
4.1. NLP als Methode zur “Semantisierung” von Text#
4.1.1. Was ist NLP und warum benutzen wir es?#
Für den Computer ist ein Text eine Liste von Zeichen, die nicht aus semantischen Einheiten wie z.B. Wörtern oder Sätzen besteht. Sobald die Operationalisierung einer Forschungsfrage von diesen semantischen Einheiten ausgeht, z.B. auf der Häufigkeit eines Wortes aufbaut, ist es sinnvoll Methoden des Natural Language Processing (NLP) anzuwenden, um den Text mit zusätzlichen linguistischen Informationen anzureichern.
NLP ist ein interdisziplinäres Feld, das zwischen der Linguistik und der Informatik ansiedelt ist und verschiedene Methoden (regelbasiert, statistisch, maschinelles Lernen) zur automatischen Verarbeitung natürlicher Sprache umfasst. Diese reichen von der Aufteilung eines Texts in Wörter (Tokenisierung) über die Analyse von Emotionen in Texten (Emotion / Sentiment Analysis) bis hin zu der Erstellung von Chatbots (Dialogue Systems).
4.1.2. Voraussetzungen#
Zur Analyse der Luftqualität soll zum einen das semantische Feld “Luft” untersucht werden, zum anderen sollen Adjektive extrahiert werden, die der Luft attribuiert sind, um die Veränderungen in den Eingenschaften, die Luft zugeschrieben werden, untersuchen zu können.
Um das semantische Feld zu untersuchen, sollen alle Wörter in dem Feld automatisch extrahiert und dann gezählt werden. Die Extraktion der Wörter soll folgende Bedingungen erfüllen:
Es sollen nur die Wörter des semantischen Felds gefunden werden. Wenn wir nach “Luft” suchen, wollen wir nicht auch “Luftfahrt” finden.
Unterschiedliche Wortformen sollen auf eine Wortform abgebildet werden. Wenn wir nach “Dunst” suchen, wollen wir auch “Dünste” finden.
Für die Untersuchung der Adjektiv-Nomen-Paare sollen alle Adjektive extrahiert werden, die den häufigsten Nomen des semantischen Felds “Luft” Eigenschaften zuschreiben. Dafür müssen wir zum einen wissen, welche Wörter Adjektive und Nomen sind und zum anderen welche Adjektive in Beziehung zu welchen Nomen stehen.
4.1.3. Verwendete NLP-Methoden#
Um diese Analysen durchführen zu können, müssen mehrere Vorverarbeitungsschritte durchgeführt werden: Zuerst muss das Korpus mittels Tokenisierung in Wörter, sogenannte Token aufgeteilt, werden. Um verschiedene Wortformen auf eine Grundform, ihr Lemma, abzubilden, muss das Korpus lemmatisiert werden.
Zum Begriff des Token
In der Linguistik wird zwischen einem Wort (Type) und der Verwendung eines Wortes (Token) unterschieden. Der Satz “Die Luft ist gut, die Luft ist rein” hat neun Token (das Komma wird auch als Token gezählt) und 6 Types: “die”, “Luft”, “ist”, “gut”, “,”, “rein”.
Um die Adjektive zu extrahieren, muss jedem Wort die Wortart zugewiesen werden. Dies kann automatisch mittels Part-of-Speech (POS)-Tagging durchgeführt werden. Im POS-Tagging werden Tagsets verwendet, in denen jeder Wortart eine Abkürzung zugewiesen wird. Die Tagsets können unterschiedlich granular sein, so finden sich im Stuttgart-Tübingen-Tagset (STTS) 54 Tags, in denen z.B. das Tempus und der Modus von Verben unterschieden wird. Das Universal POS Tagset hingegen besteht nur aus 17 Tags, die keinerlei morphologische Informationen liefern. Für die Extraktion der Adjektive ist das Universal POS Tagset ausreichend.
Die einfachste Methode, um die Beziehung von Adjektiven zu Nomen zu extrahieren, besteht darin, diejenigen Adjektiv-Nomen-Paare zu extrahieren, die den geringsten Abstand voneinander haben. Dass diese Methode schnell zu Fehlern führen kann, lässt sich an folgendem Satz zeigen:
Beispiel
Beispielsatz: Ich roch eine üble, von den Schloten der neuen Fabriken schwer geschwängerte Luft.
Schwierigkeit: Das Nomen, das mit geringsten Abstand zu dem Adjektiv “übel” steht, ist “Schlot”. Tatsächlich bezieht sich das Adjektiv allerdings auf das Nomen “Luft”.
Es wird deshalb auf eine Dependenzgrammatik zurückgegriffen, in der “die syntaktische Struktur eines Satzes ausschließlich anhand gerichteter binärer grammatikalischer Beziehungen zwischen den Wörtern beschrieben wird” (vgl. , S. 427). Die grammatikalischen Beziehungen sind durch ein geschlossenen Vokabular beschrieben. In der Linguistik gibt es verschiedene anerkannte Vokabulare z.B. das Universal Dependencies Annotationsschema ()(s.o.), das für die englische Sprache oder das TIGER-Annotationsschema , das für Deutsch entwickelt wurde.
