2.3. Datenbasis#
Story
Amir Weber macht sich Gedanken, welche Daten er braucht und woher er sie beziehen kann… Dabei fällt ihm das Berliner Projekt Gieß den Kiez ein, dass diese Daten bereits erhebt und zur Verfügung stellt. Er prüft zudem, welche Daten noch von Interesse sind und woher er sie beziehen kann.
In diesem Kapitel stellen wir Ihnen die Daten vor, die wir zur Beantwortung unserer Forschungsfrage benötigen und warum sie von Interesse sind.
Die Daten werden für die Datenvisualisierung in RShiny benötigt. Dazu brauchen wir zwei zentrale Datensätze:
Daten über den Berliner Baumbestand
Bewässerungsdaten des Projekts Gieß den Kiez
Diese Datengrundlage ermöglicht eine fundierte Analyse der urbanen Bewässerungsinfrastruktur in Berlin.
2.3.1. Gieß den Kiez – Bewässerungsdaten (Govdata)#
Die Datenplattform “Gieß den Kiez” dokumentiert die freiwillige Bewässerung städtischer Bäume durch Bürger:innen. Wir beziehen die Bewässerungsdaten über das Portal GovData. Der Datensatz enthält Informationen über einzelne Bewässerungsvorgänge. Jeder Eintrag ist einem bestimmten Baum zugeordnet (zu erkennen an der ID) und umfasst unter anderem:
Geokoordinaten (Längengrad:
lng, Breitengrad:lat)Baumart:
art_dtschund Gattung:gattung_deutschPflanzjahr:
pflanzjahr, Straßenname:strnameund Bezirk:bezirkZeitpunkt der letzten Bewässerung:
timestampMenge der Bewässerung in Litern:
bewaesserungsmenge_in_liter
Diese Daten ermöglichen Rückschlüsse auf Muster im Gießverhalten der Bevölkerung in dem Zeitraum 2020-2024 und versorgen die Visualisierung mit räumlich und zeitlich differenzierten Informationen zur städtischen Baumbewässerung.

Fig. 2.1 Karte mit Personen darauf. (KI generiert)#
2.3.2. Baumbestandsdaten (Berlin Open Data)#
Die Baumbestandsdaten stammen aus dem Berliner Open-Data-Portal und umfassen sowohl Straßenbäume als auch Anlagebäume. Die Daten liegen im WFS-Format vor.
Die Datensätze enthalten u.a. Informationen zu:
Identifikatoren wie
gml_id(ermöglicht Unterscheidung zwischen Anlagen- und Straßenbäumen),gisidundpitidBotanische Klassifikation, z. B. Baumart:
art_dtsch,art_bot, Gattung:gattung_deutsch,gattungund Gruppe:art_gruppe)Standortmerkmale wie Straße:
strname, Hausnummer:hausnr, Zusatz:zusatz, Bezirk:bezirk, Geometrie:geom(enthält Längen- und Breitengrad in anderem Format) und Standortnummer:standortnrPflanzjahr:
pflanzjahr
Sie dienen dazu, die Struktur des städtischen Baumbestands besser zu verstehen und in Beziehung zu den Gießdaten zu setzen. Das ist besonders wichtig, weil sich über die Identifikatoren die Informationen zu jedem einzelnen Baum sinnvoll zusammenführen lassen.
2.3.3. Bezirksgrenzen (Berlin Open Data)#
Für die geografische Einordnung des Baumbestands wurde zusätzlich der Datensatz zu den Berliner Bezirksgrenzen genutzt. Dieser enthält die polygonalen Abgrenzungen aller Berliner Bezirke im GeoJson-Format und ermöglicht damit eine präzise räumliche Zuordnung von Punktdaten und enthalten pro Bezirk unter anderem folgende Attribute:
Gemeinde_name: Name des Bezirks (z. B. Reinickendorf)Gemeinde_schluessel: Dreistelliger Schlüssel des BezirksLand_nameundLand_schluessel: Verwaltungszuordnung zu BerlinSchluessel_gesamt: Vollständiger Gebietsschlüsselgeometry: Geometrische Beschreibung der Bezirksgrenzen als Multi-Polygon
Ebenso dient die Zuordnung als Grundlage für Visualisierungen und statistische Auswertungen auf Bezirksebene.
2.3.4. Öffentliche Wasserbrunnen (OpenStreetMap via Overpass API) - Kapitel wird noch rausgeschmissen#
Zur Identifikation potenzieller Wasserquellen für die Baumgießung wurden Daten zu öffentlichen Wasserpumpen aus Overpass Turbo extrahiert. Dabei handelt es sich um ein Daten-Filterungs-Werkzeug für OpenStreetMap (OSM). Mithilfe einer Abfrage im OpenStreetMap-Tagging-Schema “man_made”=”water_well”
[out:json][timeout:60];
// Berliner Stadtgrenze (Relation)
{{geocodeArea:Berlin}}->.searchArea;
// Suche nach Wasserpumpen innerhalb Berlins
(
node["man_made"="water_well"](area.searchArea);
way["man_made"="water_well"](area.searchArea);
relation["man_made"="water_well"](area.searchArea);
);
out body;
>;
out skel qt;
wurde eine umfangreiche Sammlung relevanter Pumpenstandorte generiert. Die resultierenden Daten enthalten zahlreiche Attribute, von denen besonders relevant sind:
Geolokation (Punktgeometrie:
geometry)Zugänglichkeit (
access)Pumpentyp und Stil (
pump.status,pump.style, Pumpenbedinung:pump)Identifikator(
id)
2.3.5. Bezirksflächen (Grünflächeninformationssystem (GRIS)) - Kapitel wird noch rausgeschmissen#
Um die Verteilung und Dichte öffentlicher Wasserpumpen innerhalb der Berliner Bezirke besser quantifizieren zu können, wurden ergänzend Flächendaten aus dem Grünflächeninformationssystem (GRIS) des Landes Berlin herangezogen. Die Flächenangaben dienen insbesondere dazu, die Pumpendichte pro Hektar (ha) auf Bezirksebene zu berechnen und damit die infrastrukturelle Versorgung vergleichbar darzustellen.
