
2.4. Erhebung & Nachnutzung#
Da diese Fallstudie sich auf die Organisation, Aufbereitung und Publikation von Daten entlang des filmwissenschaftlichen SFB-Teilprojekts der FU konzentriert, werden hier lediglich einige gängige Methoden, Beispiele und Hinweise für die Datenerhebung vorgestellt - es besteht kein Anspruch auf Vollständigkeit.
Erhebung von Forschungsdaten#
Je nach technischem Erfahrungsniveau stehen unterschiedliche Methoden und Verfahren zur Verfügung, um Forschungsdaten in der Film- und Medienwissenschaft zu erheben oder zu generieren. Im Folgenden werden gängige Methoden vorgestellt.
Erhebung mit digitalen Annotationstools#
⟶ Niveau: Basis
Für filmanalytische Untersuchungen eignen sich insbesondere digitale Annotationswerkzeuge wie Advene, (zum Beispiel in Verbindung mit dem AdA-Toolkit), ELAN, VIAN oder FrameTrail.
Das Erstellen von Annotationsdaten erfordert i.d.R. nur begrenztes technisches Vorwissen. Die Handhabung kann auf Grundlage verfügbarer Manuals, Open Educational Resources oder Projektdokumentationen schnell erlernt werden. Die jeweiligen Plattformen bieten oftmals ausführliche Dokumentationen und Tutorials an.
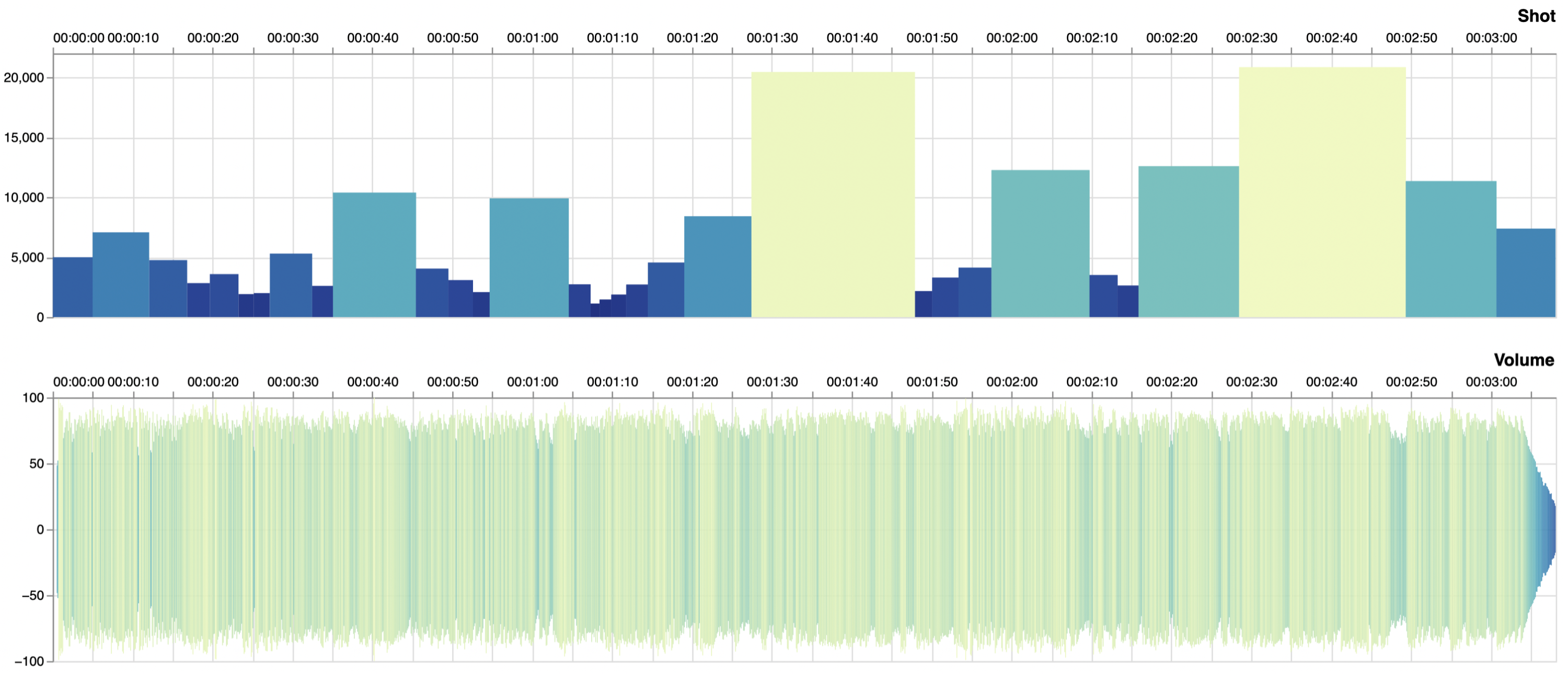
Fig. 2.6 Visualisierung von Annotationsdaten mit der AdA-Timeline#
Annotationen erstellen mit dem AdA-Toolkit
In unserer QUADRIGA Fallstudie: “Affektrhetorik in Online-Videos zur Klimakrise. Datengestützte Analysen audiovisueller Muster” wird gezeigt, wie mit der für die Filmanalyse entwickelten Analyseontologie AdA (Toolkit) in Advene Annotationsdaten erstellt und visualisiert werden können.
