
5.4. Eine Bewässerungsanalyse einfügen#
Story
Nachdem Amir mithilfe der Bezirkskarte herausgefunden hat, in welchen Teilen Berlins besonders viele Bäume gegossen wurden, stellt er sich eine neue Frage: Reicht es wirklich aus, nur zu zählen, wie viele Bäume gegossen wurden?
Er merkt schnell: Diese Darstellung zeigt zwar den Umfang des Engagements, aber nicht die Intensität der Bewässerung. So könnten die Bürger:innen eines Bezirks eine große Anzahl von Bäumen gegossen haben, dabei jedoch jeweils nur geringe Wassermengen eingesetzt haben. In einem anderen Bezirk könnten hingegen weniger Bäume bewässert worden sein, die Bürger:innen hätten dafür jedoch deutlich größere Wassermengen pro Baum herangeschleppt und damit einen höheren Aufwand pro Baum betrieben.
Zweck dieser Übung
Diese Übung zeigt Ihnen, wie sich durch unterschiedliche Kennzahlen neue Perspektiven auf eine Fragestellung ergeben. Während zuvor die Zahl der gegossenen Bäume im Mittelpunkt stand, analysieren Sie nun die Bewässerungsmenge in Litern.
Sie lernen dabei, wie Daten aggregiert, umgerechnet und visualisiert werden können, um Bezirke hinsichtlich ihrer gesamten Bewässerungsleistung oder der durchschnittlichen Wassermenge pro Baum zu vergleichen. Dadurch wird deutlich, dass die Auswahl der Messgröß (die Operationalisierung) zu verschiedenen analytischen Ergebnissen führen kann: Ein Bezirk, der bei der Anzahl gegossener Bäume gut abschneidet, liegt bei der Wassermenge möglicherweise nicht vorne (und umgekehrt).
Um die Unterschiede sichtbar zu machen, führen Sie eine umfassendere Analyse der Bewässerungsmenge durch:
Wie viel Wasser wurde insgesamt pro Bezirk ausgebracht?
Wie viel Wasser erhielt ein durchschnittlich gegossener Baum?
Und verändert sich dadurch das Ranking der Bezirke?
