
4.2. Publikationswege und -formate#
Es gibt zahlreiche Möglichkeiten, Forschungsdaten zu publizieren und sie für die Wissenschaftscommunity zugänglich sowie nachnutzbar zu machen. Im Folgenden stellen wir die relevantesten Publikationswege und -formate praxisnah vor und kennzeichnen jeweils das erforderliche technische Niveau.
Repositorien#
→ Niveau: Basis / Fortgeschritten
Inhalte anzeigen
Sehr beliebt und niedrigschwellig in den erforderlichen Kompetenzen sind wissenschaftliche Repositorien. Repositorien sind digitale Speicherorte und Datenlager, in denen Forschungsdaten veröffentlicht, verwaltet und aufbewahrt werden können. Die in einem Repositorium publizierten Daten können Nutzer:innen, zumeist öffentlich und teils beschränkt, zugänglich gemacht werden.
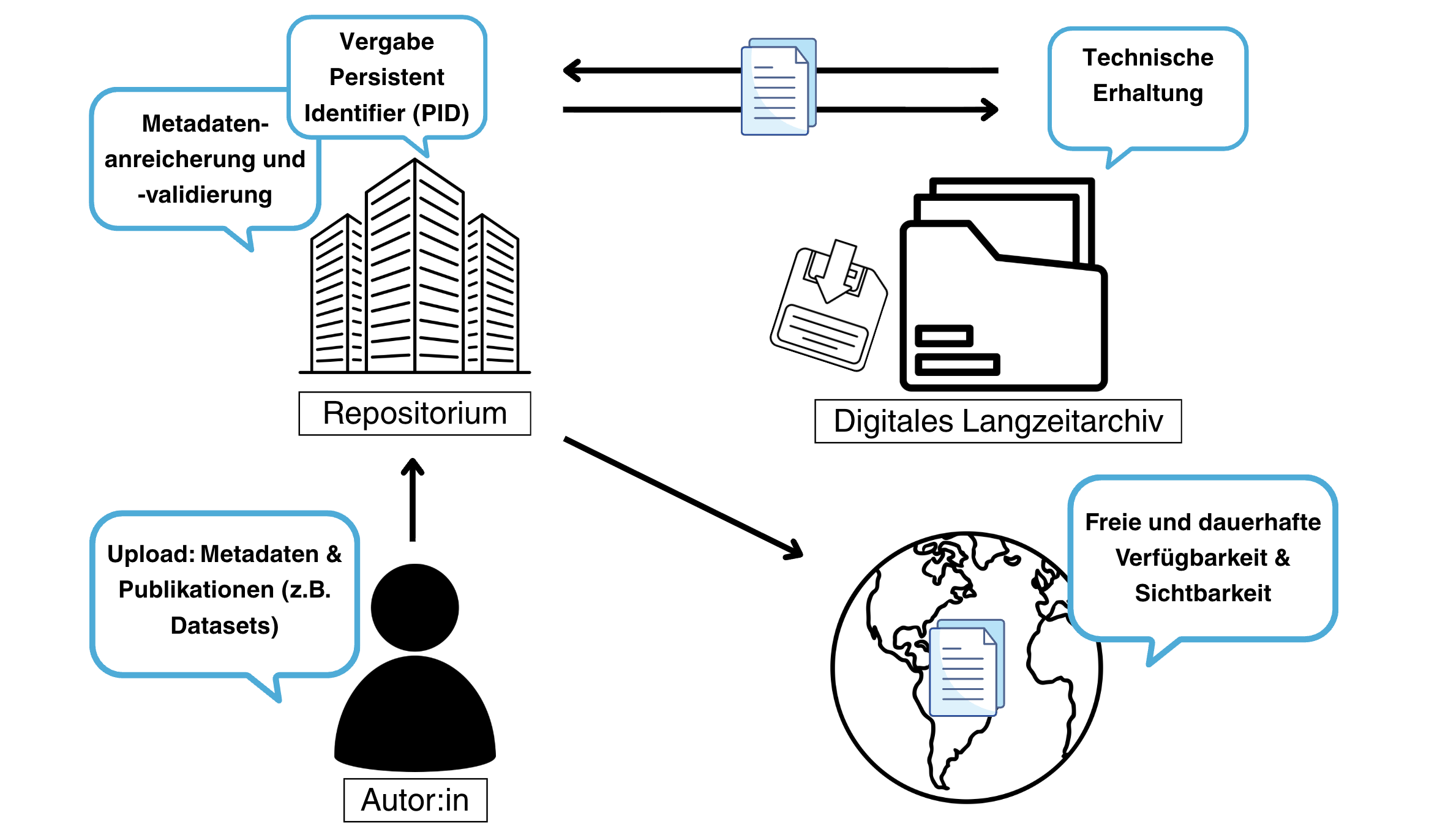
Fig. 4.2 Daten publizieren in Repositorien#
Unterschieden wird zwischen institutionellen, disziplinären oder generischen Repositorien. (z. B. Refubium der FU Berlin oder der edoc-Server der HU Berlin) betrieben und ermöglichen ihren Mitgliedern die digitale Publikation wissenschaftlicher Dokumente.
Fig. 4.3 Exemplarische Ansicht einer Suche im Refubium der FU#
Disziplinäre Repositorien hingegen sind institutsübergreifend und Forschungsorte der Exploration der jeweiligen Fachdisziplin. Einer der wichtigsten Repositorien der Film- und Medienwissenschaft ist media/rep/. In dem Open-Access-Fachrepositorium werden Publikationen, Aufsätze, Forschungsdaten und andere Ressourcen der Film- und Medienwissenschaft kostenfrei und ohne Zugangsbeschränkung verfügbar gemacht. Es dient als zentrales und dauerhaftes Archiv der Disziplin und fördert Wissenschaft, Austausch und Forschung.
