
5.1. Semantische Felder, Häufigkeitsanalyse und Visualisierung#
5.1.1. Forschungsfrage und Operationalisierung#
In der Korpusanalyse kehren wir wieder zu unserer Fragestellung und deren Operationalisierung zurück. Unsere Fragestellung lautet:
Forschungsfrage
Lassen sich in der deutschsprachigen Literatur des 19. Jahrhunderts Reaktionen auf die zunehmende Luftverschmutzung durch die Industrialisierung ausmachen?
Gemäß der Operationalisierung ist die Analyse zweigeteilt. Zum einen wird untersucht, wie häufig Luft thematisiert wird. Dafür werden die Häufigkeiten des semantisches Felds “Luft” im Korpus errechnet und die Entwicklung wird dargestellt. Zum anderen wird untersucht, auf welche Art und Weise Luft semantisiert wird, indem syntaktische N-Grams (im speziellen Adjektiv-Substantiv-Paare) extrahiert und die Häufigkeiten errechnet werden. So lässt sich nachvollziehen, ob sich die häufigsten Adjektive über die Zeit verändern. Die zweite Analyse wird in Kapitel Syntaktische N-Gramme eingeführt.
5.1.2. Das semantische Feld “Luft”#
Erläuterung: Semantisches Feld#
Die Grundlage unserer Analyse besteht darin, die Textstellen zu identifizieren, in denen Luft eine Rolle spielt. Das ist zum Beispiel bei der bloßen Erwähnung von Luft der Fall. Uns interessiert jedoch nicht Luft als Einzelwort, sondern als ganzer Themenkomplex. Deshalb erstellen wir eine Liste von Wörtern, die inhaltlich eng mit “Luft” verwandt sind – ein sogenanntes semantisches Feld. Ein semantisches Feld ist eine Gruppe von Wörtern, die zum selben Bedeutungsbereich gehören – im Fall von “Luft” beispielsweise “Atmosphäre”, “Stickluft” oder “Abgas”. Bei der Erstellung eines semantischen Felds ist es wichtig, dass möglichst alle und nur die Textstellen erfasst werden, in denen Luft und verwandte Wörter erwähnt werden. Da die Wörter losgelöst von ihrem Kontext analysiert werden, sollten sie so gewählt sein, dass sie sich ausschließlich auf Luft beziehen.
Erstellung des semantischen Felds#
Da Large Language Models sehr gut dazu in der Lage sind, semantisch ähnliche Wörter zu erzeugen, haben wir das semantische Feld mit Hilfe des Chatbots Claude erstellt.
Spezifikation zur Claude-Nutzung
Verwendetes Claude Modell: Opus 4.5
Prompt ausgeführt am: 26.01.2026
Prompt: Du bist eine Digital Humanities-Forscherin mit Expertise im Bereich der Computerlinguistik. Du verfügst über umfassende Kenntnisse im Bereich der Semantik und des Text und Data Mining. Bitte erstelle ein semantisches Feld zum Thema “Luft”. Die Sprache ist deutsch. Bedingungen für die Wörter des semantischen Feldes sind.
die Wörter sollen Substantive sein;
Komposita sind erlaubt;
die Wörter sollen sich am historischen Sprachgebrauch des 19. Jahrhunderts orientieren;
die Wörter sollen spezifisch für den Kontext “Luft” sein;
die Wörter sollen nicht mehrdeutig sein, also nach Möglichkeit nicht in anderen semantischen Kontext vorkommen.
Bitte tue dasselbe für “gute Luft” und “schlechte Luft”.
Diesen Prompt haben wir zweimal in unterschiedlichen Chats ausgeführt und als Resultat eine Liste von 112 Nomen erhalten. Diese haben wir manuell gefiltert: Wörter, die rein auf den Geruch bezogen sind wie z.B. “Fäulnisgeruch” oder “Pestgeruch” wurden entfernt, genau so wie Wörter, die zu generell waren oder die keinen direkten Bezug zu “Luft” hatten wie etwa “Dumpfheit”. Nach der Filterung bestand die Liste noch aus 96 Wörtern.
Zusätzlich sind wir vom Korpus ausgegangen und haben mit Hilfe von AntConc, einem Korpusanalyse-Programm, alle Komposita, die als Erstglied “Luft” haben, extrahiert. Mit dieser Methode konnten wir noch 31 Nomen hinzufügen, sodass unsere finale Liste aus insgesamt 127 Nomen bestand. Die Liste ist hier in GitHub einsehbar.
