
Anreicherung und Publikation von Annotationsdatensets auf Repositorien#

Fig. 1 Moviebarcode aus der Naturdokuserie The Blue Planet, Staffel 5/Episode 1: Seasonal Seas (BBC Earth)#
Wie können filmwissenschaftliche Forschungsdaten für die Publikation aufbereitet werden?
Entlang eines praxisnahen Beispiels eines Forschungsprojektes zeigt die vorliegende Fallstudie in Form eines interaktiven Jupyter Books, wie bestehende Datensätze aus Forschungskontexten systematisch aufbereitet, bereinigt und angereichert werden können. Bei dem Fallbeispiel handelt es sich um das filmwissenschaftliche Teilprojekt C05 Intervenierende Weltentwürfe: Audiovisualität des Klimawandels des Sonderforschungsbereichs 1512 Intervenierende Künste der Freien Universität Berlin, welches sich in drei spezialisierten Unterprojekten mit der Analyse audiovisueller Kompositionsmuster und ihrer Rolle bei der Revision gegenwärtiger gesellschaftlicher Zustände im Kontext des Klimawandels auseinandersetzt.
Ziel ist es, Strategien zu entwickeln und aufzuzeigen, die eine standardkonforme Publikation filmwissenschaftlicher Daten und Datensätze nach den Leitlinien guter wissenschaftlicher Praxis ermöglichen. Der Fokus liegt auf der Publikation der Daten auf geeigneten Plattformen bzw. Repositorien. Dabei sollen sowohl fachspezifische Inhalte zu Metadatenstandards und Forschungsdatenmanagement vermittelt als auch grundlegende Kompetenzen und Kontexte adressiert werden.
Diese Open Educational Ressource (OER) knüpft direkt an die erste QUADRIGA Fallstudie des Datentyps: Bewegtes Bild ”Affektrhetorik in Online-Videos zur Klimakrise. Datengestützte Analysen audiovisueller Muster” an. Dort wird, ausgehend von einer Forschungsfrage, vermittelt, wie filmanalytische Annotationsdaten erstellt und visualisiert werden können. Es werden folglich Annotationsdatensätze produziert.
Wie können solche (und/oder ähnliche) Annotationsdaten publiziert werden? d. h. was für Eigenschaften müssen die Dateien aufweisen, damit sie publiziert werden können? Welche Vorbereitungen sind nötig, und welche Metadatenschemata und Systematisierungsprozesse sind erforderlich, damit die Forschungsdaten auch für andere Wissenschaftler:innen erschließbar und nachnutzbar sind?
Ergänzend soll gezeigt werden, wie diese Annotationsdatensets noch angereichert werden können – beispielsweise durch sogenannte Moviebarcodes (Fig. 1). Diese bieten eine einfache und schnell reproduzierbare Möglichkeit, das Farbspektrum ganzer Filme oder einzelner Szenen visuell darzustellen, um den Datensätzen eine zusätzliche analytische Dimension hinzuzufügen.
Aufbau der Lerninhalte#
Die folgende Übersicht zeigt die fünf Schritte bzw. Lernmodule (Kap. 2–6) unserer OER zur Publikation filmwissenschaftlicher Datensätze. Die ersten drei Module vermitteln Grundlagenwissen. Die OER ist kleinteilig konzipiert und besteht aus mehreren Unterkapiteln eines Lernmoduls. Dadurch können bestimmte Lerneinheiten/Unterkapitel – mit entsprechendem Vorwissen – auch übersprungen werden.
