
5.2. Eine Startseite gestalten#
Story
Nachdem Amir Weber sich die notwedigen Grundkenntnisse angeeignet hat, geht er zur Implementierung des Dashboards über.
Zweck dieser Übung
Der Aufbau eines Dashboards als Form der Visualisierung in der Verwaltungswissenschaft umfasst die Gestaltung einer übersichtlichen Startseite für ein R-Shiny-Dashboard. Diese soll zentrale Informationen klar und strukturiert darstellen, den Nutzer:innen einen schnellen Überblick verschaffen und gleichzeitig als intuitiver Einstiegspunkt in die Anwendung dienen. Hier wird präsentiert, wie man eine solche Startseite erstellen kann.
Die Startseite von Amirs Dashboard soll als zentrale Übersicht und Einstiegspunkt dienen. Hier werden die wichtigsten Kennzahlen für das Bundesland Berlin sofort sichtbar:
Anzahl der erfassten Bäume
Anzahl bewässerter Bäume
Damit liefert die Startseite einen kompakten, aber aussagekräftigen Überblick über das Engagement der Bürger:innen. Sie beantwortet bereits auf den ersten Blick zentrale Fragen der Analyse:
1. Wie groß ist der Bestand an erfassten Bäumen?
2. Wie viele davon wurden aktiv bewässert?
So ist die Startseite nicht nur auf den ersten Blick intuitiv und verständlich, sondern auch funktional der ideale Ausgangspunkt für die weitere Erkundung der Daten.
Für den Einstieg arbeiten Sie mit dem Datensatz „Gieß den Kiez – Bewässerungsdaten“ von GovData. Dieser Datensatz bietet detaillierte Informationen darüber, wann, wo und wieviel in Berlin gegossen wurde. Er eignet sich ideal, um erste Analysen zum Gießverhalten zu erstellen, da er sowohl zeitliche als auch räumliche Bezüge enthält und öffentlich zugänglich ist.
Abb. 5.3 Startseite des Dashboards: Auf der Startseite können ein oder mehrere Bezirke über eine Filterfunktion ausgewählt werden. Die beiden Kacheln zeigen jeweils die Anzahl der erfassten Bäume sowie die Anzahl der bereits bewässerten Bäume für die jeweilige Bezirksauswahl. Zusätzlich wird der Berliner Gesamtbestand an Bäumen als Referenz angegeben. (Quelle: eigene Ausarbeitung)#
Für die Startseite plant Amir eine Kennzahlenübersicht zur schnellen Nutzer*innenorientierung. Für Nutzende soll direkt ablesbar sein:
a) die Größenordnung des Gießverhaltens einzuschätzen (z. B. wie viele Bäume insgesamt erfasst sind, wie viele davon gegossen wurden) b) Stand der Gießaktivitäten Von dort aus können sie anschließend weiter navigieren.
Zusätzlich plant er Filtermöglichkeiten nach Bezirken, um Kennzahlen einzugrenzen und regionale Unterschiede sichtbar zu machen. Die auf der Startseite dargestellten Kennzahlen werden dabei ausschließlich als absolute Werte angezeigt und nicht ins Verhältnis zueinander gesetzt.
Als Nächstes bauen Sie die Startseite des Dashboards mit R. Nach jedem Codeabschnitt werden die verwendeten Techniken und Befehle erklärt. Dabei widmen Sie sich sowohl der Benutzeroberfläche (UI), als auch der Serverseite des R-Shiny-Dashboards.
5.2.1. Benutzeroberfläche (UI)#
Platzierung des UI Codes
Alle in diesem Abschnitt folgenden Code-Bausteine für die Benutzeroberfläche gehören in die ui-Struktur, die Sie in den Vorbereitungen definiert haben:
ui <- dashboardPage(
dashboardHeader(...),
dashboardSidebar(
# ... Hier kommt der Code für die Seitenleiste hin ...
),
dashboardBody(
# ... Hier kommt der Code für den Inhaltsbereich hin ...
)
)
Das System Ihrer Benutzeroberfläche wird aus zwei Teilen bestehen:
einer Seitenleiste (
sidebarMenu) mit der Navigationeinem Inhaltsbereich (
tabItem) mit:sog. ValueBoxen für wichtige Kennzahlen
Dropdowns zur Auswahl des Zeitraums und des Bezirks
Somit können Sie eine übersichtliche Navigationsstruktur etablieren.
