
5.6. Eine Baumstatistik einfügen#
Story
Amir Weber möchte nachvollziehen, inwieweit die Art der Bäume und ihrer Umgebung das freiwillige Engagement beim Gießen beeinflussen. Nachdem Sie bereits zeitliche Muster analysiert haben, sollten Sie Ihren Blick nun auf räumliche Faktoren (Baumdichte) sowie baumartspezifische Merkmale richten.
Zweck dieser Übung
In dieser Übung sollen Sie herausfinden, ob die Baumart und räumliche Faktoren (Baumdichte) einen Einfluss auf das Engagement beim Gießen haben. Sie üben:
Baumarten und deren Verteilung in Bezirken statistisch zu beschreiben,
relative Häufigkeiten und Top-Listen (z. B. meistgegossene Arten) zu interpretieren,
und Baumdichte im Verhältnis zur Bezirksfläche quantitativ zu berechnen.
Nachdem Sie zuvor untersucht haben, wie Pflanzjahr und Zeitverlauf das Gießverhalten beeinflussen, richten Sie Ihren Blick nun auf räumliche und baumartspezifische Unterschiede innerhalb Berlins. Sie werden feststellen, dass die Berliner Bezirke sehr unterschiedliche Baumstrukturen aufweisen: Während einige durch eine hohe Dichte gekennzeichnet sind, dominieren in anderen nur wenige Baumgattungen. Sie überprüfen also:
Ob bestimmte Baumgattungen häufiger gegossen werden als andere.
Ob die Baumdichte das Gießverhalten beeinflusst. Amir vermutet, dass dicht bepflanzte Straßen oder Kieze das Gießverhalten begünstigen. Nach dem Motto: „Wenn ich schon meinen Baum gieße, mache ich den daneben auch gleich mit.“
Die Visualisierung soll die Verteilung der Bäume auf die Berliner Bezirke sichtbar machen und die am häufigsten gegossenen Baumarten identifizieren. Darüber hinaus dient sie der Analyse der Baumdichte im Verhältnis zur Bezirksfläche, um mögliche räumliche Muster im Engagement zu erkennen.
Dies soll weitere Erkenntnisse darüber liefern, welche strukturellen Faktoren im Stadtraum das Engagement der Gießenden möglicherweise begünstigen.
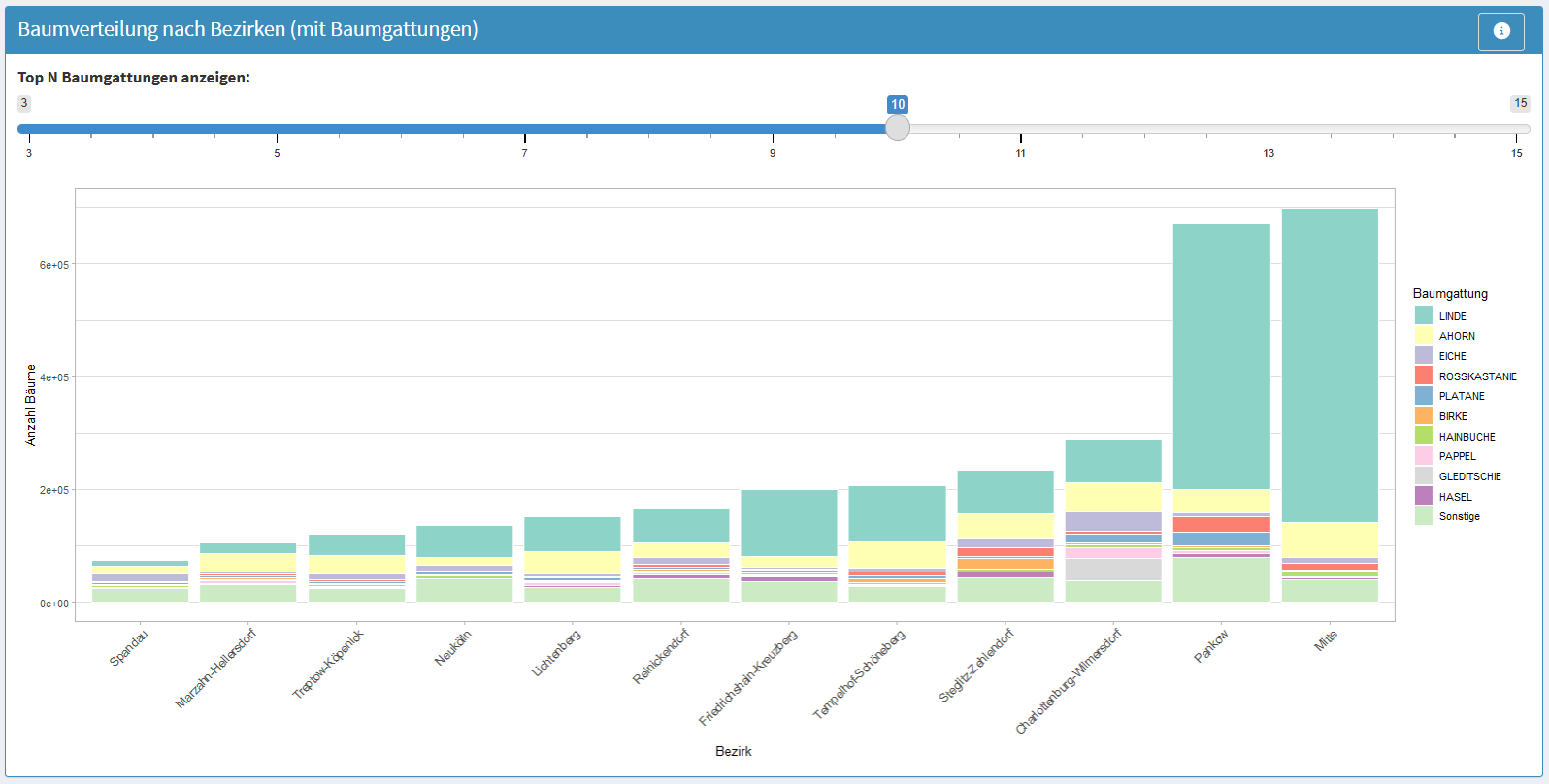
Abb. 5.10 Baumverteilung nach Bezirken und Baumgattungen. Die Abbildung zeigt die Verteilung der Bäume in den Berliner Bezirken, aufgeschlüsselt nach Baumgattungen. Die Anzahl der Bäume ist für jeden Bezirk als gestapeltes Balkendiagramm dargestellt, wobei die einzelnen Farbsegmente unterschiedliche Baumgattungen repräsentieren. Über einen Schieberegler kann die Anzahl der angezeigten, häufigsten Baumgattungen interaktiv angepasst werden, während weniger häufige Gattungen unter „Sonstige“ zusammengefasst sind. (Quelle: eigene Ausarbeitung)#
Das obenstehende Diagramm ist ein Balkendiagramm, genauer gesagt ein gestapeltes Balkendiagramm, das mehrere Informationsebenen gleichzeitig vermittelt. Der zentrale Mehrwert dieser Darstellungsform liegt darin, sowohl die Gesamtanzahl der Bäume pro Bezirk als auch deren Zusammensetzung nach Gattungen in einer einzigen Visualisierung zu vereinen. Die Balkenlänge zeigt auf einen Blick, welche Bezirke den größten Baumbestand haben, während die farbigen Segmente innerhalb jedes Balkens die Artenvielfalt und deren relative Anteile offenlegen. Dies ermöglicht direkte Vergleiche zwischen Bezirken: Nutzer:innen können nicht nur erkennen, dass Bezirk A mehr Bäume hat als Bezirk B, sondern auch, ob beide eine ähnliche Gattungsverteilung aufweisen oder ob bestimmte Arten in einzelnen Bezirken dominieren. Die Anpassung über den Schieberegler reduziert visuelle Komplexität und ermöglicht es, den Fokus je nach Fragestellung auf die häufigsten Gattungen zu legen oder eine detailliertere Aufschlüsselung zu betrachten. So macht das Balkendiagramm komplexe, mehrdimensionale Daten intuitiv erfassbar. Balkendiagramme zählen zu den etabliertesten Darstellungswerkzeugen der Datenvisualisierung. Ihre breite Anwendung in dieser Fallstudie spiegelt ihre Vielseitigkeit und Lesbarkeit wider.
