4.3.2. Vorbereitung und Import des Datensatzes#
Datenformate#
Für die Bereinigung von Datensätzen müssen diese in das Programm importiert werden. OpenRefine und ähnliche Tools ermöglichen den Import verschiedener Datei- und Datenformate für die Datenverarbeitung:
Tabellenformate
CSV/TSV/SV – Textbasierte Tabellen mit Trennzeichen (Komma, Tab, etc.).
Fixed-Width Columns – Spalten mit fester Breite.
Excel (XLS, XLSX) & OpenDocument Spreadsheet (ODS) – Tabellen mit mehreren Blättern und Formatierungen.
Text- und Markup-Formate
TXT – Einfache Textdateien.
XML – Strukturiertes Markup-Format.
Wikitext – Wikipedia-ähnliche Syntax.
Daten- und Metadatenformate
JSON – Kompaktes, strukturiertes Datenformat.
RDF/XML, JSON-LD, N3, N-Triples, Turtle – Linked-Data-Formate.
PC-Axis (PX) – Statistische Daten.
MARC – Bibliothekskataloge.
Cloud- und Web-Datenquellen
Google Sheets – Direktimport aus der Cloud.
Der folgende Text konzentriert sich auf die gängigen Formate TSV, CSV und TXT. Im Kapitel zum Datenmodell wurde bereits kurz auf das Format TSV eingegangen.
Im Grunde handelt es sich bei TSV und CSV ebenfalls um TXT Dateien, also einfache Textdateien, die jede Art von Zeichen und Text enthalten können, einschließlich unstrukturierter oder formatierter Daten. Um Daten zu formatieren, müssen einzelne Einträge, wie etwa die einzelnen Zellen in einer Tabelle, im Text erkennbar voneinander getrennt werden. Zu diesem Zweck haben sich als gängige Trennzeichen (engl. separator oder konkreter delimiter) das Tabulatorzeichen und das Komma durchgesetzt. Aus ihnen erklären sich die Namen der anderen oben genannten Formate: “Tab Separated Values” und “Comma Separated Values”.