Inhaltsbereich#
Auf der Startseite des Dashboards visualisieren Sie die beiden zentralen Kennzahlen: die Gesamtzahl der Bäume sowie die Anzahl der bewässerten Bäume. Über einen integrierten Filter kann die Anzeige zudem auf spezifische Bezirke eingegrenzt werden.
Code
tabItems(
tabItem(
tabName = "start",
fluidRow(
box(width = 12,
# Label: Einfacher Text, Zahl hervorgehoben
div(style = "padding: 10px 15px 0 15px;",
p(style = "font-size: 15px; margin-bottom: 2px;",
"Gesamter Baumbestand in Berlin:"),
span(style = "font-size: 28px; font-weight: bold; color: #3C6E97; margin-top: 0;",
textOutput("total_trees_label"))
),
# Dropdown-Filter in voller Breite darüber
fluidRow(
column(width = 12,
div(style = "padding: 10px 15px;",
selectInput("bezirk", "Bezirk auswählen (Mehrfachauswahl möglich):",
choices = c("Alle Bezirke", sort(na.omit(unique(df_merged$bezirk)))),
selected = "Alle Bezirke", multiple = TRUE)
)
)
),
# Zwei dynamische Kacheln nebeneinander
fluidRow(
valueBoxOutput("total_trees_filtered", width = 6),
valueBoxOutput("total_tree_watered", width = 6)
)
)
)
)
)
Erklärung des Codes
box(...) gruppiert alle Elemente visuell mit:
width = 12(volle Breite – 12 ist die maximale Spaltenanzahl im Raster)
Der Layout-Aufbau (vertikal strukturiert):
Das Text-Label (
textOutput("total_trees_label")): Mithilfe vonspan(...)undp(...)wird die stadtweite Kennzahl als Text ergänzt durch eine formatierte Zahl hervorgehoben.Der Filterbereich (
fluidRow&selectInput): Das Dropdown-Menü nimmt die volle Breite ein (column(width = 12)) und steht direkt über den Kacheln.Die Kacheln (
fluidRow&valueBoxOutput): Die verbleibenden beiden Kacheln teilen sich nun horizontal den Platz. Durchwidth = 6passen genau zwei Stück nebeneinander.
selectInput(...) erstellt das Dropdown-Menü (Auswahlliste) mit:
"bezirk"ist die eindeutige ID des Dropdown-Filters. Überinput$bezirkkann der Server später auf die ausgewählten Bezirke zugreifen."Bezirk auswählen ..."ist die Beschriftung (Label) des Dropdown-Filters. Dieser Text wird in der Benutzeroberfläche oberhalb des Auswahlfeldes angezeigt.choices = c("Alle Bezirke", sort(na.omit(unique(df_merged$bezirk))))definiert die Auswahlmöglichkeiten:unique(df_merged$bezirk)bedeutet: Jeden Bezirk nur einmal anzeigen.na.omit(...)entfernt leere oder fehlerhafte Felder (NAs).sort(...)sortiert die Bezirke alphabetisch (A-Z).c(...)macht daraus eine Liste und setzt den Eintrag “Alle Bezirke” ganz nach oben.
selected = "Alle Bezirke"legt fest, dass beim Start alle Bezirke angezeigt werden.multiple = TRUEheißt: Man darf mehrere Bezirke gleichzeitig auswählen.
Diese Filterauswahl wird im Server verarbeitet und bestimmt, welche Daten für die dynamischen Kacheln berechnet werden.
Mit diesem Aufbau haben Sie die Struktur seiner Startseite definiert:
Eine klare Navigation über die Seitenleiste
Zwei zentrale Kennzahlen in prominenter Position
Ein Filter zur Eingrenzung nach Bezirken
Was noch fehlt, ist die Intelligenz: Die tatsächliche Berechnung der Kennzahlen und die Reaktion auf Nutzer:inneneingaben. Dafür ist der Server zuständig.
5.2.2. Server – Die Logik hinter dem Dashboard#
Platzierung des Server Codes
Alle in diesem Abschnitt folgenden Code-Bausteine für den Server gehören in die server-Funktion, die Sie in den Vorbereitungen definiert haben:
server <- function(input, output) {
# Hier folgt der R-Code zur Datenverarbeitung...
}
In Shiny beobachtet der Server kontinuierlich die Eingabefelder (input$...) und aktualisiert automatisch alle Ausgaben (output$...), die von diesen Eingaben abhängen.