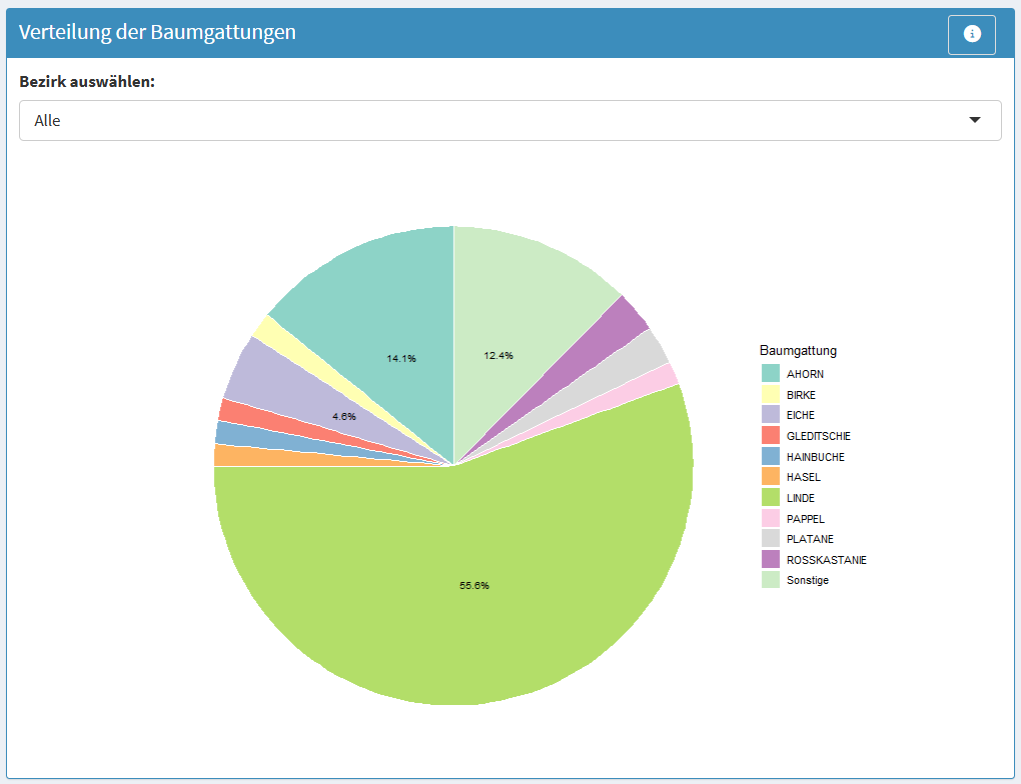
Abb. 5.11 Verteilung der Baumgattungen. Die Abbildung zeigt die prozentuale Verteilung der Baumgattungen im Berliner Baumbestand in Form eines Kreisdiagramms. Über ein Auswahlfeld kann der betrachtete Bezirk festgelegt werden, wodurch sich die dargestellte Verteilung entsprechend anpasst. Die einzelnen Kreissegmente repräsentieren die Anteile der jeweiligen Baumgattungen am Gesamtbestand des ausgewählten Bezirks. (Quelle: eigene Ausarbeitung)#
Das obenstehende Diagramm ist ein Kreisdiagramm (auch Tortendiagramm genannt), das die prozentuale Zusammensetzung der Baumgattungen innerhalb eines Bezirks visualisiert. Der zentrale Mehrwert dieser Darstellungsform liegt in ihrer Fähigkeit, Anteile und Proportionen intuitiv erfassbar zu machen: Nutzer:innen erkennen auf einen Blick, welche Gattungen den Baumbestand dominieren und welche nur eine untergeordnete Rolle spielen. Die Kreisform vermittelt das Konzept des „Ganzen“ unmittelbar, denn alle Segmente zusammen ergeben 100% des Baumbestands im gewählten Bezirk. Dies erleichtert das Verständnis relativer Größenverhältnisse, etwa wenn eine Gattung ein Viertel oder die Hälfte aller Bäume ausmacht. Die interaktive Bezirksauswahl ermöglicht zudem gezielte Vergleiche: Nutzer:innen können erkunden, ob bestimmte Gattungen in verschiedenen Stadtteilen unterschiedlich stark vertreten sind. Im Gegensatz zum Balkendiagramm, das absolute Zahlen und Mengenvergleiche betont, fokussiert das Kreisdiagramm auf die innere Struktur und Diversität des Baumbestands eines einzelnen Bezirks.