Fig. 4.4 Startseite des film- und medienwissenschaftlichen Repositoriums media/rep/#
Zu den etablierten generischen Repositorien zählen Zenodo, GitHub und Figshare. Sie eignen sich insbesondere für disziplinübergreifende Datensätze, Code und Projektressourcen. Für die Datenpublikation sind persistente Identifikatoren (z. B. DOI) und Versionierungsmöglichkeiten entscheidend. Über Repositorien wie Zenodo oder Figshare werden bei der Publikation DOIs vergeben. GitHub hingegen wird dafür häufig mit einem DOI-fähigen Archivierungsdienst wie Zenodo kombiniert.
Fig. 4.5 Startseite der etablierten generischen Repositorien Zenodo, GitHub und Figshare#
Publikation auf GitHub und Zenodo
Im Kapitel Dateninfrastrukturen werden die Schritte zur Publikation auf GitHub und Zenodo im Detail erläutert.
Übersicht für Repositorien mit DOI-Vergabe#
| Plattform | Schwerpunkt | DOI-Vergabe | Link |
|---|---|---|---|
| Zenodo | Forschungsdaten, OER, Code, JupyterBooks | ✅ Ja | zenodo.org |
| Figshare | Artikel, Datasets, Videos | ✅ Ja | Figshare |
| GitHub | Code, Versionierung, Workflows, Releases | ⚠️ Nein (DOI i. d. R. über Zenodo-Archivierung) | GitHub |
| Institutionelles Repositorium | z. B. FU Berlin, TIB Hannover | ✅ Ja (bei Veröffentlichung) | via Hochschulbibliothek |
| OSF.io | Projekte & Preprints | ✅ Ja | OSF.io |
| Dryad | Datensätze (v. a. begleitend zu Publikationen) | ✅ Ja | Dryad |
Im nächsten Kapitel Ressourcen und Entscheidungshilfen gibt es eine ausführliche Liste mit relevanten Repositorien und Repositorienfindern - mit Schwerpunkt auf Film-, Medien -und Geistenwissenschaften.