Data Dumps, APIs und SPARQL-Abfragen#
⟶ Niveau: Fortgeschritten
Neben eigenen Erhebungen können Forschungsdaten auch über bestehende Datenquellen und Datensammelbanken bzw. Plattformen gewonnen werden.
Hierzu zählen insbesondere:
Was sind Data Dumps?
Data Dumps sind große bereitgestellte Datenmengen, die von einem Computersystem, einer Datei oder einem Gerät auf ein anderes übertragen werden.
Technisch versierte Nutzer:innen können API-Schnittstellen kommerzieller und nicht-kommerzieller Dienste nutzen – z. B. IMDb Non-Commercial Datasets, The Movie Database (TMDb – für nicht-kommerzielle Nutzung) oder die OpenSubtitles REST API.
Was sind API-Schnittstellen?
Eine API (Application Programming Interface) ist eine Programmierschnittstelle zwischen verschiedenen Softwareanwendungen. Sie ermöglicht die automatisierte Kommunikation zwischen Programmen, um Daten oder Funktionen auszutauschen, also eine Form der “Maschine-zu-Maschine”-Kommunikation. Über APIs können Entwickler:innen auf Inhalte, Daten oder Dienste anderer Systeme zugreifen und diese in eigene Anwendungen integrieren.
Ebenso bietet beispielsweise das Portal Wikidata mittes eines SPARQL-Endpoints semantische Abfragen an. Anleitungen und Abfragebeispiele sind in den Dokumentationen der Seite zu finden.
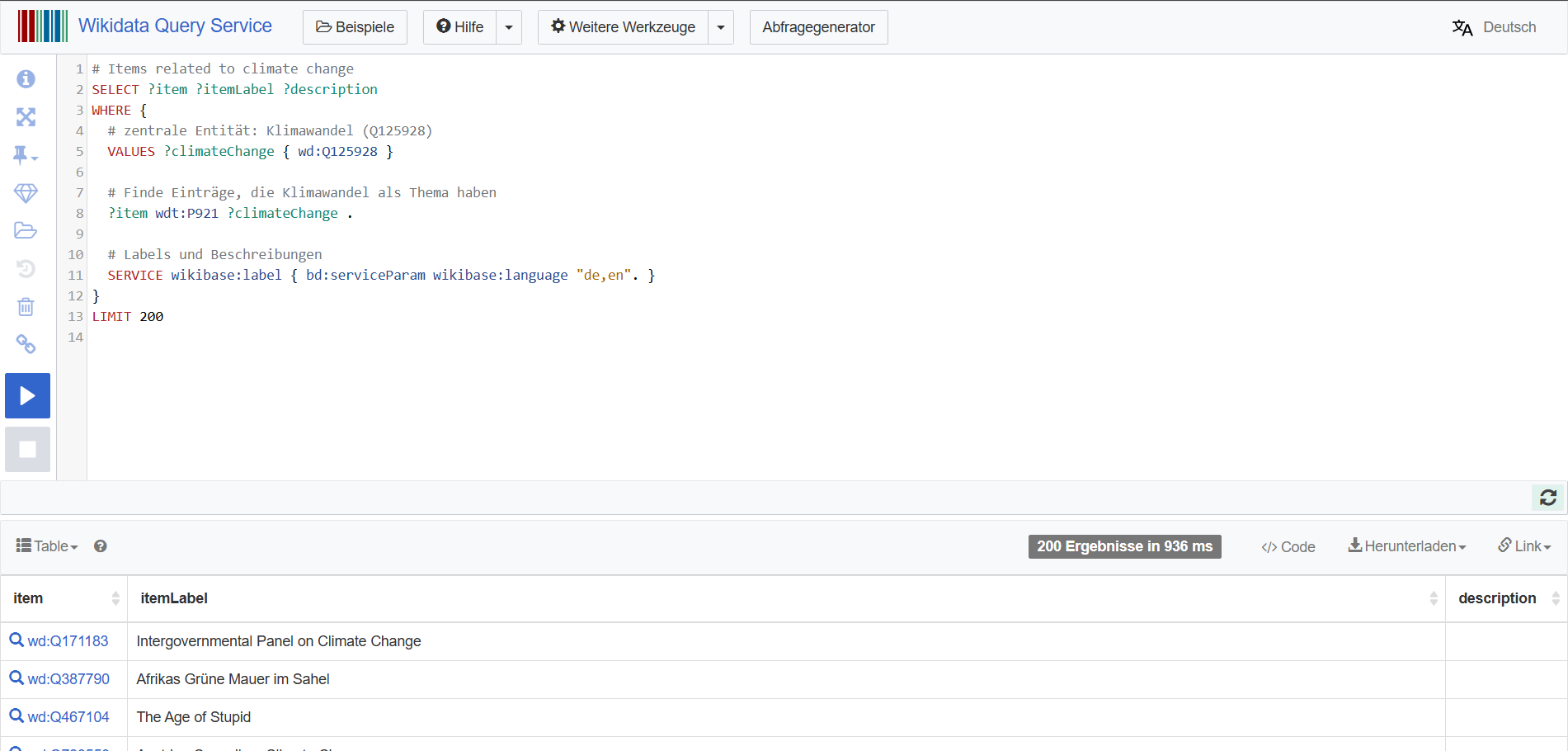
Fig. 2.7 Beispiel einer SPARQL-Abfrage mit dem Schlagwort “climate change”#
Was ist ein SPARQL-Endpoint?