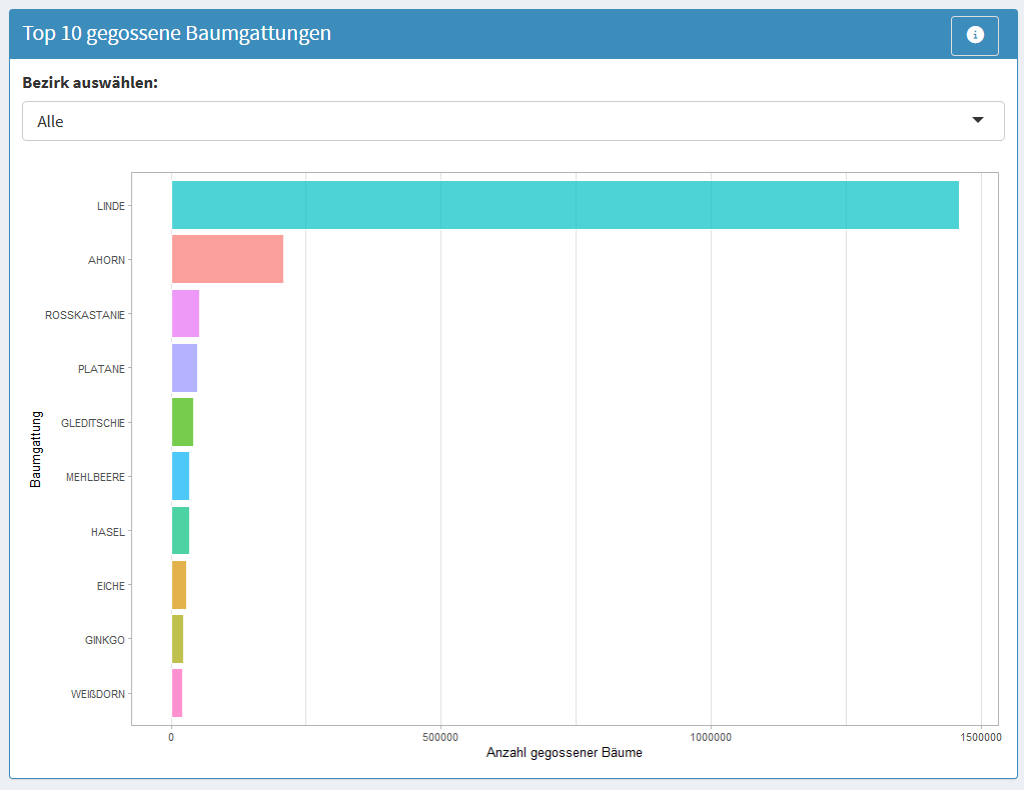
Abb. 5.12 Die 10 meistgegossenen Baumgattungen. Die Abbildung zeigt die 10 meist gegossenen Baumgattungen in Berlin in Form eines horizontalen Balkendiagramms. Über ein Auswahlfeld kann der betrachtete Bezirk festgelegt werden, wodurch sich die dargestellten Werte entsprechend anpassen. Die Balken repräsentieren die absolute Anzahl gegossener Bäume je Gattung, wobei die Linde mit deutlichem Abstand an erster Stelle steht, gefolgt von Ahorn (ca. 250.000) und weiteren Gattungen mit jeweils deutlich geringeren Werten. Die x-Achse zeigt die Anzahl gegossener Bäume, die y-Achse die Baumgattungen. (Quelle: eigene Ausarbeitung)#
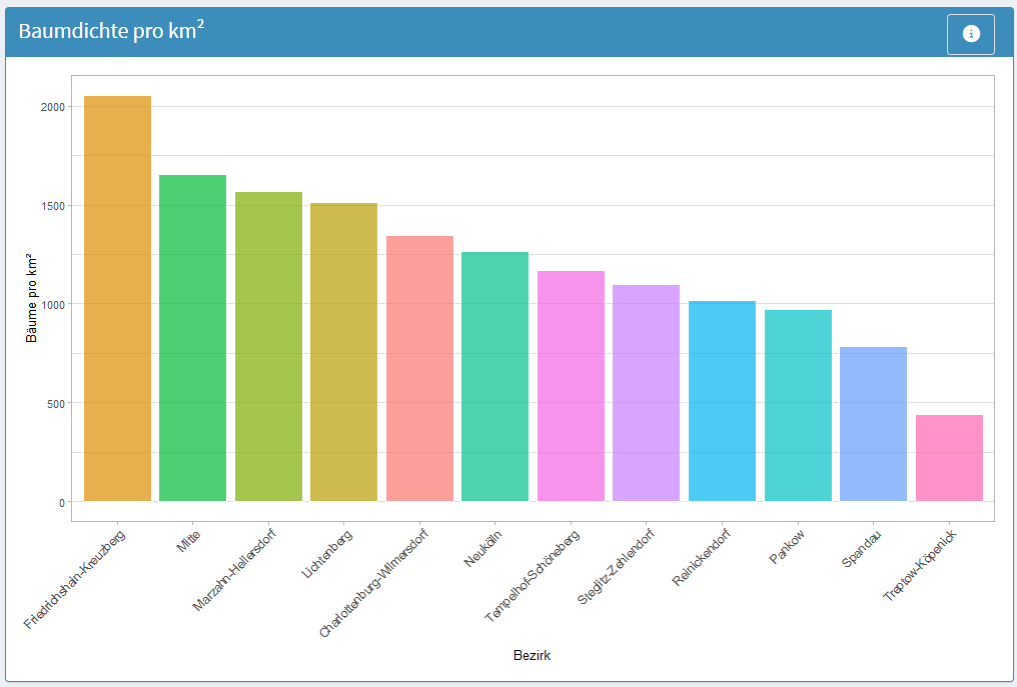
Abb. 5.13 Baumdichte pro km². Die Abbildung zeigt die Baumdichte pro km² in den verschiedenen Berliner Bezirken in Form eines vertikalen Balkendiagramms. Die Balken repräsentieren die jeweilige Baumdichte, wobei Friedrichshain-Kreuzberg die höchste Dichte aufweist. Die x-Achse zeigt die Bezirke, die y-Achse die Anzahl der Bäume pro km². Die Darstellung ermöglicht einen direkten Vergleich der Baumdichte zwischen den zwölf Berliner Bezirken. (Quelle: eigene Ausarbeitung)#
Was Sie beachten sollten
Nur weil bestimmte Kennzahlen in einer Analyse oder Visualisierung nicht berücksichtigt wurden, bedeutet dies nicht, dass sie für die Interpretation irrelevant sind. Für das Verständnis der oben dargestellten Abb. 5.12 ist beispielsweise eine Information zur Häufigkeit von Baumarten (wie in Abb. 5.11 dargestellt) unabdingbar. Für eine korrekte Analyse der Abb. 5.13 (Baumdichte pro km²) braucht es mindestens Hinweise zur Größe der Bezirke. Darüber hinaus könnten zusätzliche Kontextinformationen, etwa zur Bevölkerungsdichte, sinnvoll sein, um die dargestellten Werte angemessen einordnen zu können.
Betrachten Sie Datenvisualisierungen daher stets kritisch und fragen Sie sich:
Welche Kennzahlen wurden in die Darstellung einbezogen?
Welche weiteren Kennzahlen wären für das Verständnis ebenfalls relevant gewesen?
Welche Informationen fehlen möglicherweise zur Einordnung der Ergebnisse?
Fehlende Kontextinformationen können dazu führen, dass Zusammenhänge verzerrt oder unvollständig interpretiert werden.
Insbesondere bei der Interpretation von Datenvisualisierungen ist daher Vorsicht geboten: Lassen Sie sich nicht ausschließlich von den visuell hervorgehobenen oder dargestellten Indikatoren leiten, sondern berücksichtigen Sie auch potenziell fehlende Einflussfaktoren und Kontextinformationen.
5.6.1. Benutzeroberfläche (UI)#
Zunächst fügen Sie einen weiteren Menüpunkt zur Navigation hinzu, um den Baumstatistik-Tab zugänglich zu machen.
Navigation in der Seitenleiste
dashboardSidebar(
sidebarMenu( id = "sidebarMenu",
menuItem("Startseite", tabName = "start", icon = icon("home")),
menuItem("Karte", tabName = "map", icon = icon("map")),
menuItem("Zeitverlauf", tabName = "stats", icon = icon("bar-chart")),
# NEU: Menüpunkt für die Baumstatistik hinzufügen
menuItem("Baumstatistik", tabName = "engagement", icon = icon("hands-helping"))
)
)
Inhaltsbereich: Diagramme und Filter#
Der Inhaltsbereich enthält die Diagramme sowie Filteroptionen, mit denen Nutzer:innen die Darstellung anpassen können.
