
5.4. Von linearen zu syntaktischen n-Grammen#
Klassische lineare n-Gramme definieren mehrwortige Muster ausschließlich auf der Grundlage der linearen Wortfolge – also danach, welche Wörter im Text unmittelbar aufeinanderfolgen. Dieser Ansatz ist einfach und oft effektiv, weist jedoch eine zentrale Einschränkung auf: Er reagiert sehr empfindlich auf Wortstellung und auf die Einschübe von Modifikatoren. Dadurch werden semantisch und funktional ähnliche Ausdrücke häufig in viele unterschiedliche Oberflächenvarianten aufgespalten.
Betrachten wir den folgenden Satz:
Ich roch eine üble, von den Schloten der neuen Fabriken schwer geschwängerte Luft.
Eine lineare n-Gramm-Analyse extrahiert daraus benachbarte Sequenzen (2-Gramme) wie:
Ich roch
roch eine
eine üble
üble von
von den
den Schloten
Schloten der
der neuen
neuen Fabriken
Fabriken schwer
schwer geschwängerte
geschwängerte Luft
Diese Muster spiegeln jeweils nur die unmittelbare lineare Aufeinanderfolge von Wörtern wider. Besonders auffällig ist, dass das Adjektiv üble zwar semantisch klar die Luft charakterisiert, in der linearen Struktur jedoch durch eine längere attributive Erweiterung (von den Schloten der neuen Fabriken schwer geschwängerte) vom Substantiv getrennt ist. Eine lineare n-Gramm-Analyse kann diese übergreifende Einheit nicht als zusammenhängendes Muster erfassen.
Diese Einschränkung ist besonders relevant für das Deutsche (Andresen and Zinsmeister, 2017), da hier die Wortstellung vergleichsweise flexibel ist und viele häufige Konstruktionen — etwa Partizipialattribute (wie in unsere Beispiel oben), Verbklammern oder Passivkonstruktionen — auf der Textoberfläche diskontinuierlich realisiert werden. Für eine linguistisch orientierte Analyse bedeutet dies, dass lineare n-Gramme gerade diejenigen Muster fragmentieren, die interpretativ besonders interessant sind.
Syntaktische n-Gramme setzen genau hier an. Sie redefinieren, was als Sequenz gilt, indem sie nicht der linearen Tokenfolge folgen, sondern Relationen in einer syntaktischen Analyse, typischerweise in einem Dependenzbaum. Wortfolgen werden somit nicht als Oberflächenstrings, sondern als Pfade in der syntaktischen Struktur modelliert. In einer syntaktischen n-Gramm-Analyse ist üble unmittelbar als Attribut von Luft analysiert – unabhängig davon, wie viele weitere Modifikatoren dazwischenstehen.
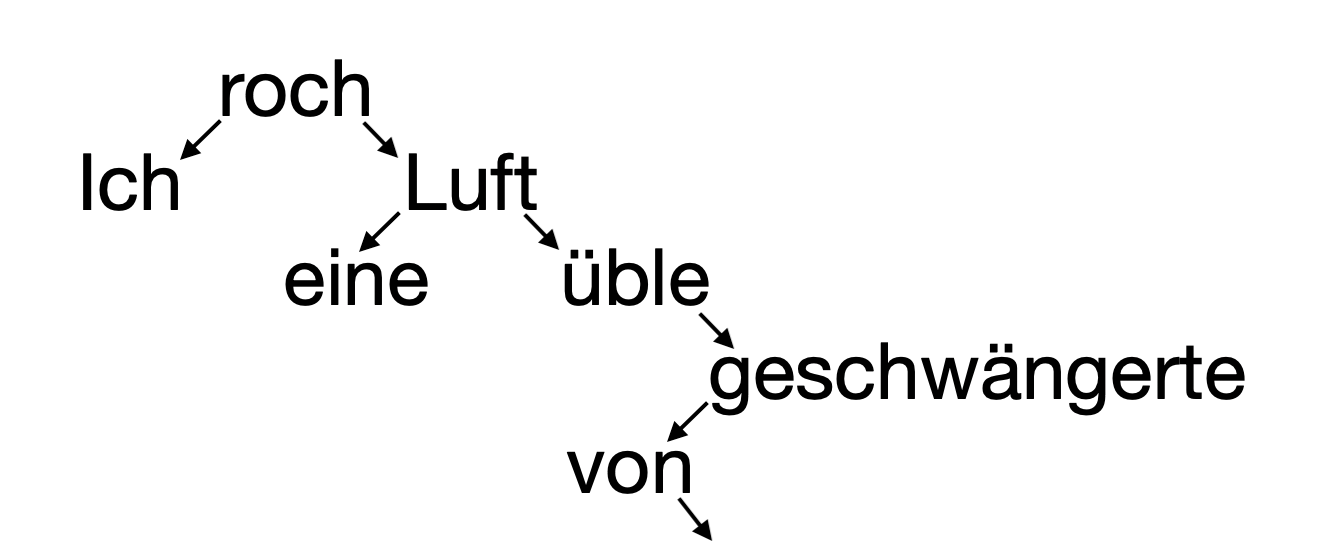
Fig. 5.5 Teil des syntaktischen Dependenzbaum für dasselbe Beispiel.#
Alle Wortpaare in einem solchen Baum, die eine direkte Abhängigkeitsverbindung aufweisen, können als syntaktische Bigramme behandelt werden:
Ich ← roch
roch → Luft
übel ← Luft
ein ← Luft
übel → geschwängerte
von ← geschwängerte
usw.