Publizierte Daten in einem Repositorium: Fallbeispiel “Affektrhetoriken des Audiovisuellen”#
Das Forschungsprojekt ”Affektrhetoriken des Audiovisuellen” (kurz: AdA) stellt seine filmanalytischen Annotationsdaten als ein öffentlich zugängliches Datenpaket zur Nachnutzung in einem GitHub-Repositorum zur Verfügung. Die Projektergebnisse und Forschungsartefakte umfassen: eine Filmontologie und das Vokabular (AdA-Filmontology), ein projektspezifisches Template für die Annotation mit dem Tool Advene sowie die Annotationsdatensätze selbst.
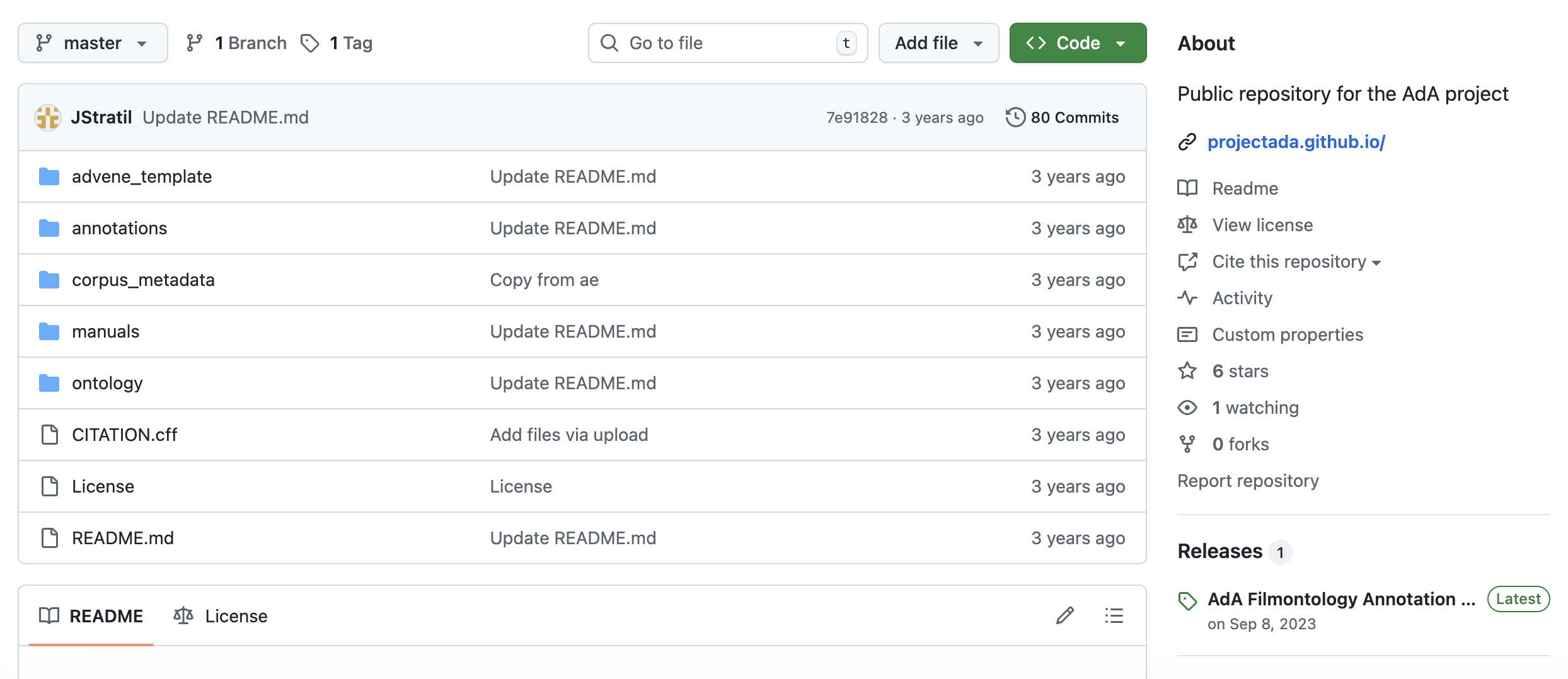
Fig. 4.6 Öffentliches Repositorium des AdA-Projekts#
Der Datensatz umfasst über 92.000 feingranulare, timecode-basierte Annotationen und wird durch Korpus-Metadaten ergänzt.