Code
tabItem(
tabName = "engagement",
fluidRow(
box(
title = tagList(
"Baumverteilung nach Bezirken (mit Baumgattungen)",
div(
actionButton("info_btn_bvnb", label = "", icon = icon("info-circle")),
style = "position: absolute; right: 15px; top: 5px;"
)
),
status = "primary",
solidHeader = TRUE,
width = 12,
sliderInput(
"top_n_species",
"Ändern Sie den Detailgrad der Auffächerung, indem Sie mit dem Schieberegler die Anzahl an Baumgattungen bestimmen (sortiert nach Häufigkeit - absteigend)",
min = 3,
max = 15,
value = 8,
step = 1
),
plotOutput("tree_distribution_stacked", height = "500px")
)
),
fluidRow(
box(
title = tagList(
"Verteilung der Baumgattungen",
div(
actionButton("info_btn_vdb", label = "", icon = icon("info-circle")),
style = "position: absolute; right: 15px; top: 5px;"
)
),
status = "primary",
solidHeader = TRUE,
width = 12,
selectInput(
"pie_bezirk",
"Bezirk auswählen:",
choices = c("Alle Bezirke", sort(unique(df_merged$bezirk))),
selected = "Alle Bezirke"
),
plotOutput("tree_species_pie", height = "500px")
),
box(
title = tagList(
"Baumdichte pro km²",
div(
actionButton("info_btn_bdpf", label = "", icon = icon("info-circle")),
style = "position: absolute; right: 15px; top: 5px;"
)
),
status = "primary",
solidHeader = TRUE,
width = 12,
plotOutput("tree_density_area", height = "500px")
)
),
fluidRow(
box(
title = tagList(
"Die 10 meistgegossenen Baumgattungen",
div(
actionButton("info_btn_hgb", label = "", icon = icon("info-circle")),
style = "position: absolute; right: 15px; top: 5px;"
)
),
status = "primary",
solidHeader = TRUE,
width = 12,
selectInput(
"engagement_bezirk",
"Bezirk auswählen:",
choices = c("Alle Bezirke", sort(unique(df_merged$bezirk))),
selected = "Alle Bezirke"
),
plotOutput("top_watered_species", height = "500px")
)
)
)
Erklärung des Codes
Struktur des Inhaltsbereichs:
box(...)gruppiert alle Elemente visuelltitleenthält die jeweilige Überschrift und einen Info-Buttonstatus = "primary"bestimmt das farblich einheitliche Design mitsolidHeader = TRUEwidth = 12bedeutet volle Seitenbreite in der Rasterstruktur des Dashboards.
Filterelemente:
sliderInput("top_n_species", ...)– Ein Schieberegler zur dynamischen Anpassung der Anzahl gezeigter Baumgattungen. So lassen sich die Balkendiagramme übersichtlich halten.selectInput(...)– Dropdown-Menüs (pie_bezirk,engagement_bezirk), mit denen Nutzer:innen gezielt nach spezifischen Bezirken filtern können.
Visualisierung:
plotOutput(...)(z. B."tree_distribution_stacked","tree_species_pie") reserviert Platz für das grafische Element.Die tatsächliche Grafik wird später im Server über die
renderPlot()-Funktion erzeugt.height = "500px"sorgt für ein einheitliches Anzeigefenster aller Diagramme.
Diese Struktur ermöglicht den Nutzer:innen interaktive Ansichten und ein klares Interface zur Datenerkundung.
5.6.2. Server#
Gestapeltes Balkendiagramm: Baumverteilung nach Bezirken#
Das erste Diagramm soll zeigen, wie viele Bäume in jedem Bezirk stehen und welche Gattungen dort dominieren. Um die Visualisierung übersichtlich zu halten, konzentrieren Sie sich auf die häufigsten Baumgattungen. Alle anderen fassen Sie unter „Sonstige“ zusammen.
Code
# 1. Stacked Bar Chart - Baumverteilung mit Gattungen
output$tree_distribution_stacked <- renderPlot({
req(input$sidebarMenu == "engagement")
n_gen <- input$top_n_species
top_genera <- df_merged %>%
filter(!is.na(gattung_deutsch)) %>%
count(gattung_deutsch, sort = TRUE) %>%
head(n_gen) %>%
pull(gattung_deutsch)
Erklärung des Codes
Top-Gattungen ermitteln:
req(input$sidebarMenu == "engagement")– rendert den Plot nur, wenn der aktuelle Tab „engagement“ aktiv istn_gen <- input$top_n_species– speichert den Slider-Wert in einer Variablefilter(!is.na(gattung_deutsch))– entfernt Bäume ohne Gattungsangabecount(gattung_deutsch, sort = TRUE)– zählt jede Gattung und sortiert absteigendhead(n_gen)– wählt die häufigsten Gattungen (gesteuert durch die Variablen_gen)pull(gattung_deutsch)– extrahiert die Gattungsnamen als Vektor
Diese Gattungsliste verwenden Sie später, um alle anderen Gattungen als „Sonstige“ zu kennzeichnen.
Daten aggregieren und gruppieren#
Jetzt bereiten Sie die Daten so auf, dass für jeden Bezirk gezählt wird, wie viele Bäume jeder Gattungsgruppe dort stehen.
Code
df_agg <- df_merged %>%
filter(!is.na(bezirk)) %>%
mutate(gattung_grouped = ifelse(gattung_deutsch %in% top_genera, gattung_deutsch, "Sonstige")) %>%
group_by(bezirk, gattung_grouped) %>%
summarise(count = n(), .groups = "drop") %>%
group_by(bezirk) %>%
mutate(percentage = count / sum(count) * 100) %>%
ungroup()
Erklärung des Codes
Datenaufbereitung:
filter(!is.na(bezirk))– entfernt Bäume ohne Bezirkszuordnungmutate(gattung_grouped = ...)– gruppiert Gattungen:Wenn die Gattung zu der ausgewählten Anzahl gehört → behalte den Namen
Ansonsten → kennzeichne als „Sonstige“
group_by(bezirk, gattung_grouped)– gruppiert nach Bezirk und Gattungsgruppesummarise(count = n())– zählt Bäume pro Gruppemutate(percentage = ...)– berechnet den prozentualen Anteil jeder Gattung innerhalb des Bezirks
Gestapeltes Balkendiagramm erstellen#
Mit den aggregierten Daten erstellen Sie nun das gestapelte Balkendiagramm, das die Baumverteilung nach Bezirken visualisiert.
Code
df_agg$gattung_grouped <- factor(df_agg$gattung_grouped,
levels = c(top_genera, "Sonstige"))
# "Sonstige" bekommt Grau; Rest aus globaler Palette
n_gen <- input$top_n_species
fill_vals <- c(colorRampPalette(GDK_PALETTE_BASE)(n_gen), "#D3D3D3")
names(fill_vals) <- c(top_genera, "Sonstige")
ggplot(df_agg, aes(x = reorder(bezirk, count, sum), y = count, fill = gattung_grouped)) +
geom_bar(stat = "identity", position = "stack", color = "white", linewidth = 0.3) +
scale_fill_manual(values = fill_vals, name = "Baumgattung") +
labs(x = "Bezirk", y = "Anzahl Bäume") +
theme_light() +
theme(
axis.text.x = element_text(angle = 45, hjust = 1, size = 10),
legend.position = "right",
panel.grid.major.x = element_blank()
)
})
# Info button
observeEvent(input$info_btn_bvnb, {
showModal(modalDialog(
title = "Information: Baumverteilung nach Bezirken",
HTML("
<p>Diese Grafik zeigt die <strong>Gesamtanzahl und Zusammensetzung der Bäume</strong> in jedem Berliner Bezirk nach Gattung.</p>
<ul>
<li>Jeder Balken zeigt die Gesamtzahl der Bäume im Bezirk</li>
<li>Die Farben zeigen die verschiedenen Baumgattungen (z.B. LINDE, AHORN, EICHE)</li>
<li>Seltene Gattungen werden als 'Sonstige' zusammengefasst</li>
<li>Nutzen Sie den Slider, um mehr oder weniger Gattungen anzuzeigen</li>
</ul>
"),
easyClose = TRUE,
footer = modalButton("Schließen")
))
})
Erklärung des Codes
Gestapeltes Balkendiagramm:
factor(df_agg$gattung_grouped, levels = ...)– definiert die Reihenfolge der Gattungen (Top-Gattungen zuerst, dann „Sonstige“)reorder(bezirk, count, sum)– sortiert Bezirke nach Gesamtanzahl der Bäumegeom_bar(stat = "identity", position = "stack")– erstellt gestapelte Balkenfill = gattung_grouped– färbt die Segmente nach Gattungsgruppescale_fill_brewer(palette = "Set3")– verwendet eine farblich abgestimmte Palette
Was zeigt der Plot?
