
3.2. Vorbereitung der Daten: Einlesen und Bereinigung#
Bevor Sie mit dem Bau eines Dashboards mit R Shiny beginnen können, müssen Sie die Daten einholen und bearbeiten. Dazu werden verschiedene Datensätze, nämlich der Berliner Baumkataster sowie manuell dokumentierte Gießdaten, zusammengeführt und so aufbereitet, dass sie für Visualisierungen und eine explorative Analyse verwendet werden können.
Story
Dr. Amir Weber möchte sich zunächst einen schnellen Überblick verschaffen: Wie werden Bäume in Berlin gegossen und wie engagieren sich die Bürger:innen dabei? Bei seiner Recherche nimmt er erneut die Plattform Gieß den Kiez genauer unter die Lupe. Besonders beeindruckt ihn, wie anschaulich die Daten dort visualisiert sind (s. Abb. 5.2 in Kapitel 5.1). Die Mischung aus Angaben zu Bäumen und Gießenden, Karten und Zeitverläufen inspirieren ihn so sehr, dass er sie für seine eigene R-Shiny-Anwendung übernehmen möchte. Dazu benötigt er aber erst einmal Daten, welche dann zwecksgemäß bereinigt werden müssen.
3.2.1. Daten laden, aggregieren und vorbereiten#
Arbeitsverzeichnis setzen
Damit die eingegebenen Kommandos im richtigen Verzeichnis ausgeführt werden, müssen Sie zunächst das Arbeitsverzeichnis korrekt setzen:
Rufen Sie (wenn nicht schon aufgerufen) den Ordner auf, in dem Ihr R-Shiny-Script gespeichert ist.
Unter Session finden Sie den Reiter Set Working Directory.
Klicken Sie auf To Source File Location .
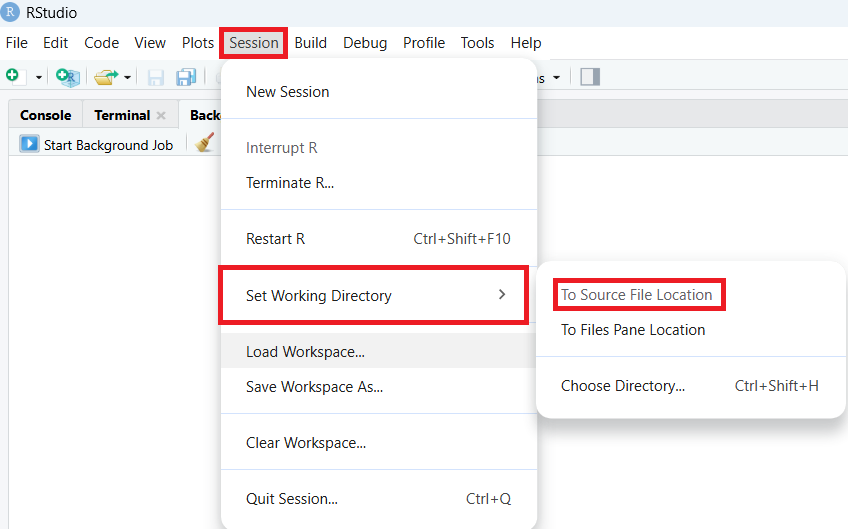
Abb. 3.4 Anleitung zum Setzen des Arbeitsverzeichnisses#
Installieren der Bibliotheken
Bevor Sie die Daten einlesen können, müssen Sie folgende Bibliotheken (und, sofern noch nicht geschehen, davor noch die dazugehörigen Pakete) laden:
# --- PAKETE: ---
install.packages("sf")
install.packages("tidyverse")
# --- BIBLIOTHEKEN: ---
library(sf)
library(dplyr)
library(tidyr)
library(stringr)
Laden der Baumkatasterdaten
Die Berliner Baumdaten beziehen Sie über eine WFS-Schnittstelle (Web Feature Service). Dabei werden sowohl Anlagenbäume als auch Straßenbäume geladen. Dies geschieht mit dem Befehl st_read.