SPARQL ist eine “graphenbasierte Abfragesprache”, durch die Daten aus der webbasierten Beschreibungssprache RDF (Resource Description Framework) abgefragt werden können. Ein SPARQL-Endpoint ist eine URL, über die Benutzer:innen diese Abfragen stellen können. Aus großen Datenmengen, die im RDF-Format vorliegen, können mit SPARQL-Abfragen also gezielt Informationen abgerufen werden.
Erhebung mit Webscrapingverfahren#
⟶ Niveau: Expert:in
Webscraping für fortgeschrittene Nutzer:innen mit Programmierkenntnissen (Python, R, JavaScript)
Webscraping ist ein Verfahren der automatisierten Extraktion von Daten aus Webseiten. Scraper - das sind Codeskripte - analysieren die html-Struktur einer Website und filtern bestimmte vorgegebene Informationen raus, die dann in einer Tabelle (dataframe) strukturiert gespeichert werden können.
Unter Berücksichtigung rechtlicher Vorgaben und der jeweiligen robots.txt kann Webscraping als digitales Verfahren eingesetzt werden, um beispielsweise Filmdaten zu extrahieren, die nicht über Schnittstellen oder offene Data Dumps zugänglich sind.
In jedem Fall sind Lizenzbedingungen, Nutzungsrechte und Datenschutz zu prüfen, insbesondere wenn Daten kommerzieller Anbieter (z. B. IMDb, TMDb) nachgenutzt werden sollen.
Was ist eine “robots.txt”?
Eine robots.txt ist eine einfache Textdatei in dem Hauptverzeichnis einer Website, in der vorgegeben wird, aus welchen Bereichen der Website Daten extrahiert werden dürfen und aus welchen nicht. Dort wird ebenfalls das Verhalten der Datenextraktion selbst festgelegt - insbesondere in welchen zeitlichen Abständen das Scraping erlaubt ist, um den Server nicht zu überlasten.
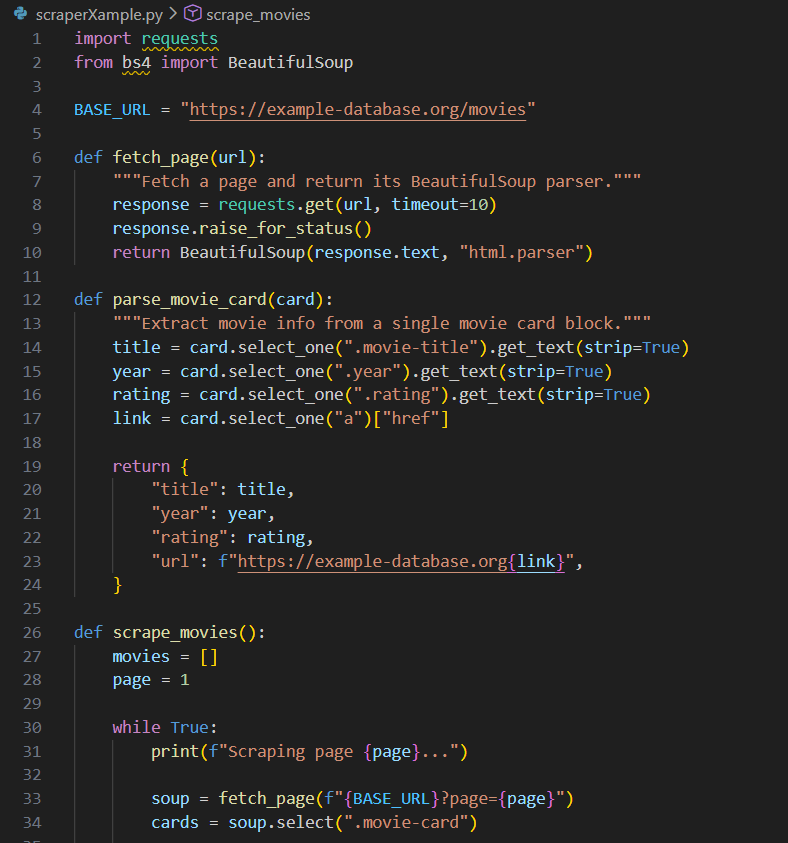
Fig. 2.8 Illustratives Beispiel eines Webscraping-Skripts#
Siehe auch:
Detaillierte Informationen zum Thema Webscraping gibt es in unserer QUADRIGA Fallstudie: “Quantitative Analyse der kommunikativen Barrierearmut des Berliner Senats (2011-2024). Eine Fallstudie”