Das AdA-Projekt ist ein gutes Beispiel dafür, wie ein Repositorium nicht einzig als Ablage genutzt wird, sondern durch ausführliche Dokumentation, Versionierung und Distribution die Weiterverwendung der Daten einerseits, sowie die eigenständige Reproduktion der Datenerhebung andererseits sichergestellt werden kann.
Data Paper / Data Jounal#
→ Niveau: Basis
Inhalte anzeigen
Ein Data Paper ist eine publizierte Dokumentation zu einem Datensatz, welcher umfangreiche Informationen über verschiedene Komponenten der Forschungsdaten enthält. In der Dokumentation wird beschrieben, wie, wann und warum die Daten erhoben wurden und was der Datensatz umfasst. Im Vordergrund eines Data Papers steht die Beschreibung des selbst generierten oder nachgenutzten Forschungsmaterials. Die Behandlung der wissenschaftlichen Fragestellung selbst ist nicht zentral.
Ähnlich wie bei wissenschaftlichen Artikeln, gibt es bei Data Papers ebenfalls Peer-Reviews.
Folgende Inhalte sollte ein Data Paper enthalten:
Informationen zur Datenerhebung und -verarbeitung
Informationen zur Datenqualität und -struktur
Potentielle Anwendungsfälle für die Nachnutzung
Metadaten und Zugangsbedingungen

Fig. 4.7 Infografik Data Paper und Data Journals, © TU Berlin CC0#
In fachspezifischen Data Journals können Data Paper eingereicht werden. Etablierte Journals für die Film- und Medienwissenschaft bzw. Digital Humanities sind NECSUS oder das Journal of Open Humanities Data.
Ein Beispiel für ein Data Paper aus der Fimwissenschaft ist der Aufsatz ”How to capture the festival network: Reflections on the Film Circulation datasets” publiziert auf NECSUS von Skadi Loist und Evgenia (Zhenya) Samoilova. Darin dokumentieren die Autor:innen Kontext, Struktur, Aufbereitung und Auswertung ihres Film Circulation Project Datensatzes mit entsprechenden Berechnungen, Logiken und Visualisierungen. Als Necsus-Datapaper wird der Datensatz somit zugleich als eigenständiges Forschungsergebnis sichtbar.