#0 CSV File lokalisieren bzw. laden
local_path <- "Data/giessdenkiez_bewässerungsdaten.csv"
url_path <- "https://raw.githubusercontent.com/technologiestiftung/giessdenkiez-de-opendata/main/daten/giessdenkiez_bew%C3%A4sserungsdaten.csv"
if (file.exists(local_path)) {
csv_data <- local_path
} else {
csv_data <- url_path
}
# 1. Baumbestandsdaten laden
anlagenbaeume <- st_read("WFS:https://gdi.berlin.de/services/wfs/baumbestand", layer = "baumbestand:anlagenbaeume")
strassenbaeume <- st_read("WFS:https://gdi.berlin.de/services/wfs/baumbestand", layer = "baumbestand:strassenbaeume")
Laden und Bereinigung der Gießdaten
Die Gießdaten stammen aus einer CSV-Datei des Projekts „Gieß den Kiez“. Sie lesen diese erst ein und anschließend bereinigen Sie sie, d. h.:
Sie entfernen ungültige oder fehlende Koordinaten (Längen-/Breitengrad).
Sie schließen Datensätze ohne Straßenname oder mit fehlerhaften Gattungsbezeichnungen (z. B. numerische Werte) aus.
# 2. Bewässerungsdaten laden und bereinigen
df_clean <- read.csv(csv_data, sep = ";", stringsAsFactors = FALSE, fileEncoding = "UTF-8") %>%
drop_na(lng, lat, bewaesserungsmenge_in_liter) %>%
filter(strname != "Undefined" & strname != "" & !str_detect(gattung_deutsch, "[0-9]"))
Vereinheitlichung und Zusammenführung der Baumdaten
Sie vereinheitlichen die beiden Baumdatenquellen (gemeinsames Koordinatensystem EPSG:4326) und führen diese zusammen. Danach extrahieren Sie explizit die Koordinaten und entfernen die Geometriedaten, also die technische Standortinformation jedes Baumes in einem speziellen räumlichen Format (z. B. die geom-Spalte mit Einträgen wie c(" 394532.3", "5811461.0")), um die Dateigröße zu reduzieren und die Weiterverarbeitung zu erleichtern.
# 3. Bäume zusammenführen
baumbestand <- bind_rows(anlagenbaeume, strassenbaeume) %>%
st_transform(crs = 4326)
# 4. Geometrie extrahieren
coords <- st_coordinates(baumbestand$geom)
baumbestand$lng <- coords[, "X"]
baumbestand$lat <- coords[, "Y"]
Harmonisierung und Verknüpfung der Daten
Die eindeutige Baumkennung gisid passen Sie so an, dass sie mit der id aus den Gießdaten übereinstimmt (Unterstrich wird zu Doppelpunkt). Dadurch können Sie die beiden Datensätze über einen sogenannten „Left Join“ zusammenführen.
# 5. Geometrie entfernen
baumbestand <- st_drop_geometry(baumbestand)
# 6. gisid anpassen (Unterstrich → Doppelpunkt)
baumbestand$gisid <- str_replace_all(baumbestand$gisid, "_", ":")
# 7. Bäume und Bewässerungsdaten mergen (über gisid = id)
df_merged <- baumbestand %>%
left_join(df_clean %>% select(id, bewaesserungsmenge_in_liter, timestamp),
by = c("gisid" = "id"))
Entfernung von Einträgen mit ungültigen Pflanzjahren
Damit Sie in künftigen Operationen korrekt mit Pflanzjahren arbeiten können, filtern Sie sicherheitshalber alle Einträge mit ungültigem Pflanzjahr heraus. In diesem Fall entscheiden Sie, dass nicht-vierstellige Jahresangaben und Jahresangaben, welche in der Zukunft liegen, herausgefiltert werden sollen. Dafür orientieren Sie sich am Systemjahr auf ihrem Endgerät. Stellen Sie sicher, dass der Kalender Ihres Endgerätes hierfür richtig eingestellt ist.
# 8. Ungültige Pflanzjahre herausfiltern
current_year <- as.integer(format(Sys.Date(), "%Y"))
df_merged <- df_merged %>%
mutate(pflanzjahr = as.numeric(pflanzjahr)) %>%
filter(is.na(pflanzjahr) | (nchar(as.character(as.integer(pflanzjahr))) == 4 & pflanzjahr <= current_year))
Speichern der kombinierten Daten
Die aufbereiteten Daten speichern Sie als CSV-Datei. Eine Ausgabe relevanter Kennzahlen (z. B. Anzahl verknüpfter Bäume) dient der Kontrolle.