Unterschiede in den linguistischen Ansätzen zu Dependenzgrammatik
In der Linguistik existieren unterschiedliche Ansätze, um die Beziehung zwischen den Wörtern zu strukturen. Zwei Richtungen sind dabei maßgeblich:
Dependenzgrammatik: Sätze werden in Wörter unterteilt, die Wörter stehen in einer Eins-zu-eins-Beziehung zueinander.
Konstituentengrammatik: Sätze werden in Konstituenten (oder auch Phrasen) unterteilt, die wiederum aus Wörtern bestehen. Sowohl die Wörter in den Konstituenten als auch auch die Konstituenten untereinander sind hierarchisch gegliedert.
Das Universal Dependencies Annotationsschema folgt der Dependenzgrammatik, während das TIGER-Annotationsschema dem Konstituentenmodell folgt.
Automatische Annotationen mit Dependenzinformationen können mittels Dependency Parsing erzeugt werden. In der folgenden Abbildung sind die automatisch erzeugten Dependenzannotationen für den Beispielsatz dargestellt, anhand derer die Adjektiv-Nomen-Paare automatisch extrahiert werden können.
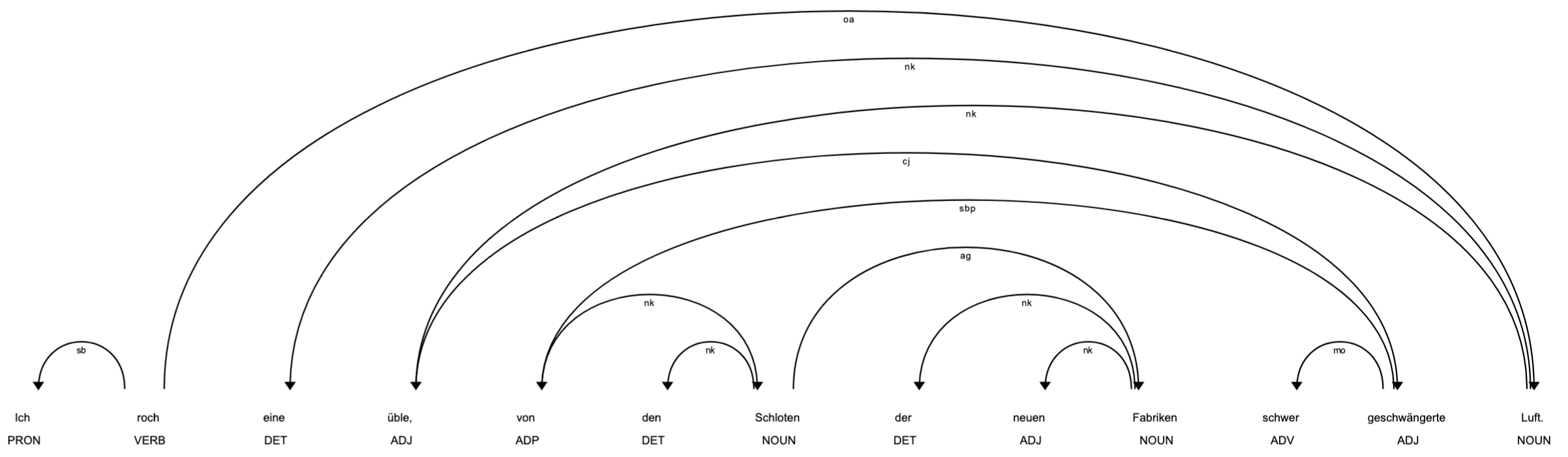
Fig. 4.2 Dependenzannotation erstellt mit der Python-Bibliothek spaCy; model: “de_core_news_sm”.#
Die Dependenzannotation sind durch die beschrifteten Bögen in der oberen Bildhälfte dargestellt. Die Beschriftungen sind die Dependenz-Tags, die Abkürzungen werden in der Python-Bibliothek ”spaCy” (s.u.) wie folgt aufgelöst:
nk: noun kernel element
sb: subject
cj: conjunction
oa: accusative object
sbp: passivized subject
pd: predicate
ag: genitive attribute
svp: passivized subject (PP)
mo: modifier
Die Pfeile drücken die Übergeordnetheit eines Wortes in Beziehung zu einem anderen aus, z.B. ist das Wort “Luft” dem Wort “üble” übergeordnet und zwar mit der Beziehung “noun kernel element”. Das übergeordnete Wort wird Kopf genannt. Die Abbildung zeigt unter dem Satz zusätzlich die POS-Tags, also die Wortarten, die die Grundlage für das Depedency Parsing bilden. Die folgende Tabelle gibt eine Übersicht über die Annotationen, auf denen die Textanalyse aufbaut.
Beispiel der Annotationen im Tabellen-Format
Ursprünglicher Satz: “Ich roch eine üble, von den Schloten der neuen Fabriken schwer geschwängerte Luft.”