5.1.3. Häufigkeit als Analysemethode#
Warum die Häufigkeit analysieren?#
Die Analyse von Worthäufigkeiten ist sowohl in der Korpuslinguistik als auch in den Digital Humanities weit verbreitet. Für die Analyse von Inhaltswörtern (Nomen, Verben, Adjektive, Adverben) wird angenommen, dass ein hohes Vorkommen mit der Wichtigkeit der Wörter im Text korreliert. Besonders bei einem Vergleich von zwei oder mehr Texten ist die Häufigkeitsanalyse sinnvoll. Denn der Vergleich wird so quantifizierbar und wir können eine Aussage darüber treffen, ob eine Veränderung zufällig oder systematisch ist.
Die Häufigkeit eines semantischen Felds wird erhoben, indem pro Text gezählt wird, wie viele Wörter Teil des semantischen Felds sind. Da die Wörter in der Grundform angegeben sind, werden sie mit den Lemmata im Text verglichen. Die Anzahl der Wörter nennt sich absolute Häufigkeit.
Beispiel
Text: Die Luft war rein, eine klare Winterluft. Kein Nebel war zu sehen, eine leichte Brise wehte.
Lemmatisierter Text: der Luft sein rein , ein klar Winterluft . kein Nebel sein zu sehen , ein leicht Brise wehen .
Semantisches Feld Luft, Winterluft, Nebel, Brise
Häufigkeitsanalyse:
Wort |
Häufigkeit |
|---|---|
Luft |
1 |
Winterluft |
1 |
Nebel |
1 |
Brise |
1 |
Absolute Häufigkeit: 4
Vergleichbarkeit von Häufigkeiten#
Für die Vergleichbarkeit von Worthäufigkeiten in Texten ist wichtig, dass die Texte auch ansonsten vergleichbar sind. Stammen die Texte z. B. aus unterschiedlichen Zeiträumen müssten ggf. zeitspezifische semantische Felder erstellt werden, um dem Sprachwandel Rechnung zu tragen. Auch sollten die Texte ähnlich lang sein, sodass eine erhöhte Häufigkeit tatsächlich auf eine erhöhte Wichtigkeit zurückgeführt werden kann. Wenn Texte verschieden lang sind, sollten die Häufigkeiten normalisiert werden, das heißt sie werden in Bezug zur Textlänge gesetzt. Dafür wird die absolute Häufigkeit durch die Textlänge dividiert, daraus ergibt sich die relative Häufigkeit. Die relative Häufigkeit des semantischen Felds “Luft” kann als Anteil der Luftwörter am Gesamttext gesehen werden.
Beispiel
Der Beispieltext A besteht aus insgesamt 69 Wörtern, davon sind 4 Wörter in dem semantischen Feld “Luft” vorhanden. Daraus ergibt sich folgende Rechnung:
\( f = {4 \over 69} = {0.05797101449} \)
Das heißt: Jedes zwanzigste Wort im Text steht im Zusammenhang mit Luft.
Der Beispieltext B besteht aus insgesamt 200 Wörtern, davon sind 4 Wörter in dem semantischen Feld “Luft” vorhanden. Daraus ergibt sich folgende Rechnung:
\( f = {4 \over 200} = {0.02} \)
Das heißt: Jedes fünfzigste Wort im Text steht im Zusammenhang mit Luft.
Obwohl in beiden Texten die absolute Häufigkeit gleich ist (4 Wörter des Felds), ist anzunehmen, dass Luft in Beispieltext A eine größere Rolle spielt als in Beispieltext B, da die relative Häufigkeit für A höher ist als für B.
Analyse des gesamten Korpus#
Um den Verlauf nachzuvollziehen, wird für jeden Text im Korpus die relative Häufigkeit des semantischen Felds “Luft” berechnet und in einer Tabelle gespeichert. Die Häufigkeiten können dann über die Zeit verglichen werden, sodass sich ablesen lässt, ob im Laufe der Zeit weniger, mehr oder gleich viel über Luft gesprochen wird. Als Zeitangabe steht dabei für jeden Text nur das Publikationsjahr zur Verfügung – ein genaueres Datum (Monat oder Tag) liegt nicht vor. Dieses Jahr führen wir als ganze Zahl in der Spalte DC.date (dem Dublin-Core-Feld für das Erscheinungsdatum).