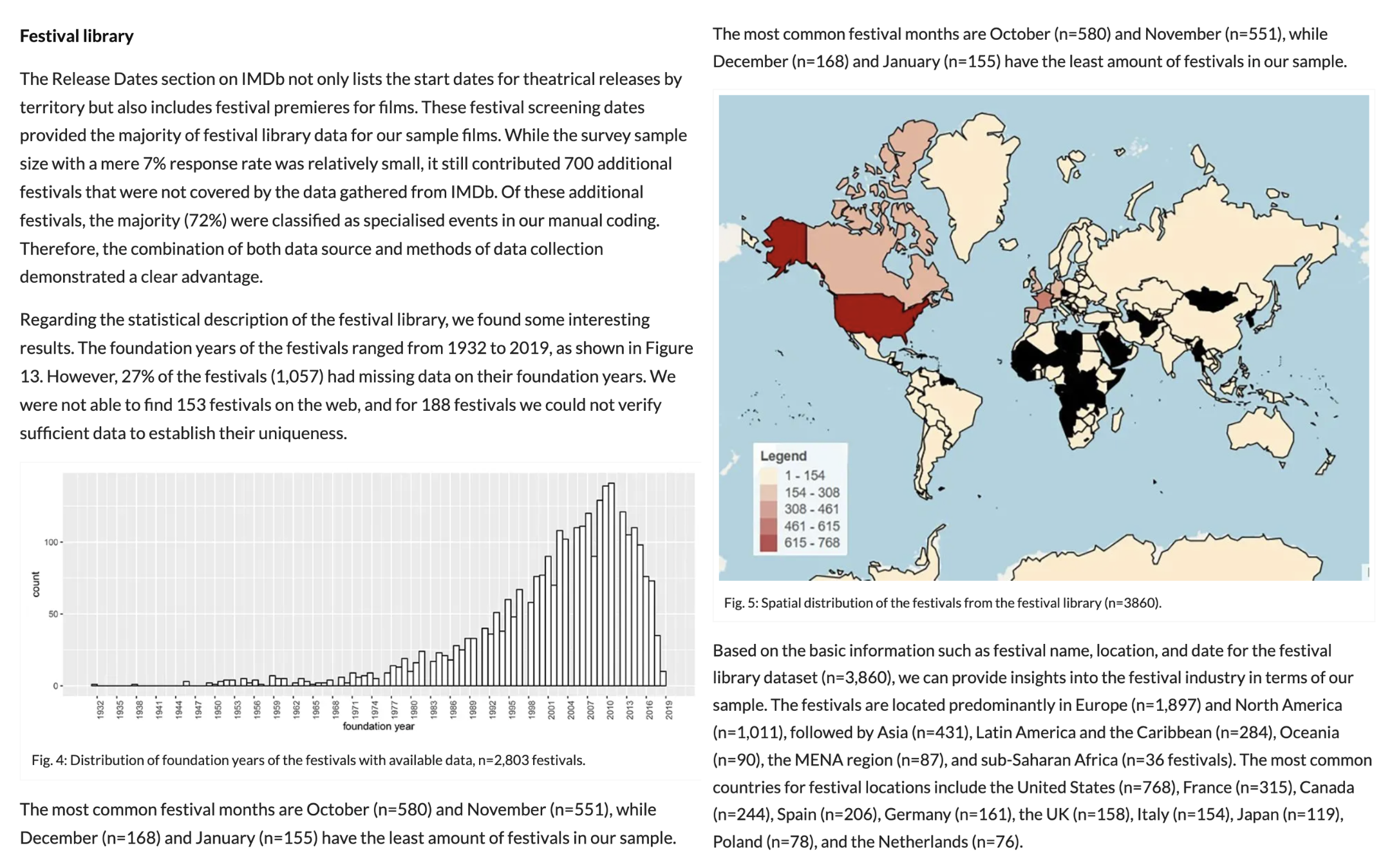
Fig. 4.8 Ausschnitt aus dem Data Paper von Skadi Loist und Evgenia (Zhenya) Samoilova auf NECSUS#
GLAM und interaktive Websiten#
→ Niveau: Fortgeschritten / Expert:in
Inhalte anzeigen
Wofür steht die Abkürzung GLAM?
GLAM steht für Galleries, Libraries, Archives, Museums und ist ein Sammelbegriff für kulturelle Gedächtnisorganisationen.
Neben niedrigschwelligen Einstiegen in die Datenpublikation, wie etwa über Repositorien und Data Papers, können Forschungsdaten ebenfalls auf eigens entwickelten Plattformen oder Webseiten bereitgestellt und kuratiert werden. Je nach Erfahrungslevel ist damit jedoch ein höherer technischer wie auch zeitlicher Aufwand verbunden. Solche Publikationsformate empfehlen sich für größere und langfristig geförderte Projekte mit entsprechenden Ressourcen. Sind in kleineren Projekten die notwendigen technischen Skills vorhanden, können dort auch solche Lösungen kreativ umgesetzt und entwickelt werden.
