
3.3. Diskriminierungssensible Metadaten#
Klassifizierungssysteme wie Metadatenstandards, Taxonomien oder Ontologien sind, wie zuvor erwähnt, zur Identifizierung und Organisation von Daten essentiell. Gleichsam sind sie aber auch immer Wissensmodelle, d. h., dass Wissen über festgelegte Strukturen und Beschreibungspraktiken modelliert wird. Dazu gehören die Auswahl eines kontrollierten Vokabulars sowie bereits die Auswahl der zu beschreibenden Elemente selbst. Klassifizierungssysteme sind dahingehend weder wertneutral oder “objektiv” noch selbsterklärend. Sie sind historisch situiert und stellen eine spezifische Sichtweise von Welt- und Wissensordnungen her. Hierzu schreibt Drucker:
“All classification systems bear within the ideological imprint of their production.”
Sichtbar wird solche Kritik an häufig vorzufindenden Begriffen wie beispielsweise “creator”. Kunstproduktion ist nicht zwangsweise in jeder Community an eine konkrete “schöpfende” Person gebunden. Oft entstehen Werke und Arbeiten in kollektiven Herstellungsdynamiken, die explizit versuchen gesellschaftlich verfestigte Hierarchien zu überwinden. Kollektive Arbeitsweisen können so im schlimmsten Fall ungenannt und entsprechend ungewürdigt bleiben (“uncredited”).
Wie bereits das Beispiel des generischen Metadatenfeldes “creator” zeigt, ist die Frage nach dem Umgang mit diskriminierenden Metadaten sehr komplex. Dabei müssen einerseits wissenschaftliche Zuschreibungs- und Erschließungspraktiken selbst hinterfragt werden, andererseits geht es aber auch um die konkrete Erfassung von sensiblen Daten, wie beispielsweise rassistische oder sexistische Titel oder Inhalte in Metadaten.
Dieser kurze Exkurs soll dazu anregen, eine diskriminierungssensible Überprüfung von Metadaten – wo sinnvoll – in die eigenen Projektabläufe zu integrieren.
Beispiele diskriminierender Metadaten#
