Auswahl des Forschungskorpus THIS FILE IS SUGGESTED FOR DEPRECATION IN FAVOUR OF corpus-collection_choosing-our-corpus-based-on-metadata.ipynb#
Diese Fallstudie untersucht, wie deutschsprachige literarische Texte des 19. Jahrhunderts die abnehmende Luftqualität reflektieren und diskursivieren.
Ein zentraler Schritt besteht darin, ein geeignetes Forschungskorpus auszuwählen, das den historischen Zeitraum und die thematische Breite unserer Forschungsfrage abdeckt.
Im Unterschied zur vorherigen Fallstudie, in der das Korpus selbst aufgebaut wurde, liegt der Fokus hier auf der reflektierten Auswahl eines bestehenden Korpus.
Lernziel
Nach diesem Abschnitt können Sie die Kriterien für die Auswahl eines geeigneten Forschungskorpus benennen, bestehende Korpora vergleichen und den Auswahlprozess datenbasiert begründen.
1 Vom Aufbau zur Auswahl#
Während in der Fallstudie 1 ein eigenes Zeitungskorpus zur Spanischen Grippe 1918/19 aufgebaut wurde, greifen wir in dieser Fallstudie auf bereits existierende digitale Korpora deutschsprachiger Prosa zurück. Wir stehen also nicht vor der Aufgabe, Texte selbst zu digitalisieren, sondern müssen reflektiert entscheiden, welches existierende Korpus für unsere Forschungsfrage geeignet ist.
Die im Kapitel „Korpora als Forschungsobjekte“ beschriebenen Strategien – Vollständigkeit, Repräsentativität, Balance und Opportunismus – bilden dabei unseren Bewertungsrahmen (Schöch, 2017).
2 Vorhandene Korpora deutschsprachiger Prosa#
Im Folgenden werden drei frei verfügbare Korpora vorgestellt, die sich für literaturwissenschaftliche Analysen deutscher Prosa eignen. Konkret wurden für diese Fallstudie das d-Prose-Korpus, das Corpus of German-Language Fiction sowie das German ELTeC-Korpus herangezogen.
Korpus |
Beschreibung |
Zeitraum |
Format |
Auswahlstrategie |
Stärken |
Schwächen |
|---|---|---|---|---|---|---|
d-Prose 1870–1920 (Zenodo) |
ca. 150 Werke, TEI/XML, kuratiert |
1870–1920 |
TEI/XML |
balanciert |
gute Metadaten, literaturwissenschaftlich gepflegt |
begrenzter Zeitraum |
Corpus of German-Language Fiction (Figshare) |
ca. 1 200 Romane in Plain Text mit Metadaten |
1750–1950 |
TXT |
opportunistisch / balanciert |
großer Umfang, gute zeitliche Abdeckung |
uneinheitliche Metadaten, OCR-Fehler |
ELTeC-German (Zenodo) |
ca. 100 Werke, nach ELTeC-Samplingprotokoll |
1840–1920 |
TEI/XML |
repräsentativ |
methodisch solide, Gender-Balance |
relativ klein, Lücken vor 1840 |
Hinweis
Bereits in dieser Übersicht zeigt sich, dass kein Korpus „perfekt“ ist. Die Entscheidung für ein Korpus hängt immer vom Zusammenspiel zwischen Forschungsfrage, zeitlicher Abdeckung, Datenqualität und praktischer Zugänglichkeit ab.
3 Explorative Analyse der Metadaten#
Um die Eignung der Korpora genauer zu prüfen, untersuchen wir zunächst ihre Metadaten. Ziel ist es, ein erstes Gefühl für die zeitliche Verteilung, Vollständigkeit und Struktur der Daten zu gewinnen.