# 9. Ergebnis speichern
if (!dir.exists("data")) dir.create("data")
write.csv2(df_merged, "data/df_merged_final.csv", row.names = FALSE, fileEncoding = "UTF-8")
Wenn Sie möchten, schauen Sie sich den gesamten Code als einen Block an, bevor Sie Baumdaten den Berliner Bezirken zuordnen:
Gesamter Code
library(sf)
library(dplyr)
library(tidyr)
library(stringr)
#0 CSV File lokalisieren bzw. laden
local_path <- "Data/giessdenkiez_bewässerungsdaten.csv"
url_path <- "https://raw.githubusercontent.com/technologiestiftung/giessdenkiez-de-opendata/main/daten/giessdenkiez_bew%C3%A4sserungsdaten.csv"
if (file.exists(local_path)) {
csv_data <- local_path
} else {
csv_data <- url_path
}
# 1. Baumbestandsdaten laden
anlagenbaeume <- st_read("WFS:https://gdi.berlin.de/services/wfs/baumbestand", layer = "baumbestand:anlagenbaeume")
strassenbaeume <- st_read("WFS:https://gdi.berlin.de/services/wfs/baumbestand", layer = "baumbestand:strassenbaeume")
# 2. Bewässerungsdaten laden und bereinigen
df_clean <- read.csv(csv_data, sep = ";", stringsAsFactors = FALSE, fileEncoding = "UTF-8") %>%
drop_na(lng, lat, bewaesserungsmenge_in_liter) %>%
filter(strname != "Undefined" & strname != "" & !str_detect(gattung_deutsch, "[0-9]"))
# 3. Bäume zusammenführen
baumbestand <- bind_rows(anlagenbaeume, strassenbaeume) %>%
st_transform(crs = 4326)
# 4. Geometrie extrahieren
coords <- st_coordinates(baumbestand$geom)
baumbestand$lng <- coords[, "X"]
baumbestand$lat <- coords[, "Y"]
# 5. Geometrie entfernen
baumbestand <- st_drop_geometry(baumbestand)
# 6. gisid anpassen (Unterstrich → Doppelpunkt)
baumbestand$gisid <- str_replace_all(baumbestand$gisid, "_", ":")
# 7. Bäume und Bewässerungsdaten mergen (über gisid = id)
df_merged <- baumbestand %>%
left_join(df_clean %>% select(id, bewaesserungsmenge_in_liter, timestamp),
by = c("gisid" = "id"))
# 8. Ungültige Pflanzjahre herausfiltern
current_year <- as.integer(format(Sys.Date(), "%Y"))
df_merged <- df_merged %>%
mutate(pflanzjahr = as.numeric(pflanzjahr)) %>%
filter(is.na(pflanzjahr) | (nchar(as.character(as.integer(pflanzjahr))) == 4 & pflanzjahr <= current_year))
# 9. Ergebnis speichern
if (!dir.exists("data")) dir.create("data")
write.csv2(df_merged, "data/df_merged_final.csv", row.names = FALSE, fileEncoding = "UTF-8")
# 10. Kontrolle: Anzahl der Zeilen
cat("Anzahl Bäume nach Merge:", nrow(df_merged), "\n")
cat("Anzahl eindeutiger Bäume (pitid):", n_distinct(df_merged$pitid), "\n")
cat("Anzahl Bäume mit Bewässerungsdaten:", sum(!is.na(df_merged$bewaesserungsmenge_in_liter)), "\n")
3.2.2. Geografische Zuordnung zu Berliner Bezirken#
Zielsetzung
Einige Bäume verfügen nicht über eine Angabe zu ihrem Bezirk. Um eine aggregierte räumliche Analyse (z. B. Gießverhalten nach Bezirk) zu ermöglichen, ergänzen Sie fehlende Bezirksangaben durch räumliches Verschneiden mit offiziellen Bezirkspolygonen.
Methodik
Bäume ohne Bezirk konvertieren Sie in räumliche Objekte (sf-Objekte).
Mittels eines „spatial join“ ermitteln Sie, in welchem Bezirk sich jeder Baum befindet.
Das Ergebnis führen Sie mit den ursprünglichen Daten wieder zusammen.
Code-Erklärung:
1. Die Bezirksdaten laden
local_geojson <- "data/bezirksgrenzen.geojson"
url_geojson <- "https://raw.githubusercontent.com/quadriga-dk/Tabelle-Fallstudie-3/6cd488f5f4306f9788bda3166d5929ad64312349/data/bezirksgrenzen.geojson"
if (file.exists(local_geojson)) {
bezirksgrenzen <- st_read(local_geojson)
} else {
if (!dir.exists("data")) {
dir.create("data")
}
download.file(url = url_geojson, destfile = local_geojson)
bezirksgrenzen <- st_read(local_geojson)
}
Sie laden eine geoJSON-Datei, welche die geographischen Eckdaten der Berliner Stadtbezirke enthält.