So helfen Sie Amir zu verstehen, wie sich die Wahl der Operationalisierung, also „gezählte Bäume“ vs. „gegossene Liter“, auf die Ergebnisse auswirkt. Die Frage lautet: Welche Geschichte erzählen die Daten, wenn man Liter statt Baumanzahl betrachtet?
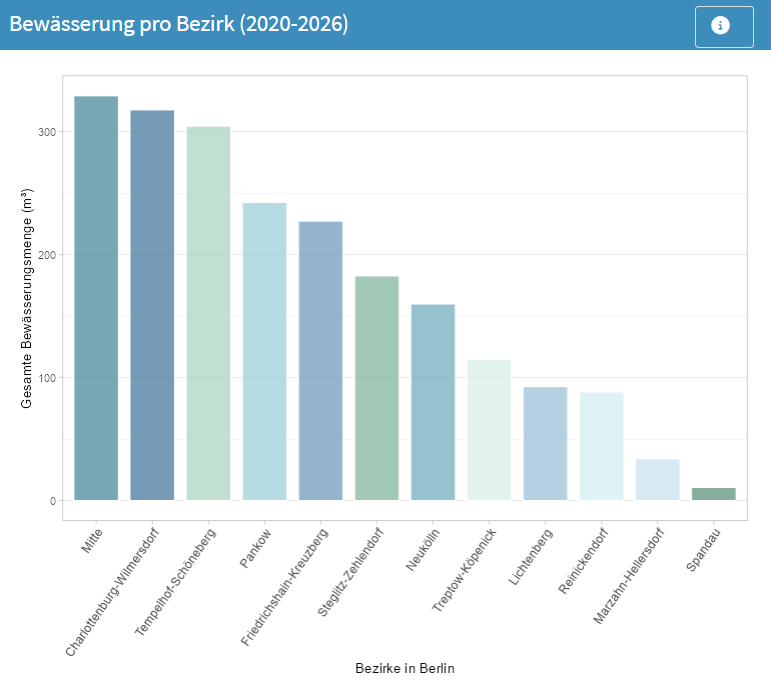
Abb. 5.7 Balkendiagramm zur Bewässerung pro Bezirk (hier 2020 bis 03/2026). Die Abbildung zeigt die aggregierte Bewässerungsmenge in Millionen Litern für die einzelnen Berliner Bezirke. Auf der x-Achse sind die Bezirke dargestellt, während die y-Achse die gesamte Bewässerungsmenge angibt. Das Diagramm ermöglicht einen direkten Vergleich der Bewässerungsintensität zwischen den Bezirken. (Quelle: eigene Ausarbeitung)#
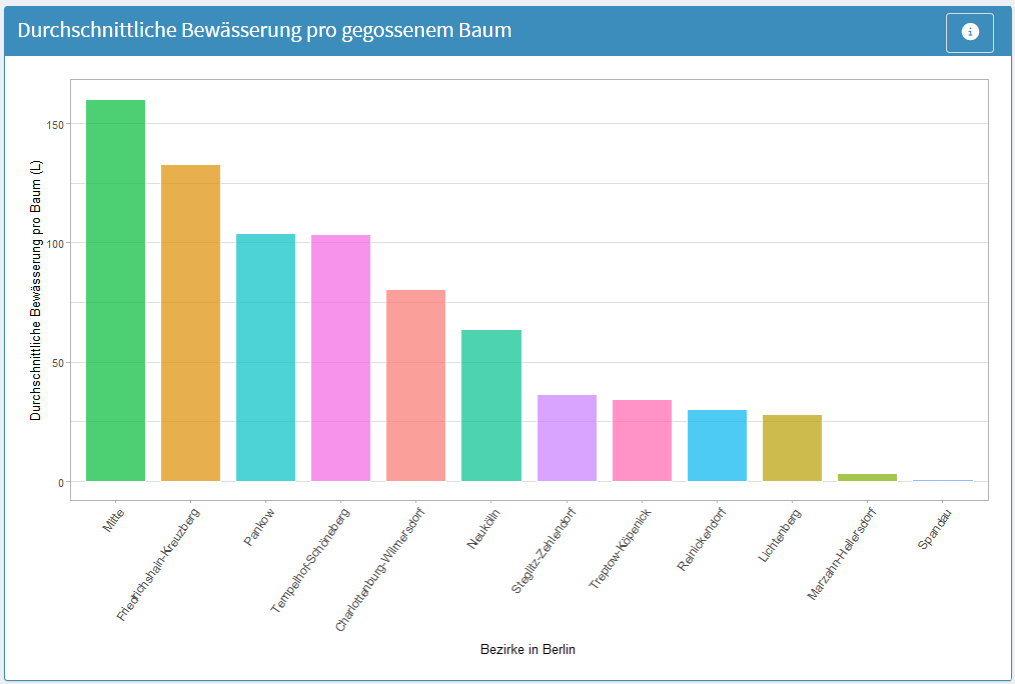
Abb. 5.8 Durchschnittliche Bewässerungsmenge pro gegossenem Baum nach Bezirk (hier 2020 bis 03/2026). Die Abbildung zeigt die durchschnittliche Bewässerungsmenge pro gegossenem Baum in Litern für die einzelnen Berliner Bezirke. Auf der x-Achse sind die Bezirke dargestellt, während die y-Achse die durchschnittliche Bewässerungsmenge pro Baum angibt. Das Balkendiagramm verdeutlicht Unterschiede in der Bewässerungsintensität zwischen den Bezirken. (Quelle: eigene Ausarbeitung)#
5.4.1. Benutzeroberfläche (UI)#
Zunächst fügen Sie einen weiteren Menüpunkt zur Navigation hinzu, um den Bewässerungsanalyse-Tab zugänglich zu machen.
Navigation in der Seitenleiste
dashboardSidebar(
sidebarMenu( id = "sidebarMenu",
menuItem("Startseite", tabName = "start", icon = icon("home")),
menuItem("Karte", tabName = "map", icon = icon("map")),
# NEU: Menüpunkt für die Bewässerungsanalyse hinzufügen
menuItem("Bewässerungsanalyse", tabName = "analysis", icon = icon("chart-area"))
)
)
Inhaltsbereich: Diagramme#
Der Inhaltsbereich enthält die Diagramme. Da die Tabellen hier fest vorgegeben sind (für ganz Berlin vergleichend), benötigen Sie für diese Seite keine Filter-Dropdowns.