Für das Arbeiten mit Datensätzen, die ausschließlich aus Zahlen bestehen, ist das Komma als Trennzeichen vollkommen ausreichend. In den Digital Humanities wird allerdings typischerweise mit Daten gearbeitet, die neben Zahlen auch Texte enthalten, etwa Filmtitel oder Beschreibungen. In einem CSV-Datensatz würde ein Filmtitel wie The Good, the Bad and the Ugly als zwei getrennte Einträge interpretiert werden, nämlich The Good und the Bad and the Ugly, da das Komma als Zeichen für einen neuen Eintrag gelesen würde. Daher ist zu empfehlen, stattdessen bei der Erstellung von Datensätzen ein eindeutiges, in Texten selten auftretendes Zeichen als Trennzeichen einzusetzen - wie etwa das Tabulatorzeichen oder den senkrechten Strich | (engl. Pipe). Unter Windows wird dieser senkrechte Strich mit der Tastenkombination Alt Gr+< erzeugt, auf dem Mac mit option+7.
Für den Übungsdatensatz zu diesem Kapitel der OER haben wir das Tabulatorzeichen verwendet, in einem herkömmlichen Texteditor sieht die Darstellung des Datensatzes folgendermaßen aus:
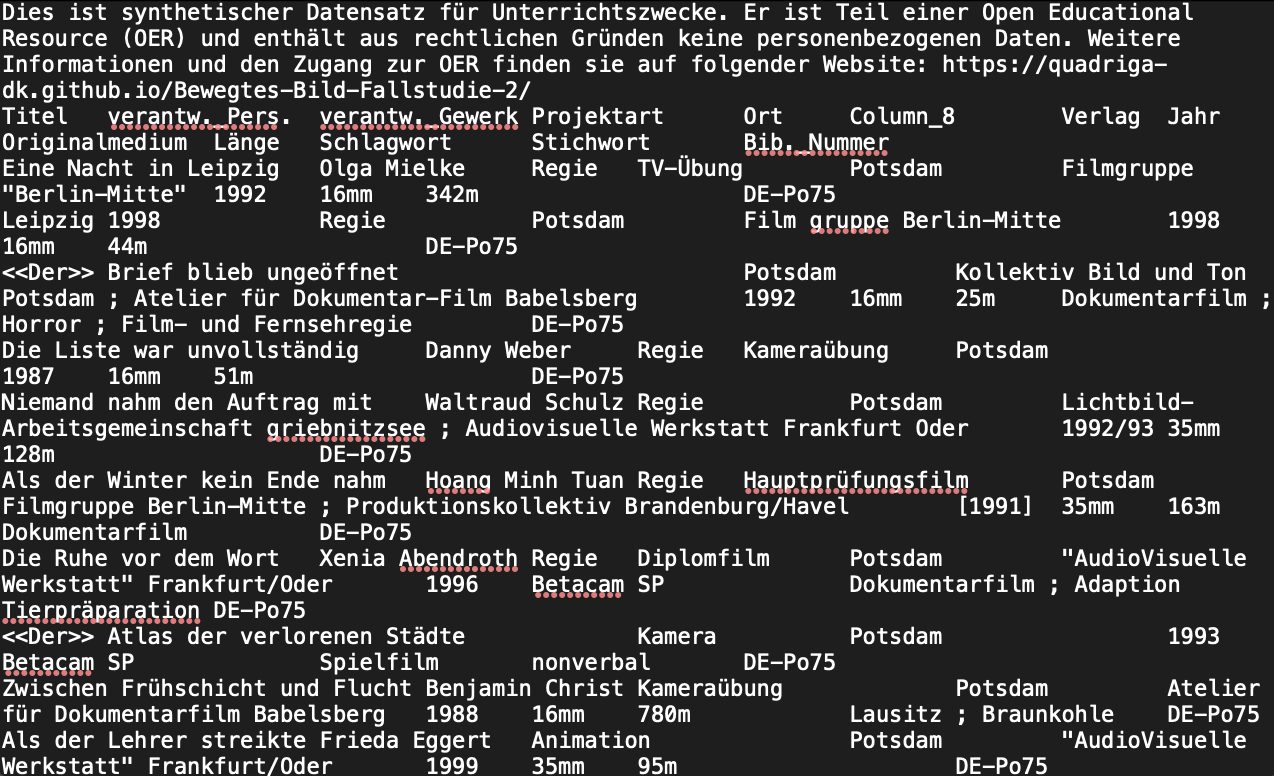
Fig. 4.12 Dataset mit Tabulator-Trennzeichen im Programm TextEdit#
Bei diesem Trennzeichen lassen sich einzelne Einträge bereits gut unterscheiden. Ohne eine grafische Aufbereitung des Datensatzes ist es jedoch schwierig, diese einer konkreten Zeile und Spalte zuzuordnen und Beziehungen zwischen den Einträgen herzustellen. Hier kommt nun OpenRefine ins Spiel.
Import des Datensatzes in OpenRefine#