Für Ihr Dashboard bedeutet das konkret:
Sobald Nutzer:innen einen anderen Bezirk auswählen, wird der Datensatz im Hintergrund neu gefiltert
Die Kennzahlen werden neu berechnet und sofort in den ValueBoxen angezeigt
Alles geschieht ohne Verzögerung, ohne manuelles Nachladen
Daten filtern mit reaktiven Funktionen#
Amir beginnt mit der zentralen Aufgabe: Die Daten müssen je nach Auswahl der Nutzer:innen gefiltert werden. Dafür erstellt er eine reaktive Funktion, die immer dann neu ausgeführt wird, wenn sich die Eingaben ändern.
Code
filteredData <- reactive({
req(input$bezirk)
df <- df_merged
df_filtered <- df
# Filter nach Bezirk
if (!("Alle Bezirke" %in% input$bezirk)) {
df_filtered <- df_filtered %>% filter(bezirk %in% input$bezirk)
}
df_filtered
})
Erläuterung des Codes
reactive({...})
erzeugt eine reaktive Funktion, die automatisch neu berechnet wird, wenn sich Eingaben ändern.
ist wie ein intelligenter Beobachter: Sobald sich
input$bezirkändert, wird filteredData() neu berechnet.
req(input$bezirk)
sorgt dafür, dass die Funktion nur ausgeführt wird, wenn bestimmte Eingaben vorhanden sind.
Dynamische Anzeige
Damit das Dashboard Entscheidungen treffen kann (z. B. beim Filtern oder Anpassen von Ansichten), nutzt es if-Anweisungen und Operatoren:
if (Bedingung) {
# wird ausgeführt, wenn die Bedingung wahr ist
} else {
# wird ausgeführt, wenn die Bedingung falsch ist
}
Die Filterlogik
if (!("Alle Bezirke" %in% input$bezirk)) {
df_filtered <- df_filtered %>% filter(bezirk %in% input$bezirk)
}
Diese Bedingung implementiert die eigentliche Filterung:
Falls „Alle Bezirke“ in der Auswahl enthalten ist → keine Einschränkung, alle Daten bleiben erhalten
Falls nur bestimmte Bezirke ausgewählt wurden → behalte nur die Zeilen, deren
bezirkin der Auswahl (input$bezirk) vorkommt
Warum ist diese Struktur wichtig?
Sie müssen den Filtercode nur einmal schreiben. Alle Visualisierungen und Kennzahlen, die filteredData() verwenden, greifen automatisch auf die aktuell gefilterte Version der Daten zu. Das vermeidet Redundanz und macht den Code wartbar.
Praktisches Beispiel für das Dashboard#
Code
output$dynamic_tree_box <- renderUI({
if ("Baumbestand Stand 2025" %in% input$start_year) {
valueBoxOutput("total_trees")
} else {
valueBoxOutput("total_tree_watered")
}
})
Erklärung des Codes
renderUI(...): erzeugt dynamische Elemente und erlaubt es, UI-Elemente zur Laufzeit zu verändern – je nach Nutzereingabe.Abhängig von der Auswahl (
input$start_year) wird eine andere Kennzahl angezeigt.
Beispiel:
Wird nur „2020–2024“ ausgewählt, zeigt dynamic_tree_box nur gegossene Bäume an.
ValueBoxes: Kennzahlen anzeigen#
Nun können Sie die Kennzahlen mit Inhalten füllen. In der UI wurden diese bereits als Label textOutput("total_trees_label") und zwei Kacheln valueBoxOutput("total_trees_filtered") und valueBoxOutput("total_tree_watered") angelegt. Nun definieren Sie, was darin erscheinen soll.
Alle Bäume
output$total_trees_label <- renderText({
formatC(n_distinct(df_merged$gisid), format = "d", big.mark = ".")
})
output$total_trees_filtered <- renderValueBox({
valueBox(
formatC(n_distinct(filteredData()$gisid), format = "d", big.mark = "."),
"erfasste Bäume (Bezirksauswahl)",
icon = icon("tree"),
color = "olive"
)
})
Erklärung des Codes
output$total_trees_labelist das, was an das simple UI-ElementtextOutput("total_trees_label")gesendet wird.renderText({...})berechnet reinen Text, anstelle einer visuell aufwändigen Kachel.n_distinct(...): zählt eindeutige Bäume (verhindert doppelte Zählungen).formatC(...)formatiert die Nummer ansprechend mit Tausendertrennzeichen.