Code
tabItem(
tabName = "analysis",
fluidRow(
box(
title = tagList(
"Bewässerung pro Bezirk",
div(
actionButton("info_btn_hbpb", label = "", icon = icon("info-circle")),
style = "position: absolute; right: 15px; top: 5px;"
)
),
status = "primary",
solidHeader = TRUE,
width = 12,
plotOutput("hist_bewaesserung_pro_bezirk", height = "500px")
)
),
fluidRow(
box(
title = tagList(
"Durchschnittliche Bewässerung pro gegossenem Baum",
div(
actionButton("info_btn_hbpb2", label = "", icon = icon("info-circle")),
style = "position: absolute; right: 15px; top: 5px;"
)
),
status = "primary",
solidHeader = TRUE,
width = 12,
plotOutput("hist_bewaesserung_pro_baum", height = "500px")
)
)
)
Erklärung der Elemente
tagList(...): Wird genutzt, um mehrere UI-Elemente im Titel der Box zu kombinieren – hier der Titeltext und der Informations-Button. So kann der Info-Button elegant im Titelbereich platziert werden.actionButton: Erstellt einen klickbaren Button. Dieser Button wird später dazu genutzt, kontextbezogene Erklärungen oder Hilfetexte zu öffnen (z. B. viaobserveEvent()+showModal()). Der Button hat die ID"info_btn_hbpb"und wird später verwendet, um eine Erklärung zur Grafik anzuzeigen. Gleiches gilt für"info_btn_hbpb2".plotOutput(...): Platzhalter für ein Diagramm, das im Server-Teil gerendert wird.hist_bewaesserung_pro_bezirkzeigt die Gesamtwassermenge pro Bezirk.hist_bewaesserung_pro_baumzeigt die durchschnittliche Wassermenge pro gegossenem Baum.
5.4.2. Server#
Einheiten clever umrechnen#
Bei der Darstellung von Wassermengen stehen Sie vor einer Herausforderung: Die Rohdaten enthalten Literangaben, die je nach Größenordnung unterschiedlich formatiert werden sollten. Eine Menge von 50 Litern ist überschaubar, aber 1.250.000 Liter sind schwer zu erfassen.
Von Vorteil wäre es, wenn das Dashboard automatisch in sinnvolle Einheiten umrechnet, wie etwa Kubikmeter (m³) oder Megaliter (ML). Um dies zu erreichen, erstellen Sie zunächst Hilfsfunktionen für die Umrechnung und wenden diese anschließend direkt auf Ihren aggregierten Datensatz an.
Code
# Hilfsfunktion für Einheiten
convert_units <- function(liters) {
if (liters >= 1e6) {
return(list(value = round(liters / 1e6, 2), unit = "ML"))
} else if (liters >= 1e3) {
return(list(value = round(liters / 1e3, 2), unit = "m³"))
} else {
return(list(value = round(liters, 2), unit = "L"))
}
}
full_unit <- function(unit) {
switch(unit,
"ML" = "Mega Liter",
"L" = "Liter",
"m³" = "Kubikmeter",
unit)
}
df_agg <- df_agg %>%
mutate(
converted = purrr::map(total_water, convert_units),
value = sapply(converted, `[[`, "value"),
unit = sapply(converted, `[[`, "unit")
)
Erklärung des Codes
1. Die Hilfsfunktionen erstellen:
convert_units(liters): Nimmt einen Wert in Litern entgegen und entscheidet anhand der Größenordnung über die Einheit:if (liters >= 1e6)– 1.000.000 Liter oder mehr werden zu Megaliter (ML).else if (liters >= 1e3)– 1.000 Liter oder mehr werden zu Kubikmeter (m³).else– Kleinere Mengen bleiben Liter (L).Die Funktion gibt eine Liste mit dem gerundeten Wert (
value) und der Einheit (unit) zurück.
full_unit(unit): Wandelt Kurzformen (wie „ML“) mithilfe vonswitch()in ausgeschriebene Bezeichnungen („Mega Liter“) um, falls dies später für die Anzeige benötigt wird.
2. Auf den Datensatz anwenden:
purrr::map(total_water, convert_units): Wendet die gerade erstellte Funktionconvert_unitsauf jede Zeile der Spaltetotal_wateran. Das Ergebnis ist eine neue Spalteconverted, die aus Listen besteht.sapply(converted,[[, "value"): Extrahiert gezielt den numerischen Wert aus diesen Listen und speichert ihn in der neuen Spaltevalue.sapply(converted,[[, "unit"): Extrahiert analog dazu die berechnete Einheit und speichert sie in der Spalteunit.