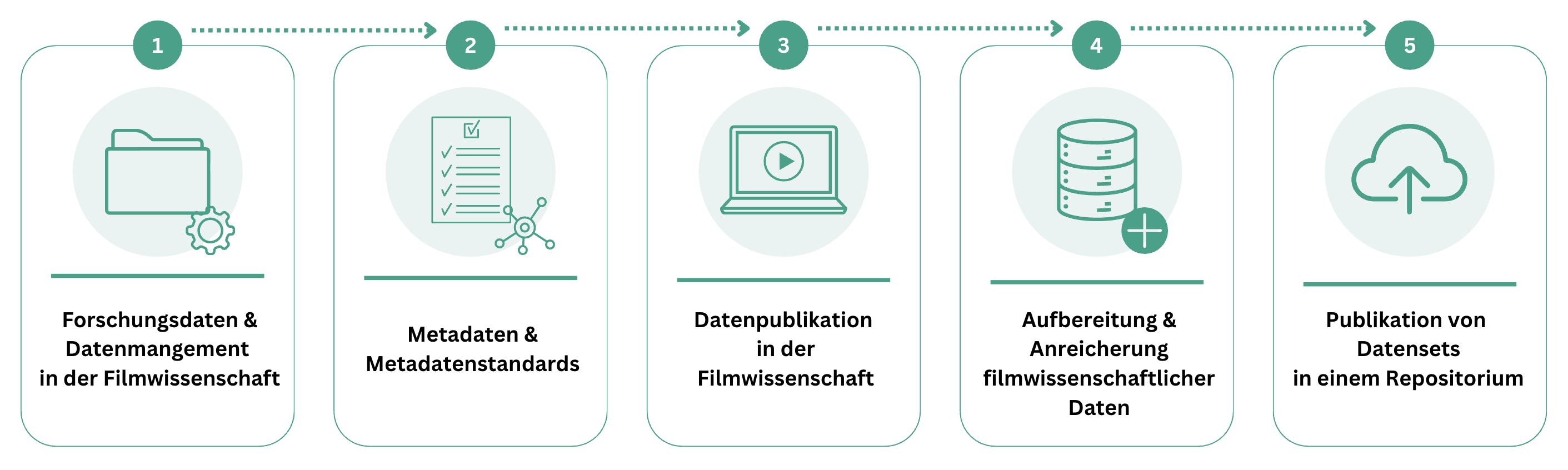
Fig. 2 Übersicht der OER-Lernmodule#
Im ersten Lernmodul geht es um das Thema Forschungsdaten und Forschungsdatenmanagement in der Filmwissenschaft. Das Kapitel führt in praxisorientierte Konzepte des Forschungsdatenmanagements und der Datenorganisation ein.
Das zweite Lernmodul beschäftigt sich mit Metadaten und Metadatenstandards in der Filmwissenschaft. In einem kurzen Exkurs sollen ebenfalls diskriminierungssensible Perspektiven auf Metadaten beleuchtet werden.
Das dritte Lernmodul vermittelt Grundlagen der Datenpublikation mit Schwerpunkt Filmwissenschaft. Es werden Strategien, Perspektiven und Publikationswege beleuchet sowie Beispiele aus der Praxis herangezogen.
Das vierte Lernmodul widmet sich der systematischen Aufbereitung, Bereinigung und Anreicherung der filmwissenschaftlichen Datensätze aus dem SFB-Projekt. Die Daten werden also für die Publikation aufbereitet, formatiert und organisiert.
Im fünften Lernmodul geht es schließlich um die konkrete Publikation der aufbereiteten Forschungsdaten und ihre Implementierung in geeignete Dateninfrastrukturen.
Zugangsweg und Bearbeitungszeit#
Dieses interaktive Lehrbuch wird im 📘 Book Only Mode sowie 💻 Local Mode bereitgestellt. Dies bedeutet, dass es im Browser mit eingeschränkten Interaktionsmöglichkeiten bearbeitet werden kann. Einige Lernmodule erfordern die lokale Installation externer Anwendungen oder das Herunterladen und Verwenden von Dateien. Die hierfür erforderlichen Werkzeuge und Ressourcen werden an den entsprechenden Kapitelabschnitten vorgestellt. Mehr Informationen gibt es unter Technische Voraussetzungen.
Zu Beginn jeder Lerneinheit wird die geschätzte Bearbeitungszeit angegeben. Dies hilft, die Zeit effektiv zu planen und die Lernmodule strukturiert zu bearbeiten. Für das Self-Assessment am Ende jeder Lerneinheit wird die Bearbeitungsdauer separat angegeben und ist nicht in der geschätzten Dauer des Lernmoduls selbst enthalten.