Gegossene Bäume
output$total_tree_watered <- renderValueBox({
valueBox(
formatC(n_distinct(filteredData()$gisid[!is.na(filteredData()$timestamp)]),
format = "d", big.mark = "."),
"bewässerte Bäume (Bezirksauswahl)",
icon = icon("tint"),
color = "blue"
)
})
Erklärung des Codes
Hier gibt es einen entscheidenden Unterschied zum Text-Label oben:
Statt
df_mergedverwenden Sie nunfilteredData()– die reaktive Datenquelle, die sich blitzschnell je nach gewählten Bezirken ändert.!is.na(filteredData()$timestamp)filtert zusätzlich: Es werden nur jene Bäume der Auswahl gezählt, die mindestens einmal gegossen wurden (erkennbar an einem gültigen Zeitstempel).icon("tint")(ein Tropfen-Symbol) undcolor = "blue"heben die Wasserthematik visuell hervor.
Warum diese bewusste Unterscheidung?
Das Text-Label ist eine konstante Referenzgröße – es zeigt immer die Zahl von ganz Berlin.
Die Kacheln darunter sind agil und reagieren auf die Auswahl im Drop-Down-Menü.
Durch diese bewusste Trennung ermöglichen Sie den Nutzer:innen, das Engagement in einzelnen Bezirken mit der Gesamtsituation zu vergleichen.
Automatisches Abwählen von Bezirken
prev_bezirk <- reactiveVal("Alle Bezirke")
observeEvent(input$bezirk, {
if (is.null(input$bezirk)) {
updateSelectInput(session, "bezirk", selected = "Alle Bezirke")
prev_bezirk("Alle Bezirke")
return()
}
curr_bezirk <- input$bezirk
prev <- prev_bezirk()
if ("Alle Bezirke" %in% curr_bezirk && !("Alle Bezirke" %in% prev)) {
updateSelectInput(session, "bezirk", selected = "Alle Bezirke")
prev_bezirk("Alle Bezirke")
} else if ("Alle Bezirke" %in% curr_bezirk && length(curr_bezirk) > 1) {
new_selection <- curr_bezirk[curr_bezirk != "Alle Bezirke"]
updateSelectInput(session, "bezirk", selected = new_selection)
prev_bezirk(new_selection)
} else {
prev_bezirk(curr_bezirk)
}
}, ignoreNULL = FALSE, ignoreInit = TRUE)
Erklärung des Codes
Dieser Code-Block löst ein logisches Problem: Aktuell ist es möglich die Option „Alle Bezirke“ gleichzeitig mit spezifischen Bezirken (z.B. „Treptow-Köpenick“) auswählen. Der Code macht das Dropdown-Menü „intelligent“ und schließt diese Optionen gegenseitig aus.
prev_bezirk <- reactiveVal("Alle Bezirke")
Dies ist eine Art Kurzzeitgedächtnis (reactiveVal). Die App merkt sich hier, was der Nutzer vor dem letzten Klick ausgewählt hatte. Der Startwert ist „Alle Bezirke“.
observeEvent(input$bezirk, { ... })
Dies ist ein Beobachter. Er wartet im Hintergrund und führt den Code in den geschweiften Klammern {} jedes Mal aus, sobald der Nutzer im Dropdown-Menü (input$bezirk) etwas anklickt oder ändert.
if (is.null(input$bezirk)) { ... return() }
Ein Sicherheitscheck. Falls die Auswahl komplett leer ist (z. B. wenn Nutzer:innen alles herausgelöscht haben), zwingt der Code das Dropdown-Menü dazu, wieder „Alle Bezirke“ auszuwählen, und bricht dann ab (return()).