Warum ist das wichtig?
Ohne Umrechnung wären große Zahlen wie „2.500.000 L“ im Dashboard schwer zu erfassen. Durch diese Kombination aus Hilfsfunktion und mutate wird daraus automatisch ein übersichtliches „2,5 ML“.
Berechnung der Bewässerung#
Im ersten Teil des Codes, der die durchschnittliche Bewässerung pro Bezirk darstellt, berechnen Sie, wie viel Wasser insgesamt in jedem Bezirk verbraucht wurde.
Code
output$hist_bewaesserung_pro_bezirk <- renderPlot({
req(input$sidebarMenu == "analysis")
df_agg <- df_merged %>%
filter(!is.na(bezirk)) %>%
group_by(bezirk) %>%
summarise(total_water = sum(bewaesserungsmenge_in_liter, na.rm = TRUE)) %>%
ungroup() %>%
arrange(desc(total_water))
Erklärung des Codes
Daten aggregieren:
req(input$sidebarMenu == "analysis")– rendert den Plot nur, wenn der Tab aktiv istfilter(!is.na(bezirk))– entfernt Einträge ohne Bezirksangabegroup_by(bezirk)– gruppiert alle Bäume nach Bezirksummarise(total_water = sum(...))– berechnet die Gesamtwassermenge pro Bezirkungroup()– löst die Gruppierung aufarrange(desc(total_water))– sortiert Bezirke absteigend nach Wassermenge
Durch diese Aggregation wird sichtbar, welche Bezirke absolut gesehen die meisten Liter Wasser auf ihre Bäume gegossen haben.
Balkendiagramm erstellen#
Mit den aggregierten und umgerechneten Daten erstellt Amir nun das Balkendiagramm.
Code
# Create plot
ggplot(df_agg, aes(x = reorder(bezirk, -value), y = value, fill = bezirk)) +
geom_bar(stat = "identity", color = "white", alpha = 0.7, width = 0.8) +
labs(
title = NULL,
x = "Bezirke in Berlin",
y = paste0("Gesamte Bewässerungsmenge (", unique(df_agg$unit), ")")
) +
theme_light() +
theme(
legend.position = "none",
axis.text.x = element_text(angle = 55, hjust = 1, size = 10),
panel.grid.major.x = element_blank(),
plot.margin = margin(10, 10, 10, 10)
) +
scale_fill_discrete(name = "Bezirk")
})
# Info button observer
observeEvent(input$info_btn_hbpb, {
showModal(modalDialog(
title = "Information: Bewässerung pro Bezirk",
HTML("
<p>Diese Grafik zeigt die <strong>gesamte Bewässerungsmenge</strong> für jeden Berliner Bezirk.</p>
<ul>
<li>Die Daten werden automatisch in die passende Einheit (Liter, m³ oder Megaliter) umgerechnet</li>
<li>Die Bezirke werden entlang der x-Achse dargestellt</li>
<li>Die Höhe der Balken entspricht der gesamten Bewässerungsmenge</li>
</ul>
"),
easyClose = TRUE,
footer = modalButton("Schließen")
))
})
Erklärung des Codes
Balkendiagramm aufbauen:
reorder(bezirk, -value)– sortiert Bezirke absteigend nach Wassermengey = value– die umgerechnete Wassermenge auf der y-Achsefill = bezirk– jeder Bezirk erhält eine eigene Farbestat = "identity"– die Balkenhöhe entspricht direkt dem Wertcolor = "white", alpha = 0.7– weiße Umrandung und leichte Transparenz für bessere Lesbarkeitwidth = 0.8– schmalere Balken für übersichtlichere Darstellung
Achsenbeschriftung:
title = NULL– kein Titel, da dieser bereits in der Box stehtx = "Bezirke in Berlin"– Beschriftung der x-Achsey = paste0(...)– dynamische y-Achsenbeschriftung mit der passenden Einheit (automatisch ML, m³ oder L)
Design:
theme_light()– helles, sauberes Layoutlegend.position = "none"– keine Legende notwendigaxis.text.x = element_text(angle = 55, ...)– Bezirksnamen schräg gestellt, um Überlappungen zu vermeidenpanel.grid.major.x = element_blank()– vertikale Gitterlinien entfernt für klareres Bildplot.margin = margin(10, 10, 10, 10)– ausreichend Abstand, damit Beschriftungen nicht abgeschnitten werden
Durchschnittliche Bewässerung pro Baum#
Das zweite Diagramm zeigt eine andere Perspektive: Statt der Gesamtmenge wird hier berechnet, wie viel Wasser durchschnittlich auf jeden gegossenen Baum kam. Das hilft zu verstehen, ob in einem Bezirk besonders intensiv oder eher oberflächlich gegossen wurde.