Um Anforderungen zu formulieren, die bei der Identifizierung diskriminierender und sensibler Metadaten in der Arbeit mit Forschungsdaten helfen, soll zunächst an zwei ausgewählten Fallbeispielen gezeigt werden, an welchen Stellen bzw. in welcher Form diskriminierende Beschreibungen auftreten können. Dabei orientieren wir uns an Beispielen, die für die Geisteswissenschaften relevant sind.
Fallbeispiel 1: Reproduktion kolonialer Narrative in Metadaten#
In der Synopsis zu Der Schatz im Silbersee (1962) von Harald Reinl auf filmportal.de wird die Filmhandlung mit kolonial geprägten Begriffen nacherzählt.
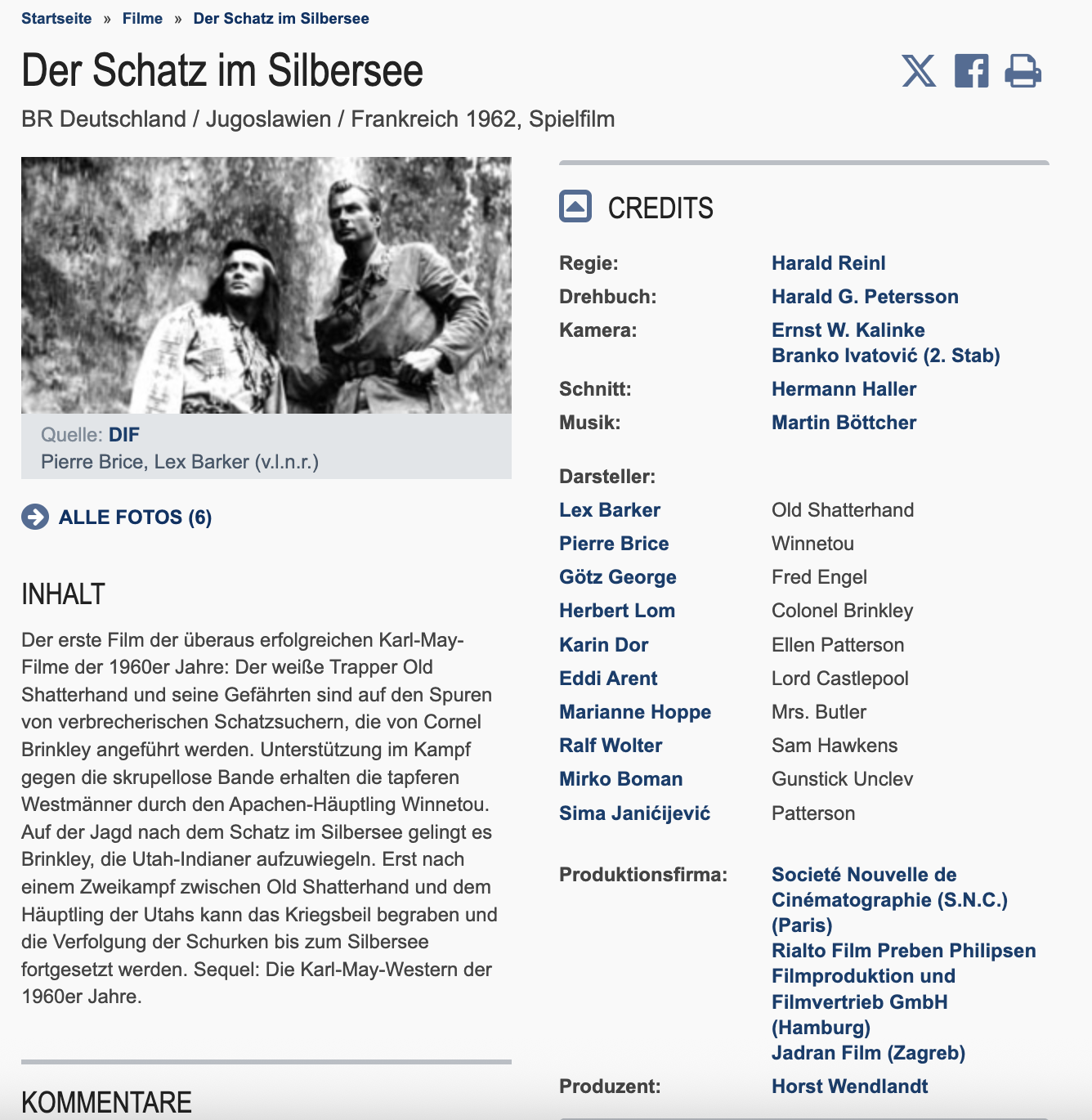
Fig. 3.12 Screenshot aus dem Eintrag von filmportal.de zu Der Schatz im Silbersee (R: Harald Reinl, BRD, YUG, FRA 1992)#
Genauer heißt es in einem Ausschnitt der Beschreibung:
“Unterstützung im Kampf gegen die skrupellose Bande erhalten die tapferen Westmänner durch den Apachen-Häuptling Winnetou. Auf der Jagd nach dem Schatz im Silbersee gelingt es Brinkley, die Utah-Indianer aufzuwiegeln.”
Dabei sind nicht nur die Begriffe “Häuptling” oder “Indianer” aufgrund ihrer kolonialen Prägung aus heutiger Sicht problematisch, ferner wird in der Inhaltsbeschreibung das koloniale Narrativ des Films ungebrochen reproduziert und übernommen: von “tapferen Westmännern” bis zu “aufgewiegelten Indianern”.
Zusätzlich verstärkt das im obigen Screenshot sichtbare Filmstill diese Fortschreibung. Die ausgewählte Darstellung verfestigt die kolonialen Verhältnisse des Beschreibungstextes. Dadurch wird deutlich, inwiefern durch textuelle und visuelle Metadatenelemente filmische Narrative und Ideologien nicht nur dokumentiert, sondern impliziert stabilisiert werden.
Fallbeispiel 2: Rassistische Titel#
Neben dem Einzug diskriminierender Elemente in beschreibende Metadatenfelder stellt sich noch die Frage, wie mit der Darstellung und Reproduktion bibliographischer Angaben und deren Kontextualisierung umgegangen werden soll. Dies betrifft insbesondere Werktitel, die rassistische Sprache aufweisen.