Die if-else-Bedingung:
Zuerst werden der aktuelle Zustand (curr_bezirk) und der vorherige Zustand (prev) in Variablen gespeichert. Dann prüft die App drei Fälle:
Fall 1 (
if):("Alle Bezirke" %in% curr_bezirk && !("Alle Bezirke" %in% prev))Wurde „Alle Bezirke“ gerade frisch angeklickt? (Es ist in der aktuellen Auswahl, war aber vorher nicht da). Reaktion:updateSelectInputzwingt das Dropdown-Menü dazu, nur noch „Alle Bezirke“ anzuzeigen. Alle vorher ausgewählten Einzelbezirke werden gelöscht.Fall 2 (
else if):("Alle Bezirke" %in% curr_bezirk && length(curr_bezirk) > 1)Wurde ein neuer Bezirk angeklickt, während „Alle Bezirke“ noch aktiv war? („Alle Bezirke“ ist in der Auswahl, aber die Liste ist jetzt länger als 1). Reaktion: „Alle Bezirke“ wird aus der aktuellen Auswahl herausgefiltert (curr_bezirk != "Alle Bezirke") und das Dropdown-Menü wird auf diese neue, um „Alle Bezirke“ bereinigte Auswahl aktualisiert.Fall 3 (
else): Wenn weder Fall 1 noch Fall 2 zutreffen, speichert die App einfach die aktuelle Auswahl im Kurzzeitgedächtnis (prev_bezirk), um für den nächsten Klick bereit zu sein.
ignoreInit = TRUE
Dies steht ganz am Ende und sagt der App: „Führe diese Überprüfung nicht sofort beim Start der App aus, sondern erst, wenn der Nutzer wirklich das erste Mal selbst klickt.“
Das Dashboard ist nun funktionsfähig: Nutzer:innen können Bezirke auswählen und sehen sofort, wie viele Bäume in diesen Bezirken, im Verhältnis zum Gesamtbestand, gegossen wurden. Die Trennung von UI und Server ermöglicht es Amir, später weitere Analysen hinzuzufügen, ohne die bestehende Struktur grundlegend ändern zu müssen.
Überblick der Funktionen/Operatoren
Funktion/Operator |
Bedeutung |
|---|---|
|
weist einer Variable einen Wert zu |
|
Bedingte Ausführung |
|
prüft, ob ein Wert in einer Liste ist |
|
filtert Zeilen in einem Datensatz |
|
prüft auf fehlende Werte |
|
Pipe-Operator: leitet Ergebnis einer Funktion weiter |
|
erstellt einen reaktiven Ausdruck im Server |
|
stellt sicher, dass ein Eingabewert vorhanden ist |
|
rendert eine |
|
erstellt eine farbige Kennzahlen-Box in der UI |
|
Platzhalter in der UI für eine reaktive |
|
bindet ein Font-Awesome-Icon ein |
|
erstellt ein Dropdown-Auswahlmenü |
|
erstellt eine responsive Zeile im Grid-Layout |
|
definiert eine Spaltenbreite innerhalb einer |
|
erstellt eine umrahmende Inhaltsbox in der UI |
|
strukturiert Inhalte in Tab-Bereiche |
|
definiert den Hauptinhaltsbereich des Dashboards |
|
definiert die Seitenleiste |
|
erstellt ein Navigationsmenü in der Seitenleiste |
|
definiert den Kopfbereich mit Titel |
|
erstellt das Grundlayout der Shiny-Dashboard-Seite |
|
startet die Shiny-Anwendung mit UI und Server |
Gesamter Code
# UI-Definition
ui <- dashboardPage(
# 1. HEADER: Titelbereich des Dashboards
dashboardHeader(title = "Gieß den Kiez Dashboard"),
# 2. SIDEBAR: Seitliche Navigationsleiste mit Menüeinträgen
dashboardSidebar(
sidebarMenu( id = "sidebarMenu",
menuItem("Startseite", tabName = "start", icon = icon("home"))
)
),
# 3. BODY: Inhaltsbereich
dashboardBody(
tabItems(
tabItem(
tabName = "start",
fluidRow(
box(width = 12,
# Label: Einfacher Text, Zahl hervorgehoben
div(style = "padding: 10px 15px 0 15px;",
p(style = "font-size: 15px; margin-bottom: 2px;",
"Gesamter Baumbestand in Berlin:"),
span(style = "font-size: 28px; font-weight: bold; color: #3C6E97; margin-top: 0;",
textOutput("total_trees_label"))
),
# Dropdown-Filter in voller Breite darüber
fluidRow(
column(width = 12,