Code
# Plot: Durchschnittliche Bewässerung pro gegossenem Baum
output$hist_bewaesserung_pro_baum <- renderPlot({
req(input$sidebarMenu == "analysis")
df_agg <- df_merged %>%
filter(!is.na(bezirk)) %>%
group_by(bezirk) %>%
summarise(
total_water = sum(bewaesserungsmenge_in_liter, na.rm = TRUE),
trees_watered = n_distinct(gml_id)
) %>%
ungroup() %>%
mutate(water_per_tree = total_water / trees_watered) %>%
arrange(desc(water_per_tree))
df_agg <- df_agg %>%
mutate(
converted = purrr::map(water_per_tree, convert_units),
value = sapply(converted, `[[`, "value"),
unit = sapply(converted, `[[`, "unit")
)
ggplot(df_agg, aes(x = reorder(bezirk, -value), y = value, fill = bezirk)) +
geom_bar(stat = "identity", color = "white", alpha = 0.7, width = 0.8) +
labs(
title = NULL,
x = "Bezirke in Berlin",
y = paste0("Durchschnittliche Bewässerung pro Baum (", unique(df_agg$unit), ")")
) +
theme_light() +
theme(
legend.position = "none",
axis.text.x = element_text(angle = 55, hjust = 1, size = 10),
panel.grid.major.x = element_blank(),
plot.margin = margin(10, 10, 10, 10)
) +
scale_fill_discrete()
})
# Info button observer
observeEvent(input$info_btn_hbpb2, {
showModal(modalDialog(
title = "Information: Bewässerung pro gegossenem Baum",
HTML("
<p>Diese Grafik zeigt die <strong>durchschnittliche Bewässerungsmenge pro gegossenem Baum</strong> in jedem Bezirk.</p>
<ul>
<li>Berechnung: Gesamtwasser geteilt durch Anzahl der tatsächlich gegossenen Bäume</li>
<li>Zeigt die Intensität der Bewässerung und das Engagement der Bürger</li>
<li>Höhere Werte bedeuten mehr Wasser pro Baum, der Pflege erhielt</li>
</ul>
<p><strong>Wichtige Hinweise:</strong></p>
<ul>
<li>Vergleiche zwischen Bezirken müssen mit Vorsicht interpretiert werden</li>
<li>Baumalter, Arten und lokale Bedingungen variieren stark</li>
<li>Zeigt nicht Bäume, die Wasser brauchten aber keins erhielten</li>
</ul>
"),
easyClose = TRUE,
footer = modalButton("Schließen")
))
})
Erklärung des Codes
Die Struktur ist ähnlich wie beim ersten Diagramm, mit einigen wichtigen Unterschieden:
Zusätzliche Kennzahlen:
total_water = sum(...)– Gesamtwassermenge pro Bezirktrees_watered = n_distinct(gml_id)– zählt, wie viele unterschiedliche Bäume gegossen wurdenmutate(water_per_tree = total_water / trees_watered)– berechnet den Durchschnitt: Gesamtwasser geteilt durch Anzahl gegossener Bäume
Einheitenumrechnung:
Auch hier wird
convert_units()angewendet, um die Werte in passende Einheiten umzurechnenDie y-Achse zeigt dynamisch „Durchschnittliche Bewässerung pro Baum“ mit der automatisch gewählten Einheit
Interpretation:
Diese Kennzahl zeigt, wie intensiv die Bäume gegossen wurden. Ein Bezirk mit hoher Gesamtmenge kann eine niedrige Durchschnittsmenge pro Baum haben, wenn dort sehr viele Bäume nur leicht gegossen wurden. Umgekehrt kann ein Bezirk mit weniger Gesamtmenge eine hohe Durchschnittsmenge aufweisen, wenn dort wenige Bäume besonders intensiv versorgt wurden.
