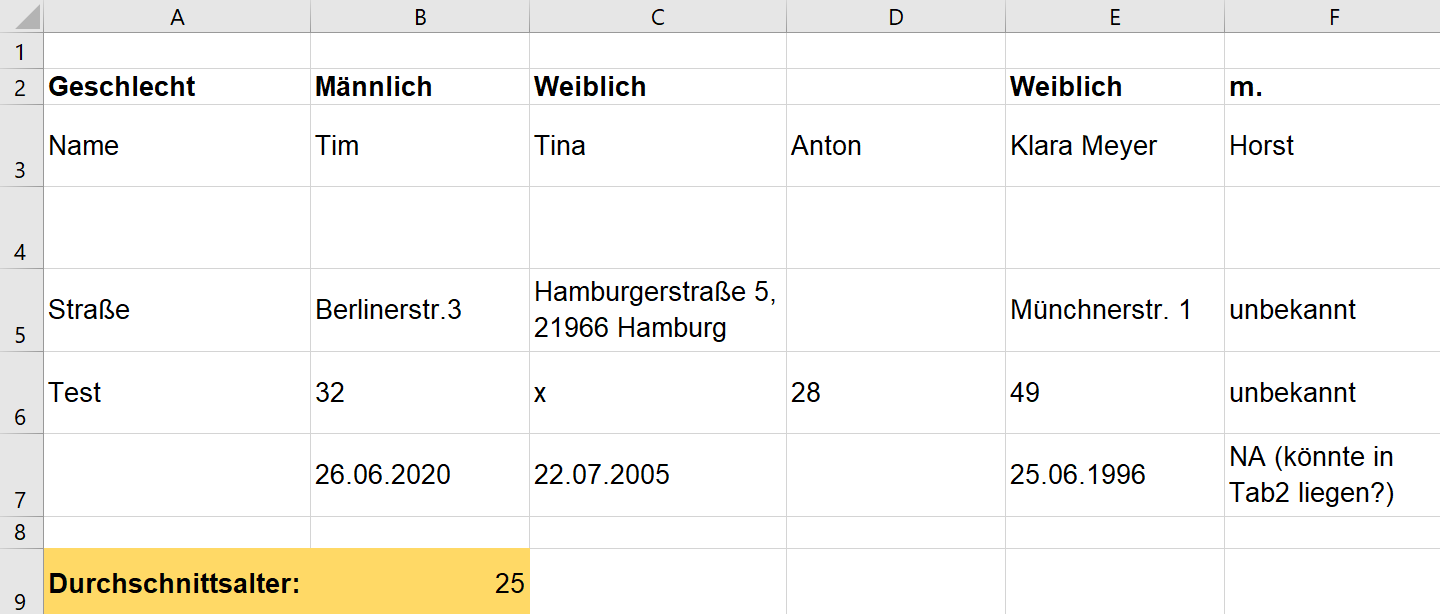
Fig. 6.4 Dieses Beispiel zeigt keine Tidy-Data-Struktur.#
Quiz
Die oben abgebildete Raw-Data-Tabelle (Abbildung 6.3) weist mehrere Mängel auf und entspricht nicht den Maßstäben einer Tidy-Data-Struktur. Können Sie die Fehler benennen?
Lösung
(1) Inkonsistenz
(2) Zellen enthalten mehr als nur einen Wert
(3) Leere Zellen/ Zellen enthalten keinen Wert
(4) Variablen sind nicht spaltenweise angeordnet
(5) Fehlende Bezeichnungen für Variablen
(6) Es werden Berechnungen durchgeführt
(7) Es werden optische Hervorhebungen verwendet
Nach Wickham (2014) sind die häufigsten Fehler im Aufbau von Datensätzen folgende:
Spaltenüberschriften sind keine vernünftigen Variablennamen sondern numerische Werte.
Mehrere Variablen werden in einer Spalte gespeichert.
Variablen werden sowohl in Spalten als auch in Zeilen gespeichert.
Verschiedene Beobachtungseinheiten (z.B. Kilo/Pfund/Unze) werden unter derselben Variable gespeichert.
Eine einzelne Beobachtung wird wiederholt in mehreren Datensätzen gespeichert.
Nun stellt sich bei Ihnen sicherlich die Frage, wie es um unsere Tabelle des Statistischen Bundesamtes steht. Weist dieses eine vorbildliche Struktur auf? Diese Frage wird in der folgenden Lerneinheit Übung: Arbeiten mit CSV-Dateien in R beantwortet.
Literatur
Broman, K. W., & Woo, K. H. (2018). Data organization in spreadsheets. The American Statistician, 72(1), 2–10. URL: https://doi.org/10.1080/00031305.2017.1375989, doi:10.1080/00031305.2017.1375989
Codd, E. F. (1971). Further normalization of the data base relational model. Research Report / RJ / IBM / San Jose, California, RJ909. URL: https://api.semanticscholar.org/CorpusID:45071523
Groves, R. M., & Harris-Kojetin, B. A. (Eds.) (2017 , December). Federal Statistics, Multiple Data Sources, and Privacy Protection: Next Steps. Washington, D.C.: National Academies Press.
Khodorovskii, V. V. (2002). On normalization of relations in relational databases. Programming and Computer Software, 28(1), 41–52. URL: https://doi.org/10.1023/A:1013759617481, doi:10.1023/A:1013759617481
Lang, N. (2023 , May). What is the Normalization of databases? URL: https://databasecamp.de/en/data/normalization
Wickham, H. (2014 , September). Tidy Data. Journal of Statistical Software, 59, 1–23. URL: https://doi.org/10.18637/jss.v059.i10, doi:10.18637/jss.v059.i10
Zehnder, C. A. (1987). Datenmanipulation. Informationssysteme und Datenbanken (pp. 110–159). Wiesbaden: Vieweg+Teubner Verlag.