div(style = "padding: 10px 15px;",
selectInput("bezirk", "Bezirk auswählen (Mehrfachauswahl möglich):",
choices = c("Alle Bezirke", sort(na.omit(unique(df_merged$bezirk)))),
selected = "Alle Bezirke", multiple = TRUE)
)
)
),
# Zwei dynamische Kacheln nebeneinander
fluidRow(
valueBoxOutput("total_trees_filtered", width = 6),
valueBoxOutput("total_tree_watered", width = 6)
)
)
)
)
)
)
)
# Server-Logik
server <- function(input, output, session) {
# --- Reaktive Bezirksauswahl ---
prev_bezirk <- reactiveVal("Alle Bezirke")
observeEvent(input$bezirk, {
if (is.null(input$bezirk)) {
updateSelectInput(session, "bezirk", selected = "Alle Bezirke")
prev_bezirk("Alle Bezirke")
return()
}
curr_bezirk <- input$bezirk
prev <- prev_bezirk()
if ("Alle Bezirke" %in% curr_bezirk && !("Alle Bezirke" %in% prev)) {
updateSelectInput(session, "bezirk", selected = "Alle Bezirke")
prev_bezirk("Alle Bezirke")
} else if ("Alle Bezirke" %in% curr_bezirk && length(curr_bezirk) > 1) {
new_selection <- curr_bezirk[curr_bezirk != "Alle Bezirke"]
updateSelectInput(session, "bezirk", selected = new_selection)
prev_bezirk(new_selection)
} else {
prev_bezirk(curr_bezirk)
}
}, ignoreNULL = FALSE, ignoreInit = TRUE)
# ---- Gefilterte Daten ----
filteredData <- reactive({
req(input$bezirk)
df <- df_merged
df_filtered <- df
if (!("Alle Bezirke" %in% input$bezirk)) {
df_filtered <- df_filtered %>% filter(bezirk %in% input$bezirk)
}
df_filtered
})
# ---- ValueBoxes ----
# Label 1: Gesamtzahl (Immer ganz Berlin)
output$total_trees_label <- renderText({
formatC(n_distinct(df_merged$gisid), format = "d", big.mark = ".")
})
# Box 2: Gefilterte Zahl (Reagiert auf den Filter)
output$total_trees_filtered <- renderValueBox({
valueBox(
formatC(n_distinct(filteredData()$gisid), format = "d", big.mark = "."),
"erfasste Bäume (Bezirksauswahl)",
icon = icon("tree"),
color = "olive"
)
})
# Box 3: Gegossene Bäume (Reagiert auf den Filter)
output$total_tree_watered <- renderValueBox({
valueBox(
formatC(n_distinct(filteredData()$gisid[!is.na(filteredData()$timestamp)]),
format = "d", big.mark = "."),
"bewässerte Bäume (Bezirksauswahl)",
icon = icon("tint"),
color = "blue"
)
})
}
shinyApp(ui = ui, server = server)
5.2.3. Was muss Amir beim Bau eines Dashboards beachten?#
Bei der Gestaltung der Startseite sollten Sie darauf achten, dass die wichtigsten Informationen klar, gut lesbar und ohne unnötige Ablenkungen präsentiert werden. Besonders für einen ersten Überblick gilt: Weniger ist oft mehr.
Für die Startseite heißt das vor allem:
Klarheit: Keine überladene Darstellung, eindeutige Beschriftungen, selbsterklärende Kennzahlen.
Lesbarkeit: Vermeidung von 3D-Elementen oder komplexen Grafiken, wenn ein einfacher Indikator genügt.
Fokus: Nur die wirklich zentralen Kennzahlen aufnehmen, um den Blick nicht zu zerstreuen.
Konsistenz: Einheitliche Farb- und Formatwahl, damit Nutzer:innen sich sofort orientieren können.
Kontext: Kurze Hinweise oder Legenden, damit die Zahlen richtig interpretiert werden können.
5.2.4. Reflexion#
Die zentrale Leitfrage der Fallstudie lautet: Wo lassen sich die höchsten Ausprägungen des Engagements von Bürger:innen bei der Bewässerung städtischer Bäume in Berlin feststellen?
Die Startseite des Dashboards ermöglicht einen ersten Überblick darüber, in welchen Bezirken es wieviele Bäume gibt und wieviele davon gegossen wurden. In absoluten Zahlen zeigt sich dabei das höchste Engagement bei den Bürger:innen in Mitte, gefolgt von Tempelhof-Schöneberg und Friedrichshain-Kreuzberg.