Dogtas et al. verweisen in ihrem Aufsatz auf den Buchtitel “N*plastik”[1] von Carl Einstein , vorzufinden in diversen Datenbanken wie beispielsweise auch im Katalog der Deutschen Nationalbibliothek (kurz: DNB). Im vorliegenden Datensatz der DNB wird der Titel ohne Verweis auf seine zeitgenössische Problematik kommentarlos in den Metadaten reproduziert.
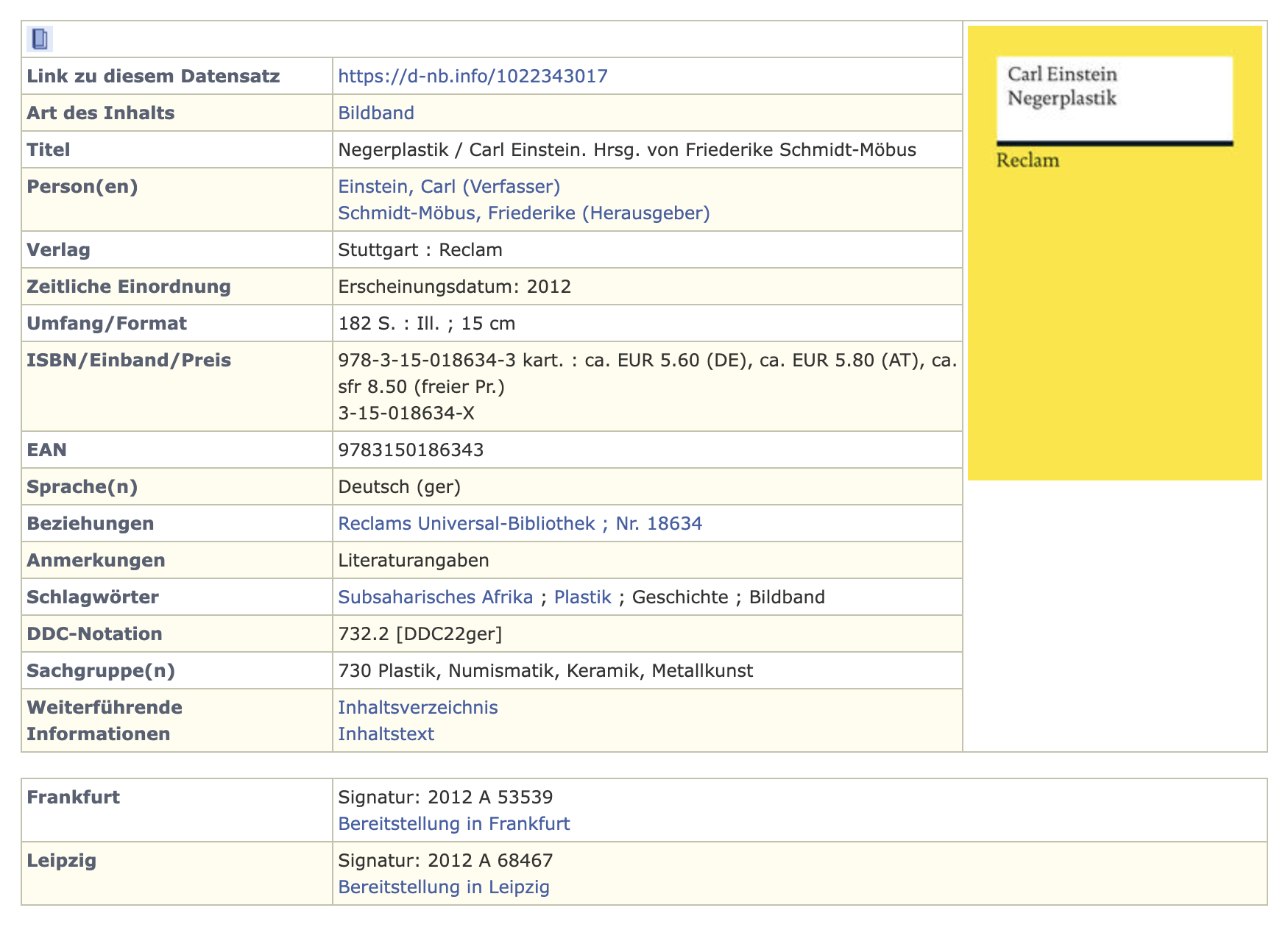
Fig. 3.13 Screenshot aus dem Eintrag des Datensatzes zum Buchtitel “N*plastik” von Carl Einstein#
Für Dogtas et. al. führt die Ausschreibung des N-Wortes zur kontinuierlichen Fortschreibung seiner rassistischen Implikationen sowie zur Verfestigung der dem Begriff immanenten “komplementären Fiktion der Überlegenheit weisser” (Herv. i. O.). Die unhinterfragte Übernahme diskriminierender Praktiken und Sprache führe also dazu, dass exklusive und diskriminierende Seiten der Gesellschaft weiter Einzug in unsere Systeme und Strukturen erhalten – so das Argument. Das Sammeln, Bewahren und Erforschen von Ressourcen ist jedoch darauf ausgelegt, die Entstehungsmerkmale zu erhalten und sie so abzubilden, wie sie sich in ihren historischen und gesellschaftlichen Kontexten präsentierten/präsentieren.