Auszug aus der Analysetabelle für Korpus I
lastname |
firstname |
title |
DC.date |
total_count_tokens |
total_count_semantic_field |
relative_frequency |
|---|---|---|---|---|---|---|
Mörike |
Eduard |
Aus dem Gebiete der Seelenkunde |
1861 |
596 |
2 |
0.33557 |
von Hofmannsthal |
Hugo |
Das Dorf im Gebirge |
1896 |
1270 |
4 |
0.314961 |
Willkomm |
Ernst |
Erzählungen eines Wattenschiffers |
1854 |
7083 |
20 |
0.282366 |
Seidl |
Johann Gabriel |
Das goldene Ringlein |
1842 |
5855 |
15 |
0.256191 |
von Eichendorff |
Joseph |
Eine Meerfahrt |
1835 |
23279 |
55 |
0.236264 |
von Sacher-Masoch |
Leopold |
Der Capitulant |
1875 |
20544 |
41 |
0.199572 |
Hinweis: In der Spalte DC.date steht für jeden Text nur das Publikationsjahr als ganze Zahl (z.B. 1861), da kein genaueres Datum vorliegt.
Visuelle Darstellung als Streudiagramm#
Als Resultat erhalten wir pro Korpus 450 Datenpunkte, für jeden Text einen, die gleichmäßig über die Zeit verteilt sind. Ein Datenpunkt ist dabei ein einzelner Messwert – genauer: ein Wertepaar –, der zu genau einem Text gehört: in unserem Fall die relative Häufigkeit des semantischen Felds „Luft“ in diesem Text zusammen mit dem Jahr seiner Veröffentlichung. Da unser Korpus aus 450 Texten besteht, ergeben sich also 450 solcher Datenpunkte. Diese Datenpunkte lassen sich auf unterschiedliche Art und Weise darstellen. Wir sind zum einem daran interessiert, ob sich eine Entwicklung abzeichnet, dafür müssen die Datenpunkte über Zeit angeordnet werden. Zum anderen wollen wir ablesen können, in welchen Texten Luft besonders häufig thematisiert wird, da diese möglicherweise wegweisend gewesen sein könnten. Die Datenpunkte sollen also nicht pro Jahr oder Dekade aggregiert werden, sondern jeder Text soll einzeln erkennbar sein. Dies lässt sich besonders gut durch ein Streudiagramm darstellen. Bei einem Streudigramm wird ein Text in Abhängigkeit seines X- und Y-Wertes als ein Punkt im Koordiantenkreuz dargestellt. Der X-Wert ist in unserem Fall das Jahr der Veröffentlichung, der Y-Wert ist die relative Häufigkeit.
Auf einem Streudiagramm lassen sich allerdings nicht sofort Entwicklungen ablesen. Um diesen Nachteil beizukommen, lässt sich mittels linearer Regression eine Regressionsgerade oder sogenannte Trend-Linie berechnen. Die Trend-Linie soll die Datenpunkte möglichst gut beschreiben, das heißt, sie soll möglichst nah an allen Punkten vorbeilaufen. Je nachdem, ob die Gerade steigt oder fällt, ist eine Zu- oder Abnahme des semantischen Felds Luft zu erkennen.
Beispiel: Trend-Linie in einem alltäglichen Kontext
Das Prinzip lässt sich an einem alltäglichen Beispiel veranschaulichen: Wir befragen mehrere Personen, wie viele Stunden sie für eine Klausur gelernt haben, und tragen für jede Person die Lernzeit (X-Achse) gegen die erreichte Punktzahl (Y-Achse) in ein Streudiagramm ein – jeder Punkt ist eine Person. Die Punkte liegen nicht exakt auf einer Linie (wer gleich lange lernt, erreicht nicht zwingend dieselbe Punktzahl), doch es zeichnet sich ein Muster ab: Mehr Lernzeit geht tendenziell mit einer höheren Punktzahl einher. Die Regressionsgerade ist die eine Linie, die dieses Gesamtmuster am besten zusammenfasst. Ihre Steigung gibt an, wie stark der Zusammenhang ist – hier etwa, um wie viele Punkte das Ergebnis im Schnitt steigt, wenn eine Stunde mehr gelernt wird. Eine steigende Gerade zeigt dabei einen positiven Zusammenhang, eine fallende einen negativen, eine waagerechte keinen.