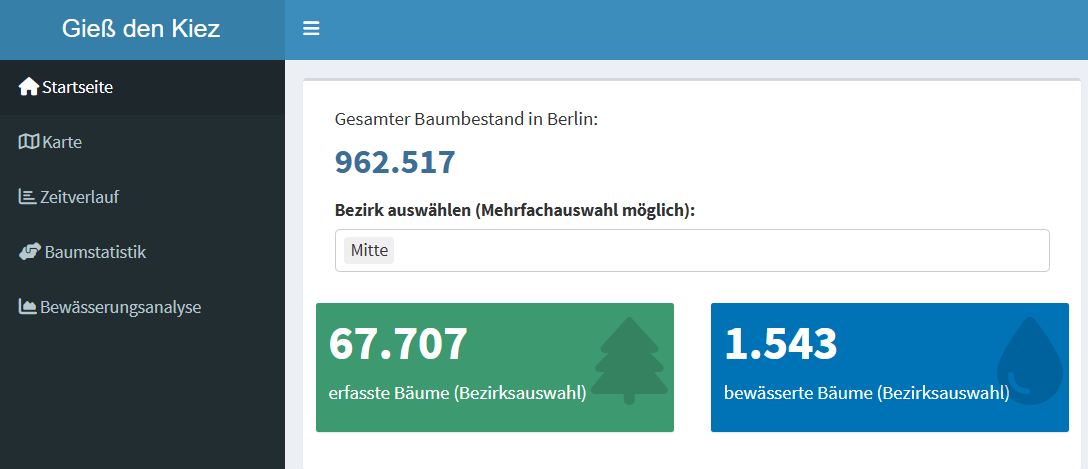
Abb. 5.4 Startseite, jedoch ist nur der Bezirk Mitte ausgewählt (dort wurde in absoluten Zahlen die meisten Bäume gegossen) (Quelle: eigene Ausarbeitung)#
Für eine abschließende Beantwortung der Leitfrage reicht diese Betrachtung jedoch nicht aus, da ohne Normalisierung – etwa durch das Verhältnis gegossener Bäume zur Gesamtbaumzahl je Bezirk – keine validen Vergleiche zwischen den Bezirken gezogen werden können. Fahren Sie daher mit der folgenden Übung fort.
Übung#
Berechnen Sie nun für jeden Berliner Bezirk das relative Bürger:innenengagement, indem Sie die Anzahl der gegossenen Bäume zur Gesamtbaumzahl des jeweiligen Bezirks ins Verhältnis setzen.
An dieser Stelle können Sie Ihre bisher erlernten R-Fähigkeiten anwenden. Anstatt sich die Kennzahlen aus dem Dashboard rauszuschreiben und die Berechnungen mit einem Taschenrechner oder Excel durchzuführen, schreiben Sie doch ein kleines R-Script, welches diese Aufgabe erledigt. Sobald Sie das richtige Ergebnis berechnet haben, können Sie es unten im Quiz auswählen. Vergessen Sie hierbei nicht, wie bereits in vorherigen Kapiteln gezeigt, das Arbeitsverzeichnis korrekt zu setzen und die bereinigten Daten aus dem Datenverzeichnis auszulesen.
Lösungsvorschlag
library(dplyr)
# 1. Lade die Daten
df_merged <- read.csv2("data/df_merged_final.csv", fileEncoding = "UTF-8")
# 2. Berechne den Bezirk mit der höchsten Gieß-Quote
top_bezirk <- df_merged %>%
group_by(bezirk) %>%
summarise(ratio = n_distinct(gisid[!is.na(timestamp)]) / n_distinct(gisid)) %>%
slice_max(ratio, n = 1)
# 3. Ergebnis anzeigen
print(top_bezirk)
Durch die Berechnung der relativen Zahlen konnte die zentrale Leitfrage dieser Fallstudie nun sinnvoll beantwortet werden, wo sich die höchsten Ausprägungen des Engagements von Bürger:innen in Berlin feststellen lässt.
Im nächsten Abschnitt werden Sie aufbauend auf diesen Ergebnissen eine weitere Visualisierung in Form einer Karte erstellen, die nochmal räumlich abbildet, in welchem Berliner Bezirk wieviel gegossen wurde.