In tokenisierter und lemmatisierter Form mit POS-Tags und Dependenz-Tags sowie Dependenz-Kopf:
Token |
Lemma |
POS-Tag |
Dependenz-Tag |
Dependenz-Kopf |
|---|---|---|---|---|
Ich |
ich |
PRON |
sb |
roch |
roch |
roch |
VERB |
ROOT |
roch |
eine |
ein |
DET |
nk |
Luft |
üble |
übel |
ADJ |
nk |
Luft |
, |
– |
PUNCT |
punct |
üble |
von |
von |
ADP |
sbp |
geschwängerte |
den |
der |
DET |
nk |
Schloten |
Schloten |
Schlot |
NOUN |
nk |
von |
der |
der |
DET |
nk |
Fabriken |
neuen |
neu |
ADJ |
nk |
Fabriken |
Fabriken |
Fabrik |
NOUN |
ag |
Schloten |
schwer |
schwer |
ADV |
mo |
geschwängerte |
geschwängerte |
geschwängert |
ADJ |
cj |
üble |
Luft |
Luft |
NOUN |
oa |
roch |
. |
– |
PUNCT |
punct |
roch |
Fehler in der Annotation
In dieser automatischen Annotation lässt sich bereits ein Fehler feststellen: Das Lemma, also die Grundform des Wortes “roch” müsste “riechen” sein.
4.1.4. NLP mit Python#
nltk und spaCy#
In Programmiersprachen gibt es Bibliotheken, die Methoden z.B. zur Textverarbeitung, bündeln. Die Bibliotheken können installiert, in den Programmcode geladen und dann angewendet werden. Für Python gibt es verschiedene Bibliotheken, mit denen die Verarbeitung von Texten mittels NLP möglich ist. Am weitesten vebreitet sind die Bibliotheken spaCy und nltk, die in der folgenden Tabelle verglichen werden.
Bibliothek |
Vorteile |
Nachteile |
|---|---|---|
spaCy |
|
|
nltk |
|
|
Zum Begriff der Pipeline
Die verschiedenen NLP-Methoden bauen teilweise aufeinander auf. Grundlegend wird ein Text zuerst tokenisiert, dann folgt PoS-Tagging und die Lemmatisierung. Diese Abfolge der einzelnen Prozesse wird im NLP häufig mit der Metapher einer Pipeline (englisch für „Rohrleitung”) beschrieben. Der Begriff ist dabei nicht auf das NLP beschränkt: Auch allgemeine Verarbeitungs-, Analyse- oder Forschungsabläufe werden häufig als Pipeline bezeichnet.
NLP mit spaCy#
Da die Vorverarbeitung der Texte keinerlei spezialisierter NLP-Methoden bedarf und auf Grund der leichten Benutzbarkeit sowie der Geschwindigkeit benutzen wir spaCy für die Annotation des Textkorpus. spaCy stellt unterschiedliche Methoden für die Vorverarbeitung bereit, die meisten basieren auf maschinellem Lernen. Da die Vorverarbeitung sprachabhängig ist, stellt spaCy für die unterstützten Sprachen (über 20) verschiedene Analyse-Modelle zur Verfügung. Die Modelle unterscheiden sich in der Geschwindigkeit und in der Akkuratheit der Annotation. Eine Übersicht über die von spaCy unterstützen Sprachen gibt es hier.
Da wir auf einem verhältnismäßig großem Korpus operieren und sich die Leistung der Modelle für die Tokenisierung gar nicht und für die Lemmatisierung, das POS-Tagging und das Dependency Parsing nur wenig (0.01% - 0.04%) unterscheidet, verwenden wir ein Modell, das auf Geschwindigkeit ausgelegt ist (de_core_news_sm). Die Akkuratheit der deutschen Modelle wird auf dieser Website verglichen.
Die Dokumentation von spaCy gibt leider nicht für jede Annotation Auskunft darüber, welches Tagset benutzt wird. Für die Annotation mit POS-Tags bietet spaCy zwei Möglichkeiten, zum einen die gröbere Annotation mit dem Universal Tagset, zum anderen die Annotation mit dem STTS-Tagset. Für die Dependenz-Annotationen wird nicht das Universal-Dependency Tagset verwendet. Es gibt zwar eine Tagübersicht, allerdings ist für die Tags keine Quelle gelistet. Da die deutschen spaCy-Modelle auf Grundlage der TIGER-Annotationen erstellt wurden und die Tagsets fast deckungsgleich scheinen, ist das TIGER-Tagset ein guter Referenzpunkt.
Leistung von spaCy auf unserem Korpus
Die Modelle in spaCy sind auf zeitgenössische Zeitungs- und Medientexte ausgelegt. Historische Sprachverwendung führt zu einer geringeren Annotationsleistung.
4.1.5. Zusammenfassung und nächste Schritte#
Die NLP-Methoden, die für die Vorverarbeitung von Texten notwendig sind, wurden erklärt. spaCy wurde als Bibliothek festgelegt, mit der die Methoden auf die Textdaten angewendet werden. Im nächsten Schritt werden die Texte unseres Korpus (txt-Dateien), mittels spaCy annotiert und die Annotationen werden in einem spaCy-spezifischen sowie im Tabellen-Format gespeichert.