In unserer Analyse übernimmt das Jahr der Veröffentlichung die Rolle der Lernzeit und die relative Häufigkeit des semantischen Felds „Luft” die Rolle der Punktzahl.
In folgendem Beispiel wurden vier Texte aus Korpus I (der ersten unserer beiden Stichproben, siehe Sampling und Filterung des Korpus) ausgewählt, für die die relative Häufigkeit und die Trend-Linie errechnet wurde.
Mindestanzahl an Datenpunkten für eine generalisierbare Interpretation
Die Texte in dem Beispiel (“Eine Meerfahrt”, “Die Ahnung”, “Waldwinkel”, “Susi”) wurden zwischen 1830 und 1900 veröffentlicht und zeigen einen klaren Trend: Luft wird weniger thematisiert. Diese Texte sind aber nicht repräsentativ für alle literarischen Texte, die in dieser Zeit veröffentlicht wurden. Zwar kann schon anhand von zwei Datenpunkten eine Regressionsgerade berechnet werden, allerdings zeigt diese keinen Trend, der generalisierbar ist. Um mittels der Regressionsgerade tatsächlich einen Effekt zu messen, sollten mindestens 30 Datenpunkte vorliegen. Wenn die Datenpunkte über die Zeit verteilt sind, sollten sie am besten gleichmäßig verteilt sein.
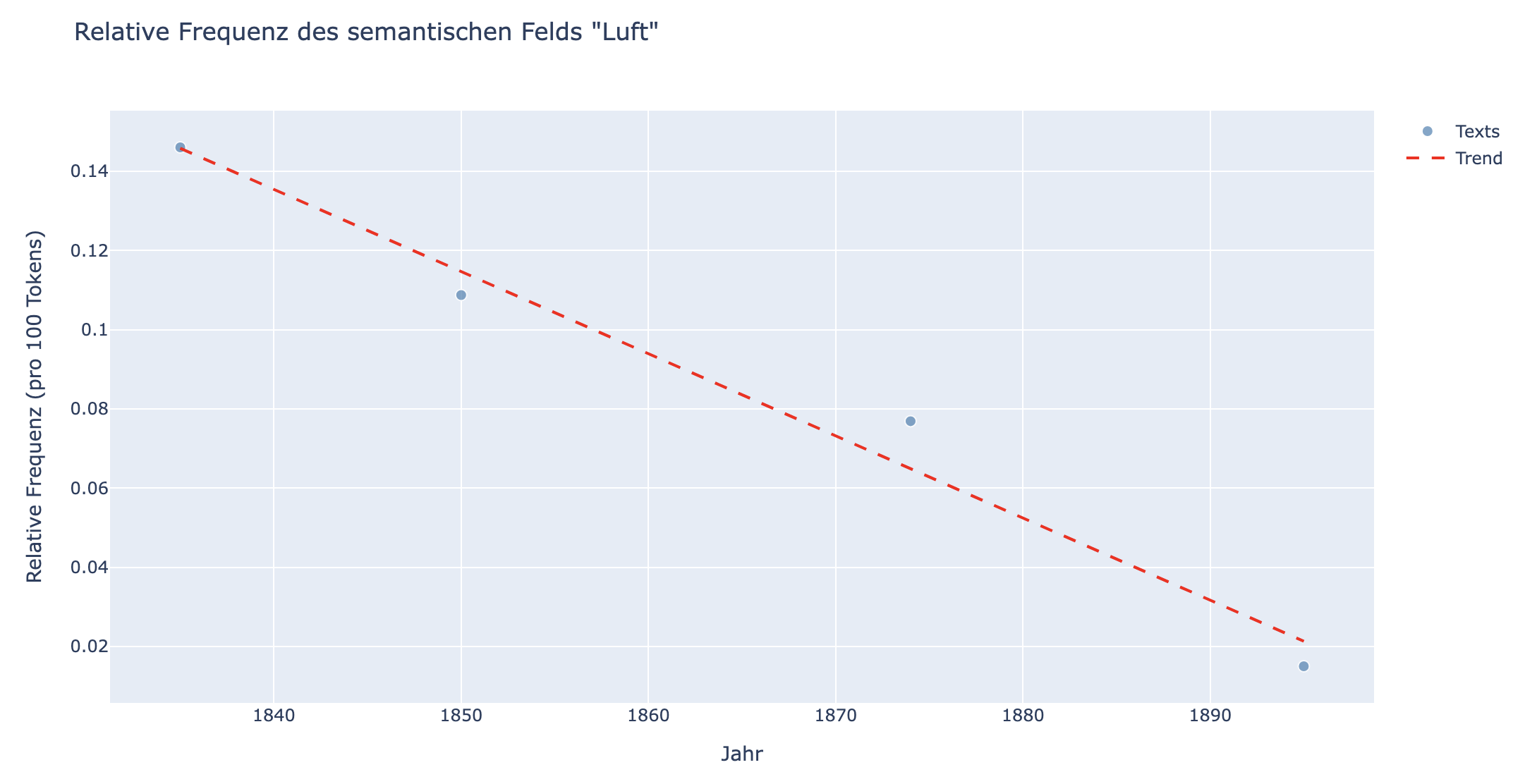
Fig. 5.2 Streudiagramm mit Trend-Linie berechnet auf vier Texten aus Korpus I. Jeder Punkt ist ein Text. Die Texte haben folgende Titel (von links nach rechts): “Eine Meerfahrt”, “Die Ahnung”, “Waldwinkel”, “Susi”.#
Lineare Regression
Um die Regressionsgerade zu berechnen, wird für jeden Punkt der vertikalen Abstand zur Gerade berechnet – also wie weit der tatsächliche Wert nach oben oder unten von der Linie abweicht. Diese Abweichungen nennt man “Fehler” oder “Residuen”. Damit sich positive und negative Abweichungen nicht gegenseitig aufheben, werden diese Abstände quadriert (also mit sich selbst multipliziert). Die beste Linie ist dann diejenige, bei der die Summe dieser quadrierten Abstände am kleinsten ist. Diese Methode der Berechnung heißt Methode der kleinsten Quadrate.
