
5.3. Von Wörtern zu Mustern: n-Gramme#
Das vorangehende Notebook konzentriert sich auf einzelne Wörter und ihre Häufigkeiten, etwa um semantische Felder rund um Luft, Verschmutzung oder Umwelt zu identifizieren. Solche Analysen sind ein zentraler erster Schritt, bleiben jedoch auf isolierte lexikalische Einheiten beschränkt. Viele inhaltlich relevante Bedeutungen werden jedoch nicht durch einzelne Wörter ausgedrückt, sondern durch wiederkehrende Wortkombinationen.
Ein verbreiteter Ansatz, um über Einzelwörter hinauszugehen, ist die Analyse von n-Grammen. N-Gramme modellieren Sprache als Sequenzen von n aufeinanderfolgenden Tokens und erlauben es, wiederkehrende mehrwortige Muster sichtbar zu machen, etwa Kollokationen, feste Wendungen oder kurze Konstruktionen. Da sie unmittelbar der linearen Abfolge der Tokens im Text folgen, werden solche n-Gramme auch als lineare n-Gramme bezeichnet. So lassen sich statt der getrennten Betrachtung von Rauch und Luft beispielsweise Muster wie dichter Rauch, schlechte Luft oder Luft und Wasser identifizieren. Hier ist ein Beispiel für die Aufteilung einer Phrase aus einem der vielen Texte dieser Fallstudie (Eine Nacht im Jägerhause, Friedrich Hebbel) in N-Gramme der Länge 1, 2 und 3 (d. h. Unigramme, 2-Gramme und 3-Gramme):
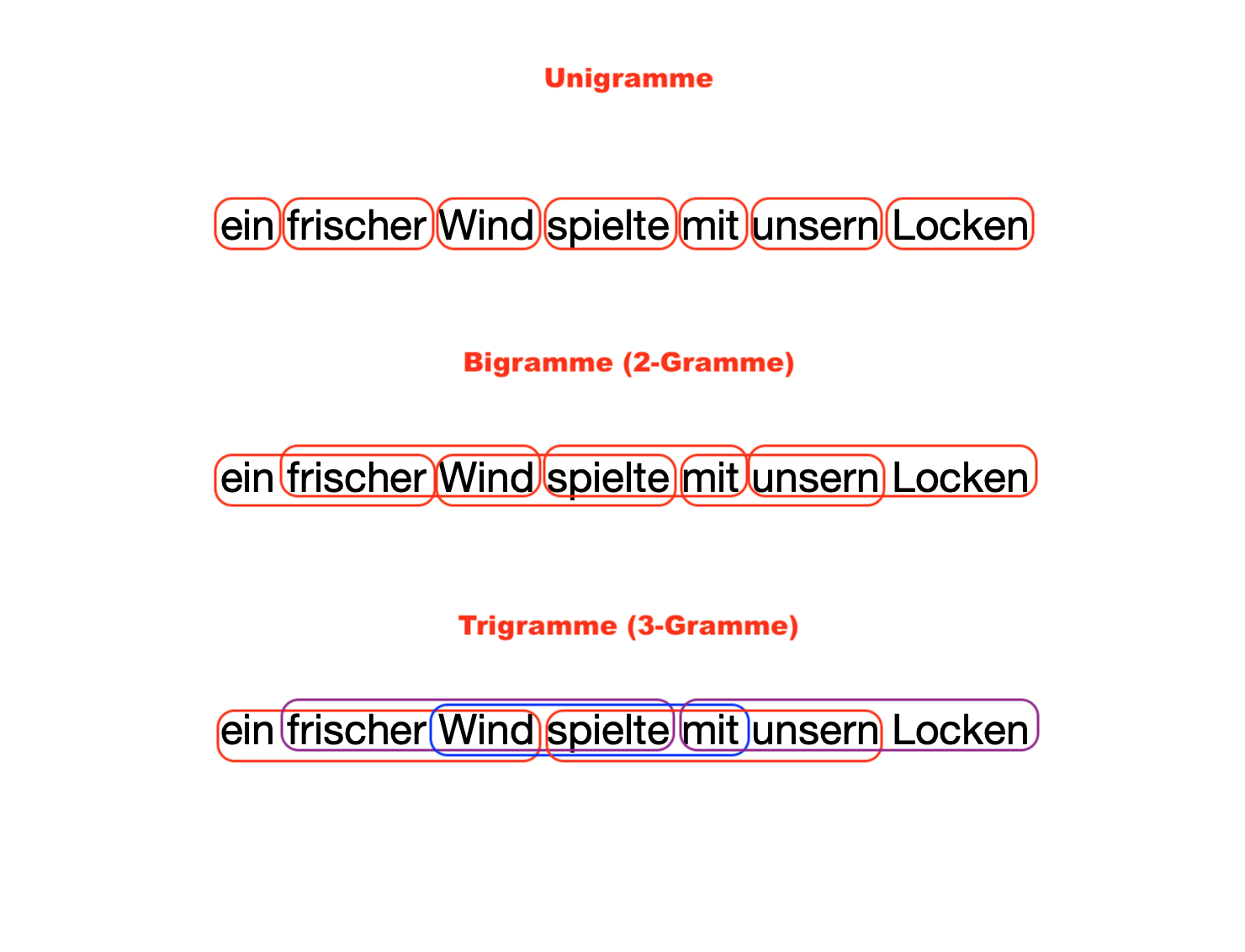
Fig. 5.3 Beispiel für die Aufteilung einer Phrase in N-Gramme der Länge 1, 2 und 3. Unigramme sind einfach Tokens: “ein”, “frischer”, “Wind”, “spielte”, “mit”, “unsern”, “Locken”. 2-Gramme sind Sequenzen aus zwei Token.: “ein frischer”, “frischer Wind”, “Wind spielte”, “spielte mit”, “mit unsern”, “unsern Locken”. 3-Gramme: “ein frischer Wind”, “frischer Wind spielte”, “Wind spielte mit”, “spielte mit unsern”, “mit unsern Locken”.#