Welche Gattungen in welchem Bezirk dominieren
Wie groß der Anteil der „Sonstigen“ ist
Wie sich Bezirke in ihrer Baumstruktur unterscheiden
Kreisdiagramm: Gattungsverteilung#
Das Kreisdiagramm soll die prozentuale Zusammensetzung der Baumgattungen zeigen, entweder für ganz Berlin oder für einen ausgewählten Bezirk. Diese Darstellung macht auf einen Blick deutlich, welche Gattungen dominieren.
Code
# 2. Pie Chart - Gattungsverteilung
output$tree_species_pie <- renderPlot({
req(input$sidebarMenu == "engagement")
filtered_data <- df_merged
if (input$pie_bezirk != "Alle Bezirke") {
filtered_data <- filtered_data %>%
filter(bezirk == input$pie_bezirk)
}
df_agg <- filtered_data %>%
filter(!is.na(gattung_deutsch)) %>%
count(gattung_deutsch, sort = TRUE) %>%
mutate(
gattung_grouped = ifelse(row_number() <= 10, gattung_deutsch, "Sonstige")
) %>%
group_by(gattung_grouped) %>%
summarise(count = sum(n), .groups = "drop") %>%
arrange(desc(count)) %>%
mutate(
percentage = count / sum(count) * 100,
label = paste0(gattung_grouped, "\n", round(percentage, 1), "%")
)
n_slices <- nrow(df_agg)
has_sonst <- "Sonstige" %in% df_agg$gattung_grouped
n_named <- if (has_sonst) n_slices - 1 else n_slices
fill_vals <- c(colorRampPalette(GDK_PALETTE_BASE)(n_named),
if (has_sonst) "#D3D3D3" else NULL)
names(fill_vals) <- df_agg$gattung_grouped
ggplot(df_agg, aes(x = "", y = count, fill = gattung_grouped)) +
geom_bar(stat = "identity", width = 1, color = "white", linewidth = 0.5) +
coord_polar("y", start = 0) +
scale_fill_manual(values = fill_vals, name = "Baumgattung") +
labs(title = NULL) +
theme_void() +
theme(
legend.position = "right",
legend.text = element_text(size = 9)
) +
geom_text(aes(label = ifelse(percentage > 3, paste0(round(percentage, 1), "%"), "")),
position = position_stack(vjust = 0.5), color = "white",
fontface = "bold", size = 3.5)
})
# Info button
observeEvent(input$info_btn_vdb, {
showModal(modalDialog(
title = "Information: Verteilung der Baumgattungen",
HTML("
<p>Diese Grafik zeigt die <strong>prozentuale Verteilung der Baumgattungen</strong>.</p>
<ul>
<li>Zeigt die 10 meistgegossenen Baumgattungen (z.B. LINDE, AHORN, EICHE)</li>
<li>Alle anderen Gattungen werden als 'Sonstige' zusammengefasst</li>
<li>Kann auf einzelne Bezirke gefiltert werden</li>
<li>Hilft zu verstehen, welche Gattungen in Berlin dominieren</li>
</ul>
"),
easyClose = TRUE,
footer = modalButton("Schließen")
))
})
Erklärung des Codes
Bezirksfilter:
Wenn ein bestimmter Bezirk ausgewählt wurde, werden nur dessen Bäume betrachtet
Ansonsten zeigt das Diagramm die Verteilung für ganz Berlin
Datenaufbereitung:
count(gattung_deutsch, sort = TRUE)– zählt jede Gattungrow_number() <= 10– markiert die 10 meistgegossenen Gattungen, alle anderen werden zu „Sonstige“group_by(gattung_grouped)– fasst gleiche Gruppen zusammenmutate(percentage = ...)– berechnet prozentuale Anteile
Kreisdiagramm erstellen:
coord_polar("y", start = 0)– wandelt ein Balkendiagramm in ein Kreisdiagramm umscale_fill_manual(values = fill_vals, name = "Baumgattung")– nutzt die globale Farbpalette für konsistentes Designgeom_text(...)– fügt Prozentangaben hinzu (nur bei Segmenten > 3%), weiß und fett formatierttheme_void()– entfernt Achsen und Gitter für eine klare Darstellung
Das Kreisdiagramm zeigt intuitiv, welche Gattungen den Baumbestand dominieren – ideal für schnelle Vergleiche zwischen Bezirken.
Baumdichte pro Fläche berechnen#
Um Bezirke fair vergleichen zu können, berechnen Sie die Baumdichte, also wie viele Bäume pro Quadratkilometer stehen. Ein großer Bezirk kann viele Bäume haben, aber trotzdem eine niedrige Dichte aufweisen.
Code
# 3. Baumdichte pro Bezirksfläche
output$tree_density_area <- renderPlot({
req(input$sidebarMenu == "engagement")
bezirk_flaeche <- data.frame(
bezirk = c("Charlottenburg-Wilmersdorf", "Friedrichshain-Kreuzberg", "Lichtenberg",
"Marzahn-Hellersdorf", "Mitte", "Neukölln", "Pankow",
"Reinickendorf", "Spandau", "Steglitz-Zehlendorf",
"Tempelhof-Schöneberg", "Treptow-Köpenick"),
flaeche_km2 = c(64.72, 20.16, 52.29, 61.74, 39.47, 44.93, 103.07,
89.46, 91.91, 102.50, 53.09, 168.42)
)
df_agg <- df_merged %>%
filter(!is.na(bezirk)) %>%
group_by(bezirk) %>%
summarise(total_trees = n_distinct(gml_id)) %>%
ungroup() %>%
left_join(bezirk_flaeche, by = "bezirk") %>%
mutate(density = total_trees / flaeche_km2) %>%
arrange(desc(density))
ggplot(df_agg, aes(x = reorder(bezirk, -density), y = density, fill = bezirk)) +
geom_bar(stat = "identity", color = "white", alpha = 0.7) +
labs(
title = NULL,
x = "Bezirk",
y = "Bäume pro km²"
) +
theme_light() +
theme(
legend.position = "none",
axis.text.x = element_text(angle = 45, hjust = 1, size = 10),
panel.grid.major.x = element_blank()
) +
scale_fill_discrete()
})
# Info button
observeEvent(input$info_btn_bdpf, {
showModal(modalDialog(
title = "Information: Baumdichte pro km²",
HTML("
<p>Diese Grafik zeigt die <strong>Baumdichte</strong> in jedem Bezirk normalisiert auf die Fläche.</p>
<ul>
<li>Berechnung: Anzahl Bäume / Bezirksfläche in km²</li>
<li>Ermöglicht fairen Vergleich zwischen großen und kleinen Bezirken</li>
<li>Hohe Dichte = urbaner, mehr Straßenbäume</li>
<li>Niedrige Dichte = ländlicher, mehr Wald/Parkflächen</li>
</ul>
"),
easyClose = TRUE,
footer = modalButton("Schließen")
))
})
Erklärung des Codes
Flächendaten hinzufügen:
Eine kleine Lookup-Tabelle (
bezirk_flaeche) enthält die Fläche jedes Bezirks in km²left_join(bezirk_flaeche, by = "bezirk")– verknüpft diese Flächenangaben mit den Baumdaten
Dichte berechnen:
group_by(bezirk)– gruppiert nach Bezirksummarise(total_trees = n_distinct(gml_id))– zählt eindeutige Bäume pro Bezirkmutate(density = total_trees / flaeche_km2)– berechnet Bäume pro km²arrange(desc(density))– sortiert absteigend nach Dichte
Balkendiagramm:
reorder(bezirk, -density)– sortiert Bezirke nach DichteDas Diagramm zeigt, welche Bezirke besonders dicht bepflanzt sind (z. B. urbane Zentren) und welche eher locker (z. B. Randbezirke mit viel Grünfläche)
Diese Normalisierung ermöglicht faire Vergleiche: Ein kleiner, urbaner Bezirk kann trotz weniger Bäume eine höhere Dichte haben als ein großer, ländlicher Bezirk.