5.4.3. Kritische Schlussfolgerung#
Die Visualisierungen zeigen anschaulich, wie deutlich sich die Ergebnisse und folglich die Beantwortung der Leitfrage durch eine veränderte Operationalisierung verschieben können:
Bei der Gesamtbewässerungsmenge liegen nun Mitte, Charlottenburg-Wilmersdorf und Tempelhof-Schöneberg an der Spitze. Das deutet darauf hin, dass in diesen Bezirken besonders große Wassermengen eingesetzt wurden, sei es aufgrund vieler gegossener Bäume, hohem individuellem Einsatz oder besonderen lokalen Bedingungen.
Betrachtet man jedoch die durchschnittliche Bewässerungsmenge pro Baum, verschiebt sich das Bild: Hier tritt Friedrichshain-Kreuzberg am weitesten hervor.
Das zeigt klar: Die Wahl der Messgröße, also „Wie viel Wasser insgesamt?“ vs. „Wie viel Wasser pro Baum?“, beeinflusst die Interpretation des Engagements wesentlich. Unterschiedliche Kennzahlen können unterschiedliche Geschichten erzählen, auch sie auf denselben Rohdaten basieren.
Damit wird ein zentrales analytisches Prinzip deutlich: Daten sind nicht neutral. Die Art ihrer Aufbereitung formt das Narrativ.
Ergänzend zu der Leitfrage soll nun eine vertiefte Betrachtung der zugrunde liegenden Dynamiken und Kontextfaktoren erfolgen. Welche Kontextfaktoren könnten zu den Unterschieden geführt haben?
Zeitlich – etwa durch Veränderungen des Engagements im Jahresverlauf oder durch das Alter der Bäume (Kapitel 5.5)
Räumlich – beispielsweise durch Unterschiede in der Baumdichte eines Gebiets (Kapitel 5.6)
Daraus ergeben sich neue Fragen:
Welche zusätzlichen Datensätze lassen sich einbeziehen, um die Analyse zu vertiefen?
Wie können interaktive Dashboards mögliche Kontextfaktoren verständlich und vergleichbar darstellen?
Gesamter Code für diesen Schritt
# UI-Definition
ui <- dashboardPage(
dashboardHeader(title = "Gieß den Kiez Dashboard"),
dashboardSidebar(
sidebarMenu( id = "sidebarMenu",
menuItem("Startseite", tabName = "start", icon = icon("home")),
menuItem("Karte", tabName = "map", icon = icon("map")),
# NEU: Navigation für die Bewässerungsanalyse
menuItem("Bewässerungsanalyse", tabName = "analysis", icon = icon("chart-area"))
)
),
dashboardBody(
tabItems(
# ... tabItem für "start" und "map" ...
# NEU: Inhaltsbereich für die Bewässerungsanalyse
tabItem(
tabName = "analysis",
fluidRow(
box(
title = tagList(
"Bewässerung pro Bezirk",
div(
actionButton("info_btn_hbpb", label = "", icon = icon("info-circle")),
style = "position: absolute; right: 15px; top: 5px;"
)
),
status = "primary",
solidHeader = TRUE,
width = 12,
plotOutput("hist_bewaesserung_pro_bezirk", height = "500px")
)
),
fluidRow(
box(
title = tagList(
"Durchschnittliche Bewässerung pro gegossenem Baum",
div(
actionButton("info_btn_hbpb2", label = "", icon = icon("info-circle")),
style = "position: absolute; right: 15px; top: 5px;"
)
),
status = "primary",
solidHeader = TRUE,
width = 12,
plotOutput("hist_bewaesserung_pro_baum", height = "500px")
)
)
)
)
)
)
# Server-Logik
server <- function(input, output, session) {
# ... Code aus der Startseite und Karte
# Hilfsfunktion für Einheiten
convert_units <- function(liters) {
if (liters >= 1e6) {
return(list(value = round(liters / 1e6, 2), unit = "ML"))
} else if (liters >= 1e3) {
return(list(value = round(liters / 1e3, 2), unit = "m³"))
} else {
return(list(value = round(liters, 2), unit = "L"))
}
}
full_unit <- function(unit) {
switch(unit,
"ML" = "Mega Liter",
"L" = "Liter",
"m³" = "Kubikmeter",
unit)
}