Wie also kann ein diskriminierungssensibler Umgang gefunden werden, der die aktuellen Debatten und Diskurse mitdenkt, gleichzeitig jedoch die historischen Implikationen der Ressourcen beibehält?
Diskriminierungssensible Praktiken#
Es gibt diverse Methoden und Umgangsweisen, um diskriminierungssensible Praktiken zur Erfassung von Metadaten zu etablieren. Gängig sind insbesondere (nach Dogtas et. al.):
Disclaimer (Titelkontexualisierung)
Disclaimer bzw. Statements schreiben mit dem Hinweis auf diskriminatorische Inhalte
Ggf. Informationen zu Strategien und Zielen zum Umgang bereitstellen
Bereitstellung weiterführender Informationen und Feedback-Optionen
Verfremdungsvarianten
Abweichung der konventionellen Darstellungsweise (z. B. durch Sternchen, durchgestrichen, gespiegelt, Begriffe auf den Kopf stellen)
Umschreibung von ursprünglichen (veralteten) Synopsen und Beschreibungstexten oder ihre diskursive Kontextualisierung
Mehrfachbenennung bzw. parallele Benennung (historischer Titel / bevorzugte Bezeichnung)
Alternative, inklusive kontrollierter Vokabulare oder Glossare (siehe unten)
Wie solche Strategien in der Praxis umgesetzt werden, möchten wir anhand von zwei Beispielen exemplarisch veranschaulichen:
Zum einen an der kontextualisierten Beschreibung (Kurzinhalt) des NS-Propagandafilms J*d Süß[2] (1940) von Veit Harlan in der Datenbank der Murnau Stiftung. In der hier vorliegenden Beschreibung wird der Inhalt filmnah eingeordnet ohne jedoch antisemitische und propagandistische Sprache zu übernehmen – im Gegenteil: Der Text kontextualisiert die historischen Umstände und markiert den Film ausdrücklich als propagandistisch-ideologisches Werk.

Fig. 3.14 Screenshot aus dem Eintrag der Murnaustiftung zu J*d Süß (R: Veit Harlan, DEU 1940)#
Zum anderen möchten wir noch auf das Statement der University of Michigan Library verweisen. Einerseits wird festgehalten, dass beschreibende Metadaten grundsätzlich nicht neutral sind, andererseits reagiert die Bibliothek direkt auf diesen Umstand und benennt Maßnahmen zur Identifizierung, Kontextualisierung und deren Überarbeitung.