Die 10 meistgegossenen Baumgattungen#
Diese Visualisierung zeigt, welche Baumgattungen am häufigsten gegossen wurden. Das hilft zu verstehen, ob bestimmte Gattungen mehr Aufmerksamkeit erhalten, möglicherweise weil sie häufiger vorkommen oder als besonders pflegebedürftig wahrgenommen werden.
Code
# 4. Die 10 meistgegossenen Baumgattungen
output$top_watered_species <- renderPlot({
req(input$sidebarMenu == "engagement")
filtered_data <- df_merged %>%
filter(!is.na(bewaesserungsmenge_in_liter))
if (input$engagement_bezirk != "Alle Bezirke") {
filtered_data <- filtered_data %>%
filter(bezirk == input$engagement_bezirk)
}
df_agg <- filtered_data %>%
filter(!is.na(gattung_deutsch)) %>%
group_by(gattunTop 10g_deutsch) %>%
summarise(
count = n(),
total_water = sum(bewaesserungsmenge_in_liter, na.rm = TRUE)
) %>%
ungroup() %>%
arrange(desc(count)) %>%
head(10)
ggplot(df_agg, aes(x = reorder(gattung_deutsch, count), y = count, fill = gattung_deutsch)) +
geom_bar(stat = "identity", color = "white", alpha = 0.7) +
coord_flip() +
labs(
title = NULL,
x = "Baumgattung",
y = "Anzahl gegossener Bäume"
) +
theme_light() +
theme(
legend.position = "none",
panel.grid.major.y = element_blank()
) +
scale_fill_discrete()
})
# Info button
observeEvent(input$info_btn_hgb, {
showModal(modalDialog(
title = "Information: Die 10 meistgegossenen Baumgattungen",
HTML("
<p>Diese Grafik zeigt die <strong>am häufigsten gegossenen Baumgattungen</strong>.</p>
<ul>
<li>Nur Bäume, die tatsächlich bewässert wurden</li>
<li>Zeigt, welche Gattungen am meisten Unterstützung erhalten</li>
<li>Kann auf einzelne Bezirke gefiltert werden</li>
<li>Hilft zu verstehen, welche Gattungen besondere Aufmerksamkeit bekommen</li>
</ul>
"),
easyClose = TRUE,
footer = modalButton("Schließen")
))
})
Erklärung des Codes
Nur gegossene Bäume berücksichtigen:
filter(!is.na(bewaesserungsmenge_in_liter))– behalte nur Bäume, die tatsächlich bewässert wurdenOptional: Filterung nach Bezirk, falls ausgewählt
Die 10 meistgegossenen Baumgattungen ermitteln:
group_by(gattung_deutsch)– gruppiert nach Gattungsummarise(count = n(), total_water = sum(...))– berechnet zwei Kennzahlen:count– wie viele Bäume dieser Gattung gegossen wurdentotal_water– wie viel Wasser insgesamt auf diese Gattung gegossen wurde
arrange(desc(count))– sortiert absteigend nach Häufigkeithead(10)– wählt die 10 meistgegossenen Baumgattungen
Horizontales Balkendiagramm:
coord_flip()– dreht das Diagramm um 90°, sodass Gattungsnamen gut lesbar sindreorder(gattung_deutsch, count)– sortiert Gattungen nach Anzahl gegossener Bäume
Diese Visualisierung macht sichtbar, welche Gattungen die meiste Aufmerksamkeit erhalten – allerdings korreliert dies stark mit der Verbreitung der jeweiligen Gattung im Stadtbild.
5.6.3. Reflexion#
Kritische Diskussion#
Die Analyse zeigt deutlich, dass bestimmte Baumgattungen besonders oft im Berliner Baumbestand vorkommen. Ahorn, Linde und Eiche machen berlinweit gemeinsam rund 57,4 % aller Straßenbäume aus, wohingegen sich alle anderen Baumgattungen 42,6% teilen. Das bedeutet, dass viele Muster der Verteilung zwangsläufig von dieser einen Gattung geprägt werden.
Hinsichtlich des Engagements der Bürger:innen besitzen die Baumgattungen jedoch nur einen begrenzten Erklärungswert. Zwar zeigt sich, dass bestimmte Gattungen besonders häufig bewässert werden, dies steht jedoch vor allem im Zusammenhang mit ihrer allgemeinen Verbreitung im Berliner Stadtbild. Dass beispielsweise Linden besonders häufig gegossen werden, lässt sich daher in erster Linie durch ihre hohe Präsenz erklären und nicht zwangsläufig durch eine erhöhte Pflegebedürftigkeit oder besondere Beliebtheit. Die Betrachtung der Baumgattungen liefert zwar zusätzliche interessante Einblicke, trägt jedoch nur eingeschränkt dazu bei, das Bewässerungsengagement der Bürger:innen zu erklären.
Beim Vergleich der Bezirke zeigen sich deutliche Unterschiede in der Baumdichte. Friedrichshain-Kreuzberg und Mitte weisen die höchsten Baumdichten pro km² auf, es handelt sich um kompakte, urbane Bezirke. Gleichzeitig besitzen Steglitz-Zehlendorf, Pankow und Marzahn-Hellersdorf die größten absoluten Baumzahlen, was vor allem auf großflächige Areale mit Mischbeständen und Gehölzflächen zurückzuführen ist.
Setzt man diese Befunde in Beziehung zu den Daten darüber, in welchen Bezirken besonders viel gegossen wurde, deutet sich ein mögliches Muster an: Die beiden Bezirke mit der höchsten Baumdichte pro Quadratkilometer weisen zugleich auch den höchsten Anteil bewässerter Bäume auf. Eine vorschnelle Schlussfolgerung könnte darin bestehen anzunehmen, dass in dichter besiedelten Bezirken wie Friedrichshain-Kreuzberg und Mitte mehr Menschen auf engem Raum mit Straßenbäumen in Kontakt kommen und dadurch häufiger die Möglichkeit nutzen, diese zu bewässern. Eine solche Interpretation sollte jedoch mit größter Vorsicht betrachtet werden.