output$hist_bewaesserung_pro_bezirk <- renderPlot({
req(input$sidebarMenu == "analysis")
df_agg <- df_merged %>%
filter(!is.na(bezirk)) %>%
group_by(bezirk) %>%
summarise(total_water = sum(bewaesserungsmenge_in_liter, na.rm = TRUE)) %>%
ungroup() %>%
arrange(desc(total_water))
df_agg <- df_agg %>%
mutate(
converted = purrr::map(total_water, convert_units),
value = sapply(converted, `[[`, "value"),
unit = sapply(converted, `[[`, "unit")
)
ggplot(df_agg, aes(x = reorder(bezirk, -value), y = value, fill = bezirk)) +
geom_bar(stat = "identity", color = "white", alpha = 0.7, width = 0.8) +
labs(
title = NULL,
x = "Bezirke in Berlin",
y = paste0("Gesamte Bewässerungsmenge (", unique(df_agg$unit), ")")
) +
theme_light() +
theme(
legend.position = "none",
axis.text.x = element_text(angle = 55, hjust = 1, size = 10),
panel.grid.major.x = element_blank(),
plot.margin = margin(10, 10, 10, 10)
) +
scale_fill_discrete(name = "Bezirk")
})
observeEvent(input$info_btn_hbpb, {
showModal(modalDialog(
title = "Information: Bewässerung pro Bezirk",
HTML("
<p>Diese Grafik zeigt die <strong>gesamte Bewässerungsmenge</strong> für jeden Berliner Bezirk.</p>
<ul>
<li>Die Daten werden automatisch in die passende Einheit (Liter, m³ oder Megaliter) umgerechnet</li>
<li>Die Bezirke werden entlang der x-Achse dargestellt</li>
<li>Die Höhe der Balken entspricht der gesamten Bewässerungsmenge</li>
</ul>
"),
easyClose = TRUE,
footer = modalButton("Schließen")
))
})
# Plot: Durchschnittliche Bewässerung pro gegossenem Baum
output$hist_bewaesserung_pro_baum <- renderPlot({
req(input$sidebarMenu == "analysis")
df_agg <- df_merged %>%
filter(!is.na(bezirk)) %>%
group_by(bezirk) %>%
summarise(
total_water = sum(bewaesserungsmenge_in_liter, na.rm = TRUE),
trees_watered = n_distinct(gml_id)
) %>%
ungroup() %>%
mutate(water_per_tree = total_water / trees_watered) %>%
arrange(desc(water_per_tree))
df_agg <- df_agg %>%
mutate(
converted = purrr::map(water_per_tree, convert_units),
value = sapply(converted, `[[`, "value"),
unit = sapply(converted, `[[`, "unit")
)
ggplot(df_agg, aes(x = reorder(bezirk, -value), y = value, fill = bezirk)) +
geom_bar(stat = "identity", color = "white", alpha = 0.7, width = 0.8) +
labs(
title = NULL,
x = "Bezirke in Berlin",
y = paste0("Durchschnittliche Bewässerung pro Baum (", unique(df_agg$unit), ")")
) +
theme_light() +
theme(
legend.position = "none",
axis.text.x = element_text(angle = 55, hjust = 1, size = 10),
panel.grid.major.x = element_blank(),
plot.margin = margin(10, 10, 10, 10)
) +
scale_fill_discrete()
})
observeEvent(input$info_btn_hbpb2, {
showModal(modalDialog(
title = "Information: Bewässerung pro gegossenem Baum",
HTML("
<p>Diese Grafik zeigt die <strong>durchschnittliche Bewässerungsmenge pro gegossenem Baum</strong> in jedem Bezirk.</p>
<ul>
<li>Berechnung: Gesamtwasser geteilt durch Anzahl der tatsächlich gegossenen Bäume</li>
<li>Zeigt die Intensität der Bewässerung und das Engagement der Bürger</li>
<li>Höhere Werte bedeuten mehr Wasser pro Baum, der Pflege erhielt</li>
</ul>
<p><strong>Wichtige Hinweise:</strong></p>
<ul>
<li>Vergleiche zwischen Bezirken müssen mit Vorsicht interpretiert werden</li>
<li>Baumalter, Arten und lokale Bedingungen variieren stark</li>
<li>Zeigt nicht Bäume, die Wasser brauchten aber keins erhielten</li>
</ul>
"),
easyClose = TRUE,
footer = modalButton("Schließen")
))
})
}
# 5. Zusammenführung: Startet die Shiny-Anwendung
shinyApp(ui = ui, server = server)