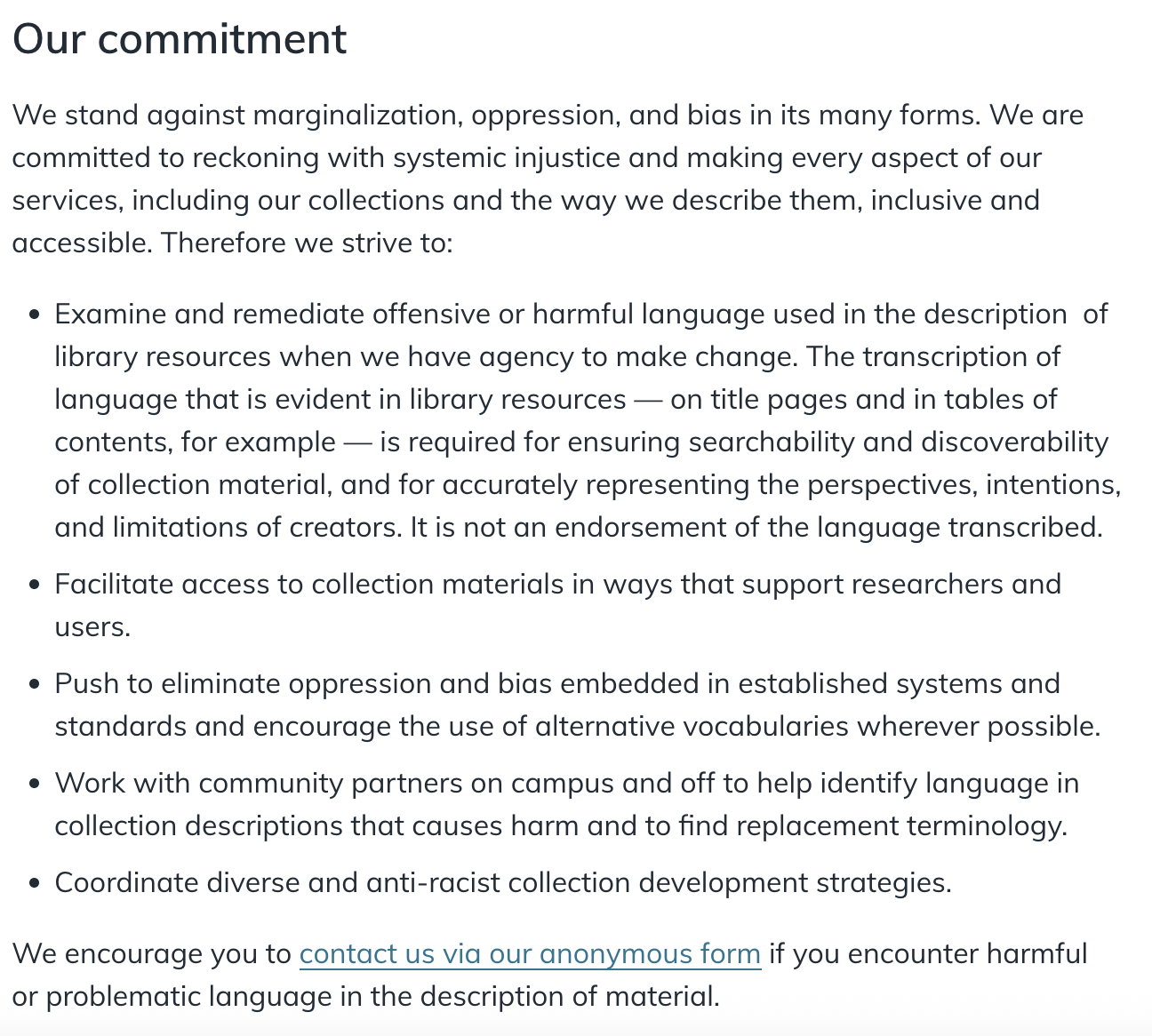
Fig. 3.15 Statement der University of Michigan Library#
Wie die genannten Methoden und Beispiele zeigen, gibt es unterschiedliche Wege im Umgang mit diskriminierenden Metadaten. Für die praktische Arbeit in film- und geisteswissenschaftlichen Projekten haben wir daher eine Entscheidungshilfe in Form eines Fragenkatalogs zusammengestellt, der als Orientierung und Impuls dienen soll.
Praxisnaher Fragenkatalog für Projekte#
Diskriminierungssensible Daten und Metadaten
A: Korpus
- Wie ist der Korpus geprägt?
- Welche Schwerpunkte hat er (zeitlich, räumlich, sprachlich/kulturell)?
- Enthält die Auswahl des Korpus bereits strukturelle Ausschlüsse (westl. Produktionen, Kanon, Mainstream)?