Jeder Bezirk hat dabei ein sogenanntes „Polygon“, was eine Art Umrisslinie ist.
2. Die Baumdaten laden
df_baeume <- read.csv("data/df_merged_final.csv", sep = ";", stringsAsFactors = FALSE)
Sie lesen die Tabelle mit den Baumdaten ein. Jeder Eintrag beschreibt einen Baum: z. B. seine Art, Pflanzjahr und die Koordinaten, wo er steht.
Manche Bäume haben schon einen Bezirk eingetragen, andere nicht.
3. Koordinaten umwandeln
df_baeume <- df_baeume %>%
mutate(
lng = as.numeric(gsub(",", ".", lng)),
lat = as.numeric(gsub(",", ".", lat))
)
Manche Koordinaten sind falsch formatiert (mit Komma statt Punkt, z. B. „13,405“ statt „13.405“). Das korrigieren Sie, damit der Computer die Zahlen richtig versteht.
4. Zwei Gruppen bilden:
df_mit_bezirk <- df_baeume %>% filter(!is.na(bezirk))
df_ohne_bezirk <- df_baeume %>% filter(is.na(bezirk) & !is.na(lng) & !is.na(lat))
Gruppe 1: Bäume, bei denen der Bezirk schon bekannt ist.
Gruppe 2: Bäume, bei denen der Bezirk fehlt, aber die Koordinaten vorhanden sind.
5. Gruppe ohne Bezirk in geografisches Format umwandeln
df_ohne_bezirk_sf <- st_as_sf(df_ohne_bezirk, coords = c("lng", "lat"), crs = 4326, remove = FALSE)
Die zweite Gruppe wandeln Sie in ein spezielles Format (sogenannte sf-Objekte) um.
Das ist notwendig, damit Sie mit Geodaten arbeiten können.
6. Bezirksgrenzen vorbereiten
bezirksgrenzen <- st_transform(bezirksgrenzen, crs = st_crs(df_ohne_bezirk_sf)) %>%
rename(bezirk = Gemeinde_name)
Die geographischen Daten der Bezirke bringen Sie ins gleiche geografische System wie die Baumdaten (Koordinatensystem).
Außerdem vereinfachen Sie den Namen des Bezirksfeldes in „bezirk“.
7. Räumlicher Vergleich: Welcher Baum liegt in welchem Bezirk?
df_ohne_bezirk_joined <- st_join(df_ohne_bezirk_sf, bezirksgrenzen["bezirk"], left = TRUE)
Jetzt schauen Sie für jeden Baum ohne Bezirk, ob er innerhalb eines Bezirks liegt.
Dafür überprüfen Sie, welches Bezirks-Polygon (d. h. die digitale Umrissfläche eines Bezirks, die dessen geografische Grenzen als geschlossene Fläche auf der Karte abbildet) den jeweiligen Baum „einschließt“.
Dieser Vorgang heißt „spatial join“, also ein „räumliches Verbinden“.
8. Ergebnis bereinigen und in normales Tabellenformat bringen
df_ohne_bezirk_filled <- df_ohne_bezirk_joined %>%
mutate(bezirk = ifelse(is.na(bezirk.x), bezirk.y, bezirk.x)) %>%
select(-bezirk.x, -bezirk.y) %>%
st_drop_geometry()
Die berechneten Bezirksangaben übernehmen Sie in die Tabelle.
Zusätzliche technische Spalten entfernen Sie.
Die geografischen Informationen „lassen“ Sie wieder „fallen“, damit es wieder eine normale Tabelle ist.
9. Beide Gruppen wieder zusammenfügen
df_baeume_final <- bind_rows(df_mit_bezirk, df_ohne_bezirk_filled)
Jetzt vereinen Sie alle Bäume wieder in einer Tabelle:
Die, die schon einen Bezirk hatten.
Und die, denen jetzt ein Bezirk zugeordnet wurde.
10. Auf die benötigten Spalten reduzieren
df_final <- df_baeume_final %>%
select(
gml_id,
gisid,
gattung_deutsch,
pflanzjahr,
bezirk,
bewaesserungsmenge_in_liter,
timestamp
)
Um die App performant zu halten und unnötigen Ballast zu entfernen, reduzieren Sie die finale Tabelle auf die 7 Spalten, die für das Dashboard tatsächlich gebraucht werden.