Dependenzsyntax und Universal Dependencies
Die theoretischen Grundlagen der Dependenzsyntax sowie die detaillierten Prinzipien der Annotation syntaktischer Relationen werden in dieser Fallstudie nicht vertieft behandelt. Wir nutzen für die Extraktion syntaktischer Dependenzen spaCy-Modelle, die auf dem etablierten Standard Universal Dependencies basieren. Eine Übersicht über die zugrunde liegenden Annotierungsprinzipien findet sich hier.
Der vollständige syntaktische Baum, projiziert auf die lineare Struktur desselben Satzes und erzeugt mit dem deutschen spacy-Modell de_core_news_sm, sieht folgendermaßen aus:
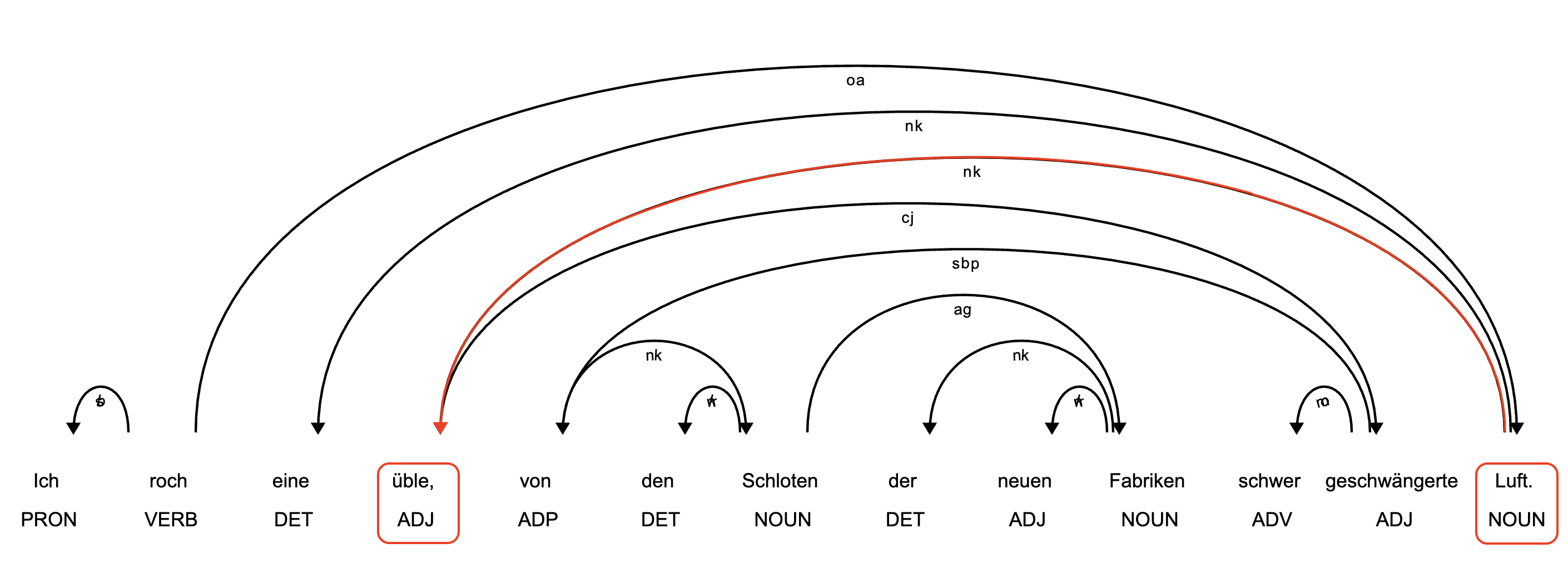
Fig. 5.6 Vollständiger syntaktischer Dependenzbaum für dasselbe Beispiel, projiziert auf die lineare Struktur des Satzes. Die direkte syntaktische Dependenzbeziehung von Luft zu üble ist rot hervorgehoben.#
Solche syntaktischen Muster repräsentieren stabile Weisen, Luftverschmutzung sprachlich zu beschreiben – und sie bleiben auch dann erkennbar, wenn die Oberflächenform variiert, etwa in:
eine von Fabrikrauch geschwängerte, üble Luft
die Luft war übel und von Fabrikdünsten erfüllt
übel erschien die von Rauch erfüllte Luft der Stadt
Für die Analyse historischer Diskurse über Industrialisierung und Luftqualität ermöglichen syntaktische n-Gramme somit den Zugriff auf strukturell wiederkehrende Beschreibungsweisen, selbst wenn diese in der Textoberfläche stark variieren oder diskontinuierlich realisiert sind. Aus diesem Grund haben wir die syntaktische N-Gramm-Analyse als zweite Methode unserer Operationalisierung gewählt.
Operationalisierung (zur Erinnerung)
“Die Reaktion der deutschsprachigen Literatur des 19. Jahrhunderts auf die zunehmende Luftverschmutzung durch die Industrialisierung machen wir messbar <…> indem wir zweitens nach der Semantisierung von ‘Luft’ fragen und hierfür syntaktischen N-Grams des Typs ‘Adjektiv-Substantiv’ analysieren. <…>”
Das folgende Notebook knüpft an diese Überlegungen an und untersucht, wie syntaktische n-Gramme aus dem Korpus extrahiert werden können und wie sie sich als exploratives Analyseinstrument einsetzen lassen.
5.4.1. Bibliographie#
Andresen, M., & Zinsmeister, H. (2017). Montemagni, S., & Nivre, J. (Eds.). The benefit of syntactic vs. linear n-grams for linguistic description. Proceedings of the Fourth International Conference on Dependency Linguistics (Depling 2017) (pp. 4–14). Pisa, Italy: Linköping University Electronic Press. URL: https://aclanthology.org/W17-6503/