- Welche Perspektiven fehlen?
B: Inhalte
- Gibt es eine inhaltliche Nähe zu sensiblen Themen (z. B. Rassismus, Kolonialismus, Antisemitismus, Sexismus, Queerfeindlichkeit, Ableismus)?
- Wenn JA – worin zeigt sich das?
- Filminhalt / Dramaturgie
- Sprache oder Dialoge
- Paratexte (Trailer, Plakate o.Ä.)
- Bibliografische Angaben (Titel, Untertitel usw.)
- Beschreibungstexte / Synopsen
- Schlagworte, Genres, Kategorien
C: Metadaten & Begriffe
- Gibt es problematische Werktitel, Bezeichnungen oder Beschreibungen in den projekteigenen Metadaten?
- Wenn JA – welche?
- Welche diskriminierungssensiblen Strategien und Methoden sollen zum Einsatz kommen?
- Disclaimer / kontextualisierende Hinweise
- Umschreibung oder Neuformulierung von Synopsen oder Beschreibungstexten
- Diskursive Kontextualisierung
- Mehrfachbenennung / parallele Benennung (z. B. "Historischer Titel" / "bevorzugte Bezeichnung")
- Verfremdung oder Markierung problematischer Begriffe (z. B. Sternchen, Durchstreichung o.Ä.)
- Werden Daten oder Metadaten nachgenutzt?
- Wenn JA – gibt es problematische Werktitel oder Beschreibungen in nachgenutzten Daten und Metadaten?
- Wenn JA – wie kann verhindert werden, dass diskriminierende Beschreibungen reproduziert werden?
- Trennung von ursprünglichen Beschreibungen und eigenen Beschreibungen
- Kennzeichnung als historisches Zitat oder Fremdmetadaten
- Ergänzende Hinweise oder Disclaimer
- Welche Vokabulare, Thesauri und Normdaten werden verwendet?
- Enthalten diese veraltete oder diskriminierende Begriffe?
- Wenn JA – gibt es alternative, inklusivere (kontrollierte) Vokabulare oder Glossare?
D: Datenquellen
- Werden Daten von Datenbanken, Webseiten oder Plattformen gescraped oder via API übernommen (z. B. TMDB, Letterboxd, OMDb)?
- Gibt es problematische Kategorisierungen, Tags oder Genres?
- Wer betreibt die Plattform (größere Konzerne, Archive, Communities)?
- Welche Sichtbarkeiten und Ausschlüsse (z. B. algorithmische Rankings) müssen bedacht werden?
- Werden Nutzer:innenkommentare, Ratings oder Nutzer:innen-Tags übernommen?
- Wie wird mit diskriminierenden Inhalten umgegangen?
- Erfolgt eine klar markierte Trennung zwischen Nutzer:innenkommentaren und Projektbeschreibungen?
- Wie wird die Auswertung diskriminierungssensibel kontextualisiert?
E: Historische Kontexte
- Gibt es aufgrund der historischen Situiertheit der Werke gewisse diskriminierende oder marginalisierende Elemente in den Metadaten (z. B. Kolonialfilme, NS-Propagandafilme)?
- Sind historisch situierte diskriminierende Elemente identifizierbar?
- Wie können historische Angaben erhalten bleiben, ohne diskriminierende Beschreibungen zu reproduzieren?
- Trennung von Originaltitel/-beschreibung und Projektzuordnung
- Ergänzung von Kontextinformationen oder Content Warnings
- Klare Kennzeichnung historischer Sprache
F: Rollen, Gewerke
- Werden Gewerke und Beteiligte in den Metadaten beschrieben (z. B. Regie, Drehbuch, Kamera, Montage)?
- Enthält die Verteilung oder Benennung der Rollen mögliche diskriminierende Elemente oder Ausschlüsse?
- Werden Selbstbezeichnungen (z. B. Namen, Pronomen, Rollen) respektiert?
- Gibt es strukturelle Muster wie systematische Unterrepräsentationen?
- Wie können solche Muster kenntlich gemacht oder kritisch kommentiert werden?
Weiterführende Links und Informationen
Wörterbücher, Vokabulare & Thesauri
Handreichungen