Klassische Beispiele kommen aus dem GLAM-Kontext und sind kuratierte Datenbanken wie das European Film Gateway. Das EFG ist ein Portal mit zahlreichen filmhistorischen Materialien sowie den dazugehörigen Metadaten und Beschreibungen (u.a. Fotos, Plakate, Programme, Zensurdokumente usw.).
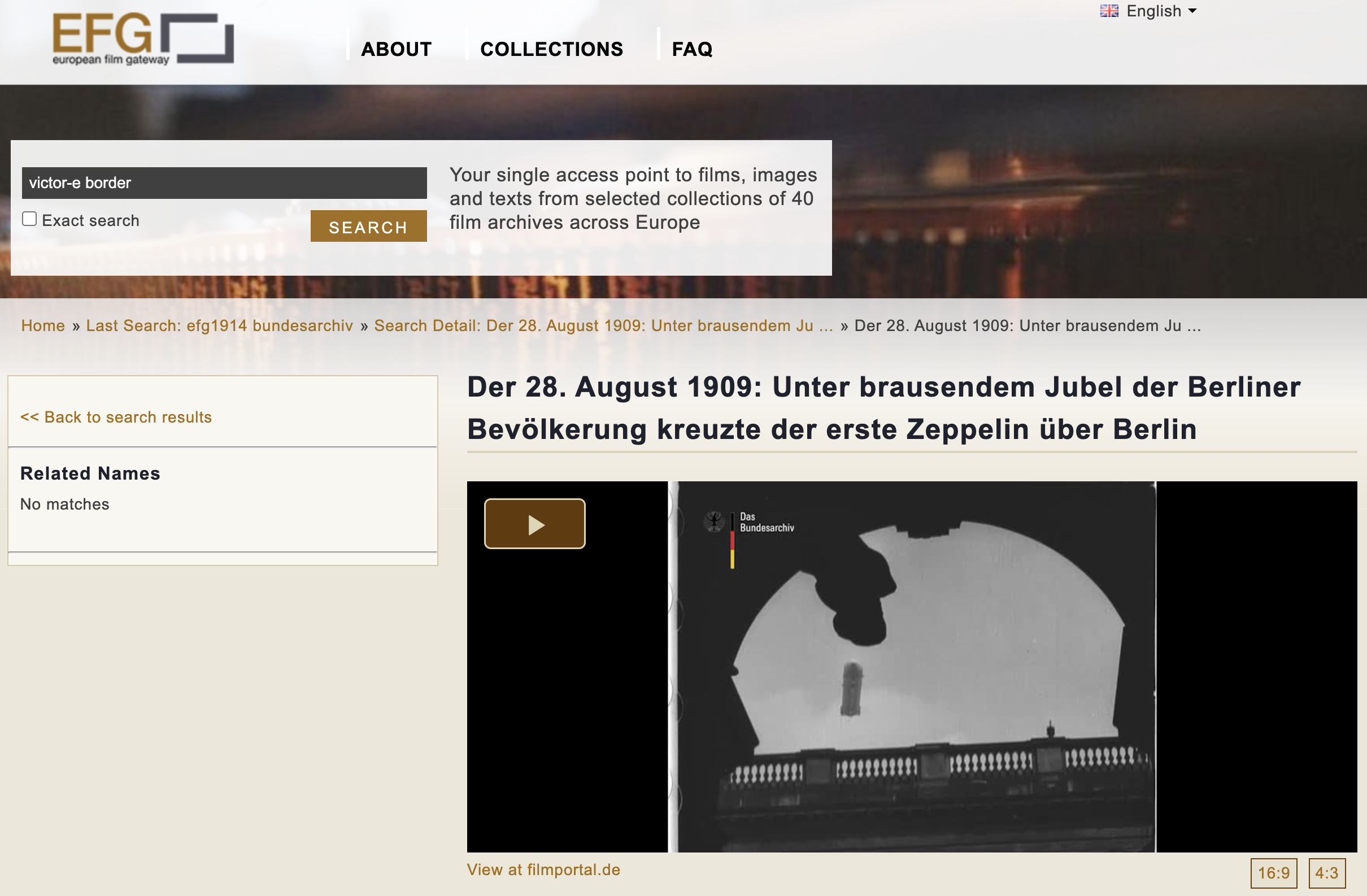
Fig. 4.9 Ergebnisansicht eines Beitrags aus dem Bundesarchiv auf dem EFG-Portal, © Public Domain#
Neben klassischen GLAM-Portalen gibt es auch Forschungsprojekte mit umfangreichen Datenmengen, die zur Exploration und Nutzung ihrer Daten eigens dafür entwickelte interaktive Webseiten konzipiert und umgesetzt haben. So beispielsweise der Women Film Pioneers Explorer unter der Leitung von Dr. Sarah-Mai Dang und Prof. Dr. Thorsten Thormählen. Der Explorer ermöglicht anhand interaktiver Visualisierungen die Erkundung biografischer Datenmengen von Frauen der frühen Filmgeschichte (1890-1920).