Visuelle Darstellung als Liniendigramm#
Alternativ, wenn es weniger wichtig ist, die Häufigkeiten einzelner Texte abzulesen, ließen sich die Häufigkeiten auch über einen bestimmten Zeitraum zummenfassen und als Liniendiagramm darstellen. Liniendiagramme eignen sich gut, um zeitliche Verläufe darzustellen, da lokale und globale Minima und Maxima leicht erkennbar sind und sie die Kontinuität der Daten unterstreichen. Ein Maximum ist dabei einfach ein Hochpunkt der Linie, ein Minimum ein Tiefpunkt. Lokal heißt: der höchste bzw. tiefste Punkt in einem Abschnitt der Kurve; global heißt: der höchste bzw. tiefste Punkt der gesamten Kurve. Um die Häufigkeiten zusammenzufassen werden sowohl die absoluten Häufigkeiten als auch die Textlängen in dem ausgewählten Zeitraum addiert, sodass auf dieser Basis die relative Häufigkeit für den Zeitraum berechnet werden kann.
Durchschnitt von relativen Häufigkeiten
Eine zweite Möglichkeit, die Häufigkeiten über eine Zeitraum zusammenzufassen, bestünde darin, den Durchschnitt der Häufigkeiten pro Jahr zu berechnen. Allerdings haben bei dieser Methode alle Texte aus dem selben Erscheinungsjahr den gleichen Einfluss auf die Berechnung, unabhängig davon, ob ein Text nur ein zehntel so lang ist wie ein anderer Text.
Jahr |
Absolute Häufigkeit |
Textlänge |
Relative Häufigkeit |
|---|---|---|---|
1823 |
20 |
500 |
0.04 |
1823 |
5 |
100 |
0.05 |
1823 |
15 |
600 |
0.025 |
Alle Häufigkeiten addieren und durch die Summe der Textlängen teilen: \( {{20 + 5 + 15} \over {500 + 100 + 600}} = {{40} \over {1200}} = {0.033}\)
Die relative Häufigkeiten addieren und durch die Anzahl an Texten teilen: \( {{{20 \over 500} + {5 \over 100} + {15 \over 600}} \over 3} = {{0.04 + 0.05 + 0.025} \over 3} = 0.038\)
Mit der zweiten Methode ist die relative Häufigkeit um 0.005 Prozentpunkte höher, da der kurze Text, der die höchste relative Häufigkeit aufweist, ein größeren Einfluss auf die Berechnung hat.