Bislang wurden lediglich zwei Variablen, nämlich Baumdichte und Anteil bewässerter Bäume, miteinander in Beziehung gesetzt. Aus diesen beiden Variablen lässt sich zwar eine Korrelation ableiten, jedoch kein kausaler Zusammenhang! Auf Grundlage der bisherigen Analyse kann daher nicht beurteilt werden, inwieweit eine hohe Baumdichte tatsächlich mit einem erhöhten Bewässerungsengagement zusammenhängt. Ebenso denkbar sind alternative Einflussfaktoren, etwa Unterschiede in der Bevölkerungsdichte, der sozialen Struktur, lokalen Initiativen oder der allgemeinen Sensibilisierung für städtische Umweltfragen.
Kernbotschaft: Die Analyse zeigt, dass das Bewässerungsengagement der Bürger:innen weniger von bestimmten Baumgattungen als eher von räumlichen und strukturellen Eigenschaften der Bezirke beeinflusst zu sein scheint. Besonders Bezirke mit hoher Baumdichte weisen tendenziell auch höhere Bewässerungsaktivitäten auf. Ob hier tatsächlich ein kausaler Zusammenhang besteht, kann durch die vorliegende Betrachtung jedoch keinesfalls belegt werden.
Gesamter Code für diesen Schritt
# UI-Definition
ui <- dashboardPage(
dashboardHeader(title = "Gieß den Kiez Dashboard"),
dashboardSidebar(
sidebarMenu( id = "sidebarMenu",
# Code aus den vorherigen Schritten
menuItem("Startseite", tabName = "start", icon = icon("home")),
menuItem("Karte", tabName = "map", icon = icon("map")),
menuItem("Bewässerungsanalyse", tabName = "analysis", icon = icon("chart-area")),
menuItem("Zeitverlauf", tabName = "stats", icon = icon("bar-chart")),
# NEU: Navigation für die Baumstatistik
menuItem("Baumstatistik", tabName = "engagement", icon = icon("hands-helping"))
)
),
dashboardBody(
tabItems(
# ... Code aus Startseite, Karte, Bewässerungsanalyse & Zeitverlauf (tabItem für "start", "map", "analysis" & "stats") ...
# NEU: Inhaltsbereich für die Baumstatistik
tabItem(
tabName = "engagement",
fluidRow(
box(
title = tagList(
"Baumverteilung nach Bezirken (mit Baumgattungen)",
div(
actionButton("info_btn_bvnb", label = "", icon = icon("info-circle")),
style = "position: absolute; right: 15px; top: 5px;"
)
),
status = "primary",
solidHeader = TRUE,
width = 12,
sliderInput(
"top_n_species",
"Ändern Sie den Detailgrad der Auffächerung, indem Sie mit dem Schieberegler die Anzahl an Baumgattungen bestimmen (sortiert nach Häufigkeit - absteigend)",
min = 3,
max = 15,
value = 8,
step = 1
),
plotOutput("tree_distribution_stacked", height = "500px")
)
),
fluidRow(
box(
title = tagList(
"Verteilung der Baumgattungen",
div(
actionButton("info_btn_vdb", label = "", icon = icon("info-circle")),
style = "position: absolute; right: 15px; top: 5px;"
)
),
status = "primary",
solidHeader = TRUE,
width = 12,
selectInput(
"pie_bezirk",
"Bezirk auswählen:",
choices = c("Alle Bezirke", sort(unique(df_merged$bezirk))),
selected = "Alle Bezirke"
),
plotOutput("tree_species_pie", height = "500px")
),
box(
title = tagList(
"Baumdichte pro km²",
div(
actionButton("info_btn_bdpf", label = "", icon = icon("info-circle")),
style = "position: absolute; right: 15px; top: 5px;"
)
),
status = "primary",
solidHeader = TRUE,
width = 12,
plotOutput("tree_density_area", height = "500px")
)
),
fluidRow(
box(
title = tagList(
"Die 10 meistgegossenen Baumgattungen",
div(
actionButton("info_btn_hgb", label = "", icon = icon("info-circle")),
style = "position: absolute; right: 15px; top: 5px;"
)
),
status = "primary",
solidHeader = TRUE,
width = 12,
selectInput(
"engagement_bezirk",
"Bezirk auswählen:",
choices = c("Alle Bezirke", sort(unique(df_merged$bezirk))),
selected = "Alle Bezirke"
),
plotOutput("top_watered_species", height = "500px")
)
)
)
)
)
)
# Server-Logik
server <- function(input, output, session) {
# ... Code aus der Startseite, Karte, Bewässerungsanalyse und Zeitverlauf ...
# 1. Stacked Bar Chart - Baumverteilung mit Gattungen
output$tree_distribution_stacked <- renderPlot({
req(input$sidebarMenu == "engagement")
n_gen <- input$top_n_species
top_genera <- df_merged %>%
filter(!is.na(gattung_deutsch)) %>%
count(gattung_deutsch, sort = TRUE) %>%
head(n_gen) %>%
pull(gattung_deutsch)
df_agg <- df_merged %>%
filter(!is.na(bezirk)) %>%
mutate(gattung_grouped = ifelse(gattung_deutsch %in% top_genera, gattung_deutsch, "Sonstige")) %>%
group_by(bezirk, gattung_grouped) %>%
summarise(count = n(), .groups = "drop") %>%
group_by(bezirk) %>%
mutate(percentage = count / sum(count) * 100) %>%
ungroup()
df_agg$gattung_grouped <- factor(df_agg$gattung_grouped,
levels = c(top_genera, "Sonstige"))
# "Sonstige" bekommt Grau; Rest aus globaler Palette
fill_vals <- c(colorRampPalette(GDK_PALETTE_BASE)(input$top_n_species), "#D3D3D3")
names(fill_vals) <- c(top_genera, "Sonstige")
ggplot(df_agg, aes(x = reorder(bezirk, count, sum), y = count, fill = gattung_grouped)) +
geom_bar(stat = "identity", position = "stack", color = "white", linewidth = 0.3) +
scale_fill_manual(values = fill_vals, name = "Baumgattung") +
labs(x = "Bezirk", y = "Anzahl Bäume") +
theme_light() +
theme(
axis.text.x = element_text(angle = 45, hjust = 1, size = 10),
legend.position = "right",
panel.grid.major.x = element_blank()
)
})
observeEvent(input$info_btn_bvnb, {
showModal(modalDialog(
title = "Information: Baumverteilung nach Bezirken",
HTML("
<p>Diese Grafik zeigt die <strong>Gesamtanzahl und Zusammensetzung der Bäume</strong> in jedem Berliner Bezirk nach Gattung.</p>
<ul>
<li>Jeder Balken zeigt die Gesamtzahl der Bäume im Bezirk</li>
<li>Nutzen Sie den Slider, um mehr oder weniger Gattungen anzuzeigen</li>
</ul>
"),
easyClose = TRUE,
footer = modalButton("Schließen")
))
})
# 2. Pie Chart - Gattungsverteilung
output$tree_species_pie <- renderPlot({
req(input$sidebarMenu == "engagement")
filtered_data <- df_merged
if (input$pie_bezirk != "Alle Bezirke") {
filtered_data <- filtered_data %>%