Die Flächendaten wurden aus einer tabellarischen Quelle des GRIS extrahiert und manuell in ein strukturiertes Dataframe überführt. Dieses enthält pro Bezirk folgende Informationen:
bezirk: Name des Berliner Bezirksflaeche_ha: Bezirksfläche in Hektar
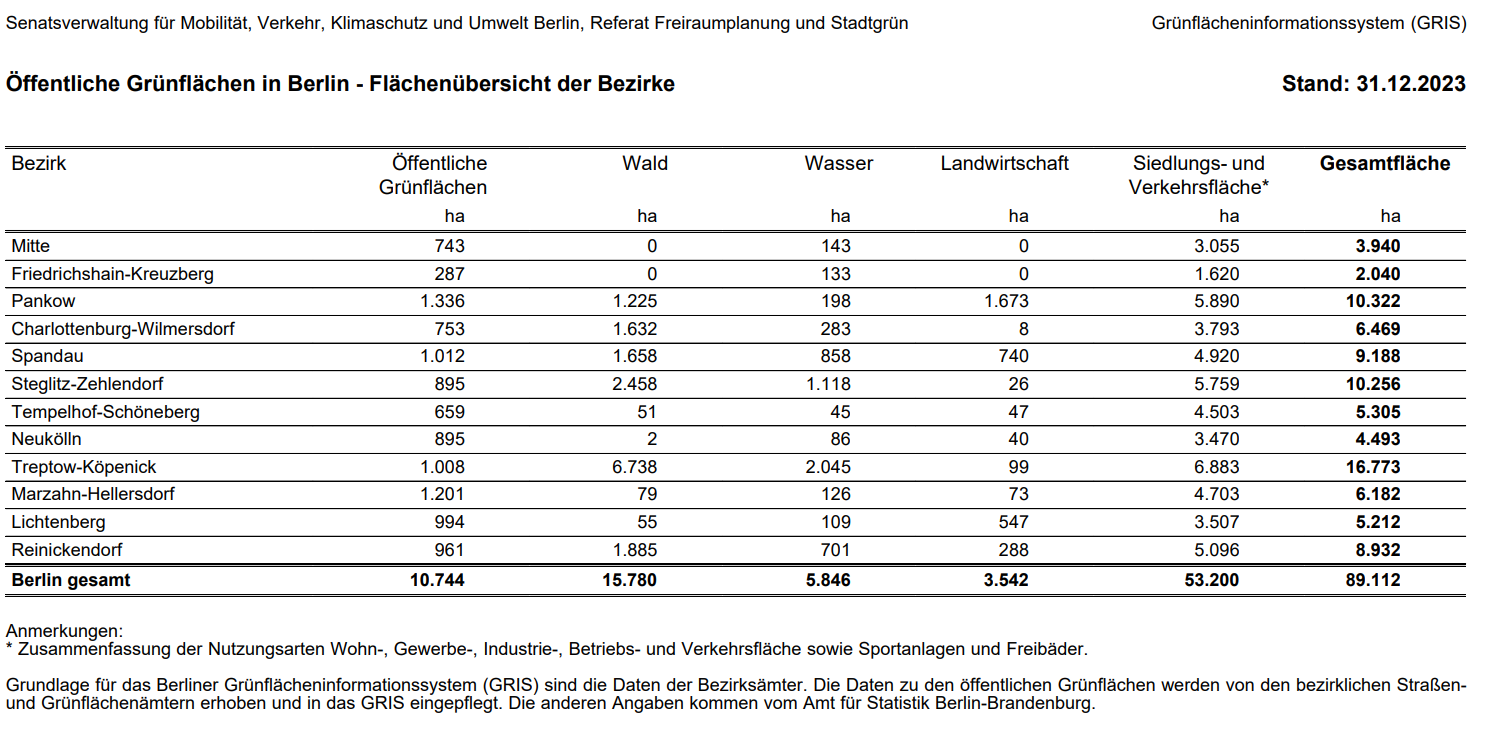
Fig. 2.2 Tabelle mit Angaben zu Bezirksflächen#
bezirksflaechen <- data.frame(
bezirk = c("Mitte", "Friedrichshain-Kreuzberg", "Pankow", "Charlottenburg-Wilmersdorf",
"Spandau", "Steglitz-Zehlendorf", "Tempelhof-Schöneberg", "Neukölln",
"Treptow-Köpenick", "Marzahn-Hellersdorf", "Lichtenberg", "Reinickendorf"),
flaeche_ha = c(3.940, 2.040, 10.322, 6.469, 9.188, 10.256, 5.305, 4.493, 16.773, 6.182, 5.212, 8.932)
)
Diese Daten ermöglichen flächenbezogene Vergleiche der Pumpendichte und bilden eine wichtige Grundlage für die Bewertung der Verteilung öffentlicher Wasserquellen im urbanen Raum.