In diesem Sinne stellen n-Gramme eine natürliche methodische Erweiterung wortbasierter Frequenzanalysen dar: Der Fokus verschiebt sich von der Frage, welche Wörter vorkommen, hin zu der Frage, wie Wörter regelmäßig gemeinsam auftreten.
Seit längerem ist bekannt, dass Häufigkeiten von n-Grammen ein wirkungsvolles Instrument für die quantitative Untersuchung kultureller Trends, für die Analyse der kulturellen Verarbeitung historischer Ereignisse sowie für die Erforschung der Ideengeschichte darstellen. Bereits in der 2011 erschienenen Arbeit, mit der der Google Books Ngram Viewer eingeführt wurde (Michel et al., 2011), wiesen die Autor:innen auf die kultur- und geschichtswissenschaftliche Aussagekraft gemeinsamer Frequenzverläufe bestimmter n-Gramme hin. Als Beispiele nennen sie unter anderem die zeitliche Dynamik der englischen 3-Gramme “the Great War”, “World War I” und “World War II” im englischsprachigen Korpus sowie die Entwicklung des n-Gramms “天安門” (Tiananmen Square) im chinesischen Korpus.
Inzwischen lassen sich zahlreiche weitere Beispiele finden, die zeigen, wie aufschlussreich n-Gramm-Analysen sein können. Betrachtet man etwa im englischen Google-Books-Korpus alle 2-Gramme, die mit dem Verb “to hate” (hassen) beginnen und mit einem Substantiv enden, so gehört 2-Gramme “hate war” (den Krieg hassen) zu den häufigsten Treffern. Auffällig sind dabei zwei sehr ausgeprägte Häufigkeitsspitzen, die zeitlich mit dem Ersten und dem Zweiten Weltkrieg zusammenfallen.