3.1 Laden und Erkunden der Metadaten#
import pandas as pd
import matplotlib.pyplot as plt
# Beispiel: Metadaten des ELTeC-German
meta = pd.read_csv("https://zenodo.org/records/4662482/files/metadata.csv")
meta['year'] = meta['year'].astype(int)
meta.head()
3.2 Zeitliche Verteilung#
meta['year'].hist(bins=30)
plt.xlabel("Publikationsjahr")
plt.ylabel("Anzahl Texte")
plt.title("Zeitliche Verteilung der Texte im ELTEC-DEU")
plt.show()
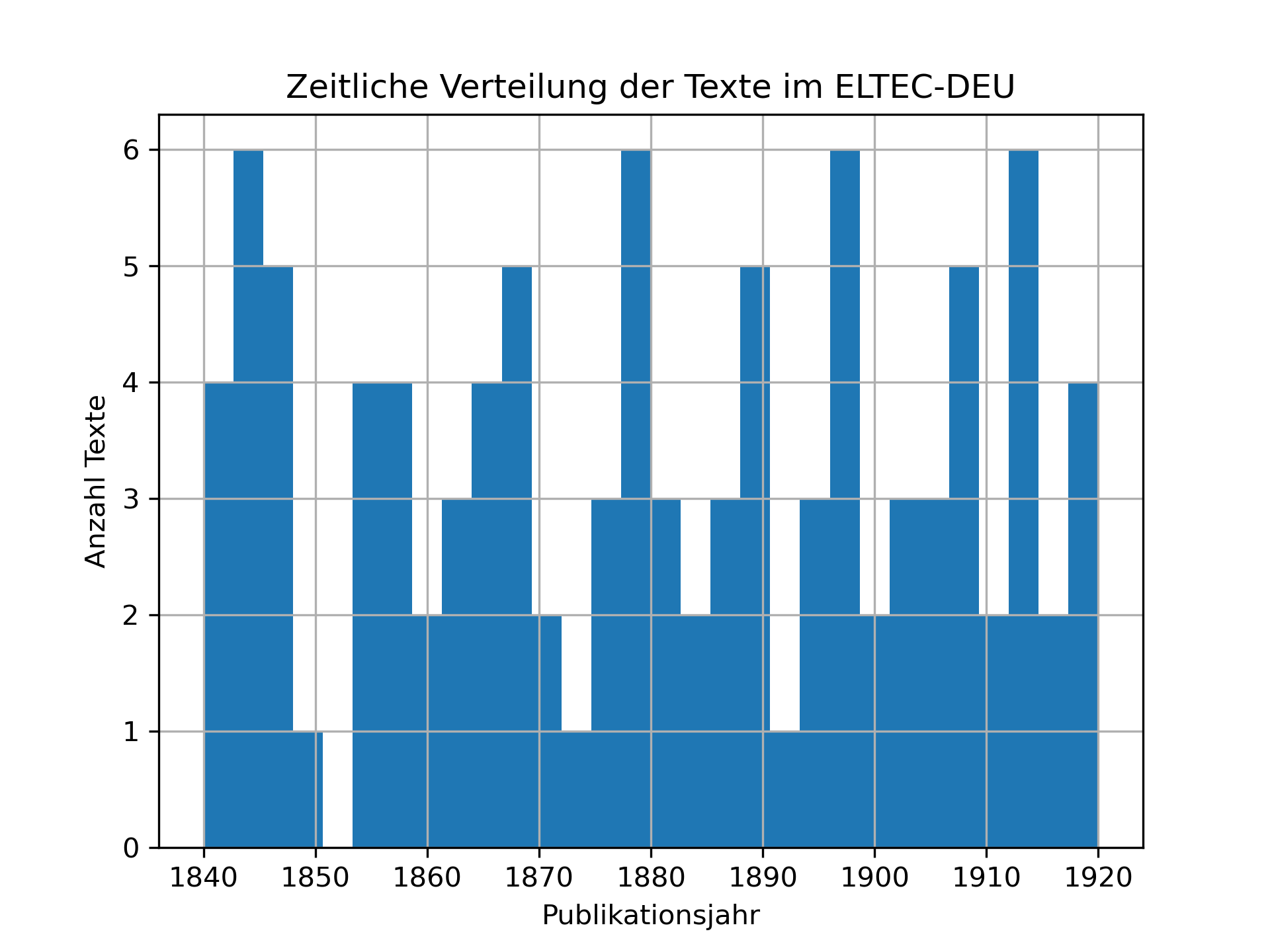
Interpretation
Wie gleichmäßig ist die zeitliche Verteilung? Sind bestimmte Jahrzehnte über- oder unterrepräsentiert?