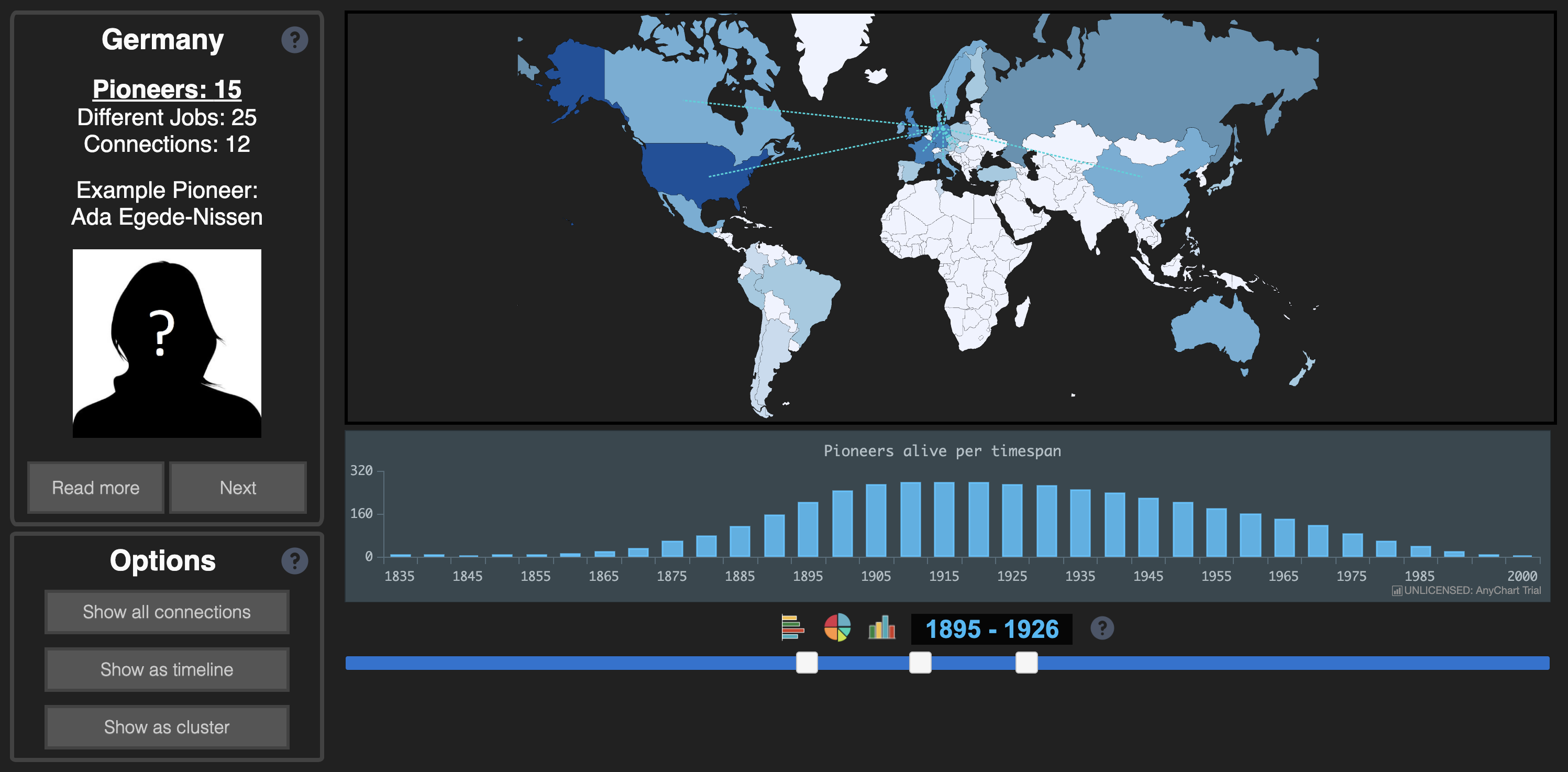
Fig. 4.10 Visualisierung des transnationalen Netzwerkes von Filmpionierinnen aus den Daten des Women Film Pioneers Projektes, © CC BY-SA 4.0#
Weitere Beispiele bzw. Auflistungen für GLAM-Datenbanken/Portale sowie (interaktive) Webseiten in der Film- und Medienwissenschaft gibt es im nächsten Kapitel Ressourcen und Entscheidungshilfen.
APIs#
→ Niveau: Expert:in
Inhalte anzeigen
Wichtiger Hinweis
Sowohl die Bereitstellung als auch die Nutzung von APIs erfordern (fortgeschrittene) Programmierkenntnisse.
Ergänzend zu den bisher genannten Publikationswegen und -formaten gibt es für technisch versierte Forschende und Projekte auch die Option, Forschungsdaten über API-Schnittstellen zugänglich zu machen. D. h., dass die Daten primär als ein Abfragedienst bereitgestellt werden. Dies ist allerdings nur dann sinnvoll, wenn es sich um komplexe, relationale und dynamische Datenstrukturen handelt (z. B. große Korpora, Distributionsnetzwerke oder Filmografien).
Was sind API-Schnittstellen?
Eine API (Application Programming Interface) ist eine Programmierschnittstelle zwischen verschiedenen Softwareanwendungen. Sie ermöglicht die automatisierte Kommunikation zwischen Programmen, um Daten oder Funktionen