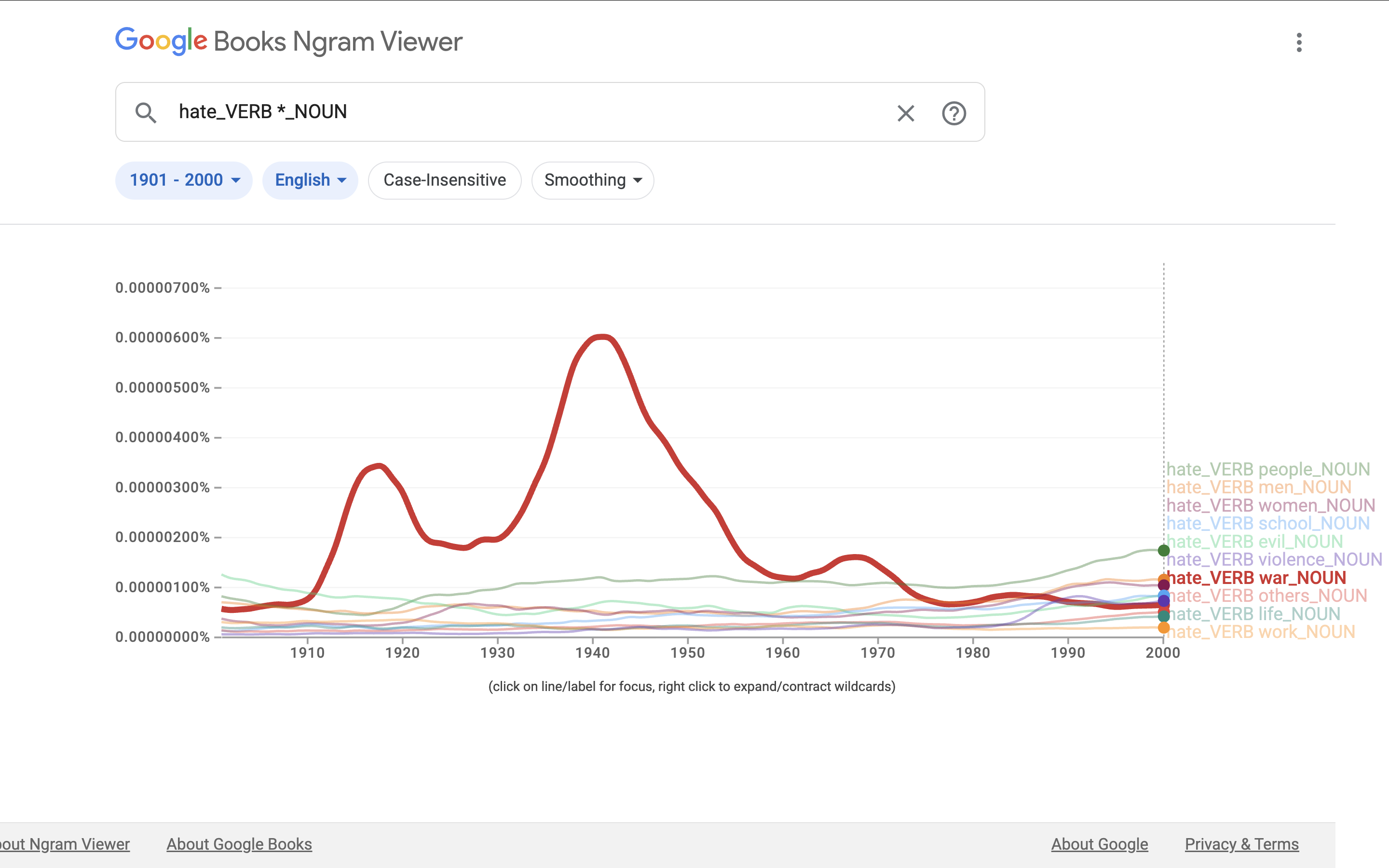
Fig. 5.4 Ngram Viewer Beispiel.#
Solche Befunde verdeutlichen, dass n-Gramme nicht nur lexikalische Muster erfassen, sondern auch als Indikatoren für historische Zäsuren und kollektive Deutungsprozesse gelesen werden können.
5.3.1. Bibliographie#
Michel, J.-B., Shen, Y. K., Aiden, A. P., Veres, A., Gray, M. K., Pickett, J. P., … Aiden, E. L. (2011). Quantitative analysis of culture using millions of digitized books. Science, 331(6014), 176–182. doi:10.1126/science.1199644