11. Neue, vollständige Tabelle speichern
# RDS speichern (wird im Dashboard später verwendet)
saveRDS(df_final, "data/df_merged_final.rds")
# Optional: Als CSV speichern (menschenlesbar, in Excel öffnbar, aber langsamer zu laden)
write.csv2(df_final, "data/df_merged_final.csv", row.names = FALSE, fileEncoding = "UTF-8")
# Kontrolle: Daten kurz anschauen
cat("Fertig! Zeilen:", nrow(df_final), "| Spalten:", ncol(df_final), "\n")
# Um die RDS-Datei später zu inspizieren, nutzen Sie:
df_check <- readRDS("data/df_merged_final.rds")
View(df_check) # Öffnet die Tabelle in R Studio
Die neue Tabelle mit allen Bäumen und Bezirken speichern Sie als
.rds-Datei. Dieses Format wird später beim Bau des Dashboards verwendet.Das zusätzliche Speichern als CSV ist optional, falls Sie die Daten auch in Excel oder anderen Programmen öffnen möchten.
Mit
readRDS()können Sie die RDS-Datei jederzeit in R Studio laden und mitView()inspizieren.
Am Ende haben Sie wieder die Möglichkeit, sich den gesamten Code anzusehen, bevor Sie im nächsten Kapitel die Entwicklungsumgebung auf den Bau des Dashboards vorbereiten.
Gesamter Code
library(sf)
library(dplyr)
# 1. Lade die Bezirkspolygone
local_geojson <- "data/bezirksgrenzen.geojson"
url_geojson <- "https://raw.githubusercontent.com/quadriga-dk/Tabelle-Fallstudie-3/6cd488f5f4306f9788bda3166d5929ad64312349/data/bezirksgrenzen.geojson"
if (file.exists(local_geojson)) {
bezirksgrenzen <- st_read(local_geojson)
} else {
if (!dir.exists("data")) {
dir.create("data")
}
download.file(url = url_geojson, destfile = local_geojson)
bezirksgrenzen <- st_read(local_geojson)
}
# 2. Lade die Baumdaten
df_baeume <- read.csv("data/df_merged_final.csv", sep = ";", stringsAsFactors = FALSE)
# 3. Koordinaten korrekt umwandeln
df_baeume <- df_baeume %>%
mutate(
lng = as.numeric(gsub(",", ".", lng)),
lat = as.numeric(gsub(",", ".", lat))
)
# 4. Zerlege in zwei Gruppen
df_mit_bezirk <- df_baeume %>% filter(!is.na(bezirk))
df_ohne_bezirk <- df_baeume %>% filter(is.na(bezirk) & !is.na(lng) & !is.na(lat))
# 5. Konvertiere nur die ohne Bezirk zu sf
df_ohne_bezirk_sf <- st_as_sf(df_ohne_bezirk, coords = c("lng", "lat"), crs = 4326, remove = FALSE)
# 6. Bezirkspolygone vorbereiten
bezirksgrenzen <- st_transform(bezirksgrenzen, crs = st_crs(df_ohne_bezirk_sf)) %>%
rename(bezirk = Gemeinde_name)
# 7. Räumlicher Join
df_ohne_bezirk_joined <- st_join(df_ohne_bezirk_sf, bezirksgrenzen["bezirk"], left = TRUE)
# 8. In DataFrame zurückwandeln
df_ohne_bezirk_filled <- df_ohne_bezirk_joined %>%
mutate(bezirk = ifelse(is.na(bezirk.x), bezirk.y, bezirk.x)) %>%
select(-bezirk.x, -bezirk.y) %>%
st_drop_geometry()
# 9. Zusammenführen mit ursprünglichen Daten, die bereits einen Bezirk hatten
df_baeume_final <- bind_rows(df_mit_bezirk, df_ohne_bezirk_filled)
# 10. Auf die 7 benötigten Spalten reduzieren
df_final <- df_baeume_final %>%
select(
gml_id,
gisid,
gattung_deutsch,
pflanzjahr,
bezirk,
bewaesserungsmenge_in_liter,
timestamp
)
# 11. Ergebnis speichern
# RDS speichern (wird im Dashboard später verwendet)
saveRDS(df_final, "data/df_merged_final.rds")
# Optional: Als CSV speichern
write.csv2(df_final, "data/df_merged_final.csv", row.names = FALSE, fileEncoding = "UTF-8")
cat("Fertig! Zeilen:", nrow(df_final), "| Spalten:", ncol(df_final), "\n")
# Um die RDS-Datei später zu inspizieren:
df_check <- readRDS("data/df_merged_final.rds")
View(df_check)