auszutauschen, also eine Form der „Maschine-zu-Maschine“– Kommunikation. Über APIs können Entwickler:innen auf Inhalte, Daten oder Dienste anderer Systeme zugreifen und diese in eigene Anwendungen integrieren.
Im Bereich der Digital Humanities ist das DraCor-Projekt unter der Leitung von Prof. Dr. Frank Fischer (FU Berlin) ein gutes Beispiel dafür, wie Forschungsdaten über eine API-Schnittstelle (DraCor-API) bereitgestellt werden können. DraCor (drama corpora) ist eine offene digitale Infrastruktur, die für die computergestützte Untersuchung (vorwiegend) europäischer Dramatik von der griechisch-römischen Antike bis zum 20. Jahrhundert entwickelt wurde.
Fig. 4.11 Dokumentation der DraCor API zur programmgesteuerten Abfrage europäischer Dramatik ((DraCor-API))#
Weiterführende Links
Für eine vertiefende Auseinandersetzung mit API-Schnittstellen haben wir eine kleine Auswahl ergänzender Links zusammengestellt:
Aufbauend auf den zuvor eingeführten Grundlagen zur Datenpublikation in der Filmwissenschaft stellt das nächste Kapitel zentrale Ressourcen und Entscheidungshilfen zur Verfüung, um geeignete Infrastrukturen zu identifizieren, den Publikationsprozess zu strukturieren sowie sich über rechtliche Rahmenbedinungen zu informieren.