filter(bezirk == input$pie_bezirk)
}
df_agg <- filtered_data %>%
filter(!is.na(gattung_deutsch)) %>%
count(gattung_deutsch, sort = TRUE) %>%
mutate(
gattung_grouped = ifelse(row_number() <= 10, gattung_deutsch, "Sonstige")
) %>%
group_by(gattung_grouped) %>%
summarise(count = sum(n), .groups = "drop") %>%
arrange(desc(count)) %>%
mutate(
percentage = count / sum(count) * 100,
label = paste0(gattung_grouped, "\n", round(percentage, 1), "%")
)
n_slices <- nrow(df_agg)
has_sonst <- "Sonstige" %in% df_agg$gattung_grouped
n_named <- if (has_sonst) n_slices - 1 else n_slices
fill_vals <- c(colorRampPalette(GDK_PALETTE_BASE)(n_named),
if (has_sonst) "#D3D3D3" else NULL)
names(fill_vals) <- df_agg$gattung_grouped
ggplot(df_agg, aes(x = "", y = count, fill = gattung_grouped)) +
geom_bar(stat = "identity", width = 1, color = "white", linewidth = 0.5) +
coord_polar("y", start = 0) +
scale_fill_manual(values = fill_vals, name = "Baumgattung") +
labs(title = NULL) +
theme_void() +
theme(
legend.position = "right",
legend.text = element_text(size = 9)
) +
geom_text(aes(label = ifelse(percentage > 3, paste0(round(percentage, 1), "%"), "")),
position = position_stack(vjust = 0.5), color = "white",
fontface = "bold", size = 3.5)
})
observeEvent(input$info_btn_vdb, {
showModal(modalDialog(
title = "Information: Verteilung der Baumgattungen",
HTML("
<p>Diese Grafik zeigt die <strong>prozentuale Verteilung der Baumgattungen</strong>.</p>
<ul>
<li>Zeigt die 10 meistgegossenen Baumgattungen (z.B. LINDE, AHORN, EICHE)</li>
<li>Hilft zu verstehen, welche Gattungen in Berlin dominieren</li>
</ul>
"),
easyClose = TRUE,
footer = modalButton("Schließen")
))
})
# 3. Baumdichte pro Bezirksfläche
output$tree_density_area <- renderPlot({
req(input$sidebarMenu == "engagement")
bezirk_flaeche <- data.frame(
bezirk = c("Charlottenburg-Wilmersdorf", "Friedrichshain-Kreuzberg", "Lichtenberg",
"Marzahn-Hellersdorf", "Mitte", "Neukölln", "Pankow",
"Reinickendorf", "Spandau", "Steglitz-Zehlendorf",
"Tempelhof-Schöneberg", "Treptow-Köpenick"),
flaeche_km2 = c(64.72, 20.16, 52.29, 61.74, 39.47, 44.93, 103.07,
89.46, 91.91, 102.50, 53.09, 168.42)
)
df_agg <- df_merged %>%
filter(!is.na(bezirk)) %>%
group_by(bezirk) %>%
summarise(total_trees = n_distinct(gml_id)) %>%
ungroup() %>%
left_join(bezirk_flaeche, by = "bezirk") %>%
mutate(density = total_trees / flaeche_km2) %>%
arrange(desc(density))
ggplot(df_agg, aes(x = reorder(bezirk, -density), y = density, fill = bezirk)) +
geom_bar(stat = "identity", color = "white", alpha = 0.7) +
labs(
title = NULL,
x = "Bezirk",
y = "Bäume pro km²"
) +
theme_light() +
theme(
legend.position = "none",
axis.text.x = element_text(angle = 45, hjust = 1, size = 10),
panel.grid.major.x = element_blank()
) +
scale_fill_discrete()
})
# Info button
observeEvent(input$info_btn_bdpf, {
showModal(modalDialog(
title = "Information: Baumdichte pro km²",
HTML("
<p>Diese Grafik zeigt die <strong>Baumdichte</strong> in jedem Bezirk normalisiert auf die Fläche.</p>
<ul>
<li>Berechnung: Anzahl Bäume / Bezirksfläche in km²</li>
<li>Ermöglicht fairen Vergleich zwischen großen und kleinen Bezirken</li>
<li>Hohe Dichte = urbaner, mehr Straßenbäume</li>
<li>Niedrige Dichte = ländlicher, mehr Wald/Parkflächen</li>
</ul>
"),
easyClose = TRUE,
footer = modalButton("Schließen")
))
})
# 4. Die 10 meistgegossenen Baumgattungen
output$top_watered_species <- renderPlot({
req(input$sidebarMenu == "engagement")
filtered_data <- df_merged %>%
filter(!is.na(bewaesserungsmenge_in_liter))
if (input$engagement_bezirk != "Alle Bezirke") {
filtered_data <- filtered_data %>%
filter(bezirk == input$engagement_bezirk)
}
df_agg <- filtered_data %>%
filter(!is.na(gattung_deutsch)) %>%
group_by(gattung_deutsch) %>%
summarise(
count = n(),
total_water = sum(bewaesserungsmenge_in_liter, na.rm = TRUE)
) %>%
ungroup() %>%
arrange(desc(count)) %>%
head(10)
ggplot(df_agg, aes(x = reorder(gattung_deutsch, count), y = count, fill = gattung_deutsch)) +
geom_bar(stat = "identity", color = "white", alpha = 0.7) +
coord_flip() +
labs(
title = NULL,
x = "Baumgattung",
y = "Anzahl gegossener Bäume"
) +
theme_light() +
theme(
legend.position = "none",
panel.grid.major.y = element_blank()
) +
scale_fill_discrete()
})
observeEvent(input$info_btn_hgb, {
showModal(modalDialog(
title = "Information: Die 10 meistgegossenen Baumgattungen",
HTML("
<p>Diese Grafik zeigt die <strong>am häufigsten gegossenen Baumgattungen</strong>.</p>
<ul>
<li>Nur Bäume, die tatsächlich bewässert wurden</li>
<li>Zeigt, welche Gattungen am meisten Unterstützung erhalten</li>
<li>Kann auf einzelne Bezirke gefiltert werden</li>
<li>Hilft zu verstehen, welche Gattungen besondere Aufmerksamkeit bekommen</li>
</ul>
"),
easyClose = TRUE,
footer = modalButton("Schließen")
))
})
}
shinyApp(ui = ui, server = server)
Übung#
Auf dieser Seite wurden mehrere Balkendiagramme sowie ein Kreisdiagramm verwendet. Beide Visualisierungsformen dienen dazu, Unterschiede und Gemeinsamkeiten zwischen verschiedenen Werten darzustellen. Während Balkendiagramme auf einem Achsenvergleich basieren und Werte entlang einer Skala vergleichbar machen, zählt das Kreisdiagramm zu den Darstellungsformen ohne Achsenvergleich. Hier dient der Kreis beziehungsweise dessen Gesamtfläche als Bezugspunkt für die einzelnen Anteile.
Die Plattform stellt verschiedene Visualisierungsmethoden vor, die zeigen, wie Unterschiede oder Gemeinsamkeiten zwischen Werten dargestellt werden können. Entdecken Sie zusätzliche Möglichkeiten zur Visualisierung solcher Vergleiche, unterteilt in Darstellungen mit und ohne Achsenvergleich.
Überlegen Sie kritisch:
Präferieren Sie die hier verwendeten Visualisierungen oder würden Sie alternative Darstellungsformen wählen? Welche Argumente sprechen jeweils für oder gegen die unterschiedlichen Visualisierungsmethoden?