3.3 Weitere Explorationsideen#
Verteilung der Textlängen
Geschlechterverhältnis der Autor:innen (falls vorhanden)
Anteil von Texten aus dem 19. Jahrhundert
Vergleich mehrerer Korpora nebeneinander
4 Bewertung und Entscheidung#
Die explorative Analyse erlaubt nun eine systematische Bewertung entlang der Kriterien von (Schöch, 2017).
Kriterium |
ELTeC-German |
d-Prose 1870–1920 |
Corpus of German Fiction |
|---|---|---|---|
Zeitliche Abdeckung |
mittel |
gering |
hoch |
Datenqualität |
hoch |
hoch |
mittel |
Repräsentativität |
hoch |
mittel |
gering |
Umfang |
klein |
mittel |
groß |
Verfügbarkeit |
sehr gut |
gut |
gut |
Zwischenfazit
Das Corpus of German-Language Fiction bietet die größte zeitliche Breite und damit die besten Voraussetzungen, um Veränderungen im sprachlichen Diskurs über Luftqualität im 19. Jahrhundert zu untersuchen.
5 Sampling und Filterung des Korpus#
Für die weitere Analyse konzentrieren wir uns auf den Zeitraum 1800–1900. Zudem möchten wir sicherstellen, dass jedes Jahrzehnt annähernd gleich stark vertreten ist.
subset = meta.query("1800 <= year <= 1900")
# Optional: pro Jahrzehnt 10 Texte zufällig ziehen
subset_decades = (
subset.groupby(subset['year']//10*10)
.apply(lambda x: x.sample(n=min(10, len(x)), random_state=42))
.reset_index(drop=True)
)
subset_decades.to_csv("corpus_subset_metadata.csv", index=False)
Weiterführende Übung
Versuchen Sie, eine eigene Filterung zu definieren – z. B. nur Texte, die in Großstädten spielen, oder nur Romane weiblicher Autorinnen.
Solche Entscheidungen verändern das Erkenntnispotenzial des Korpus erheblich.
6 Reflexion: Auswahl als epistemische Entscheidung#
Die Entscheidung für ein bestimmtes Korpus ist nie neutral. Sie bestimmt, welche literarischen Stimmen, Räume und historischen Kontexte in der Analyse sichtbar werden. Die bewusste Reflexion über diese Auswahl ist ein zentraler Bestandteil datenbasierter geisteswissenschaftlicher Forschung.
Merksatz
Mit der Auswahl eines Korpus konstruieren wir das epistemische Objekt unserer Forschung – und damit die Grenzen dessen, was wir erkennen können.
Weiterführende Links
Andersen, A., & Brüggemeier, F.-J. (1989). Gase, rauch und saurer regen. In F.-J. Brüggemeier, & T. Rommelspacher (Eds.), Besiegte Natur. Geschichte und Umwelt im 19. und 20. Jahrhundert (pp. 64–85). C. H. Beck.
Bläß, S. (2020). Korpusbildung. forTEXT.
Brüggemeier, F.-J. (1996). Das unendliche Meer der Lüfte: Luftverschmutzung, Industrialisierung und Risikodebatten im 19. Jahrhundert. Klartext Verlag.
Bühler, B. (2016). Ecocriticism: eine Einführung. J.B. Metzler Verlag.
missing journal in Fischer2017
Heuser, R., & Le-Khac, L. (2011). Learning to read data: bringing out the humanistic in the digital humanities. Victorian Studies, 54(1), 79–86. doi:10.2979/victorianstudies.54.1.79
missing publisher in jurafsky2025
Krautter, B., Pichler, A., & Reiter, N. (2023). Operationalisierung. Zeitschrift für digitale Geisteswissenschaften – ZfdG. Working Paper 2 der Zeitschrift für digitale Geisteswissenschaften. doi:10.17175/WP_2023_010
missing year in lin_detecting_2022
missing year in rabbani_ecological_2025
Schöch, C. (2017). Aufbau von datensammlungen. In F. Jannidis, H. Kohle, & M. Rehbein (Eds.), Digital Humanities: Eine Einführung (pp. 223–233). Stuttgart: J.B. Metzler.
Uekötter, F. (2003). Von der Rauchplage zur ökologischen Revolution: eine Geschichte der Luftverschmutzung in Deutschland und den USA 1880 - 1970. Klartext Verlag.