Die Schritte zur Bereinigung eines Datensatzes werden in diesem Kapitel exemplarisch anhand des Übungsdatensatzes Synthetischer_Datensatz_Uebung_OER.tsv erläutert, der bereits in der Einleitung zur Datenbereinigung vorgestellt wurde. Sie können den Datensatz hier herunterladen (falls der Download nicht per Klick auf den Link starten sollte: rechte Maustaste und Ziel speichern unter auswählen).
Hinweis
OpenRefine wird zwar über Ihren Browser gestartet und bedient, sämtliche importierte und bearbeitete Daten verbleiben jedoch lokal auf Ihrem Rechner und werden nur dort abgespeichert. Ein Upload auf externe Server findet nicht statt.
Über den Startbildschirm von OpenRefine werden durch Anklicken von Create Project neue Projekte erstellt (Fig. 4.13). Neben lokalen Dateien (Choose Files) können über die Importoptionen URLs, Database und Google Data auch Datensätze aus dem Internet importiert werden. In der Clipboard Ansicht ist es möglich, ganze Datensätze per Copy-and-Paste über die Zwischenablage einzulesen.
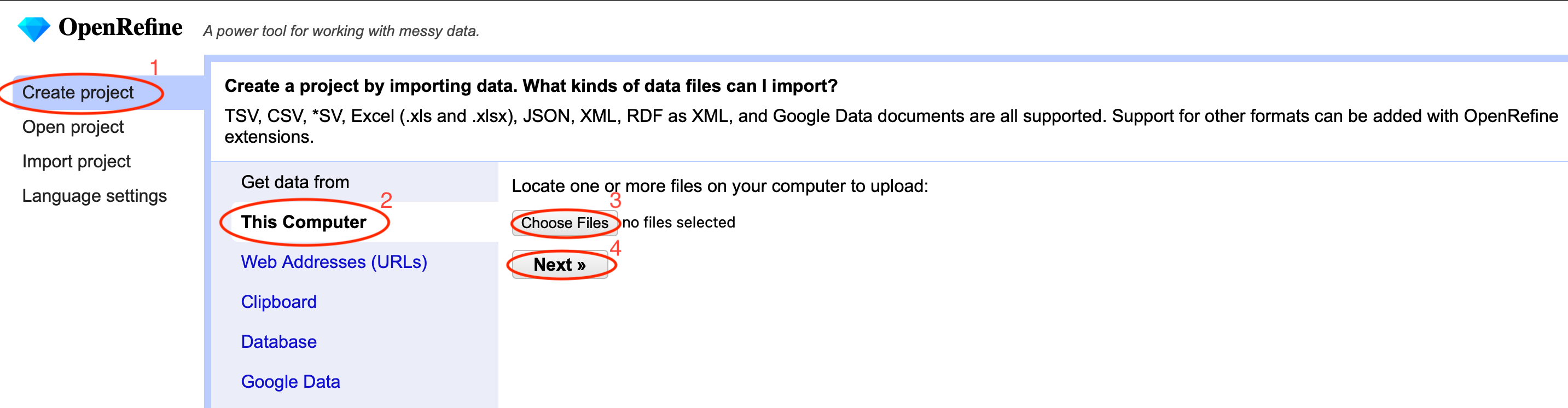
Fig. 4.13 Das Startmenü von OpenRefine#
Wählen Sie nun durch Choose files die Datei Synthetischer_Datensatz_Uebung_OER.tsv aus. Navigieren Sie hierzu zu dem Speicherort, an dem Sie den Download auf Ihrem Computer abgelegt haben. Klicken Sie auf Next. Nach dem erfolgreichen Einlesen des Datensatzes öffnet sich das folgende Menü für die Importoptionen:
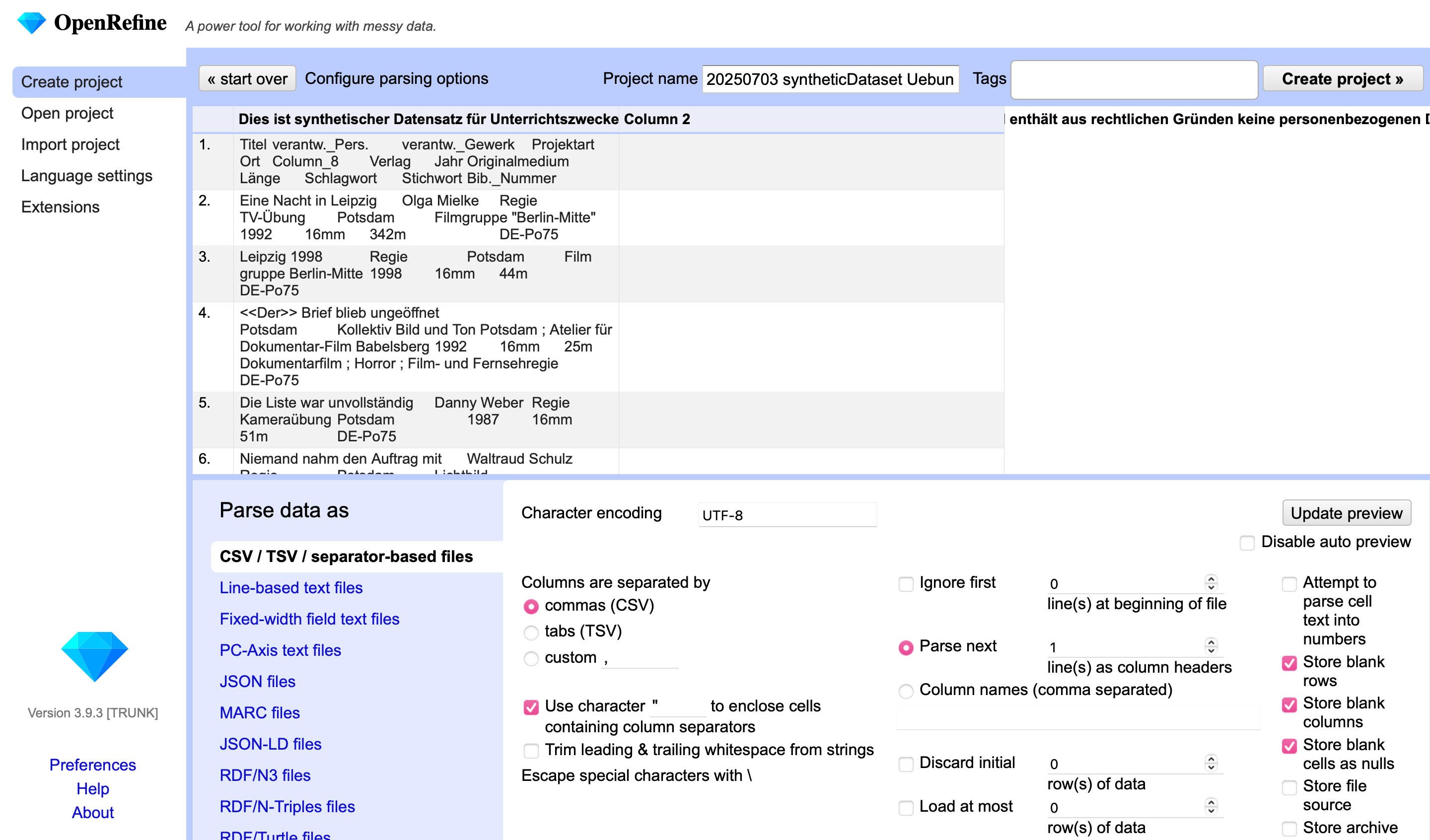
Fig. 4.14 Die Optionen zum Datenimport#
Durch vertikales und horizontales Scrollen können Sie sich hier sämtliche Spalten ansehen. Gehen wir diese Optionen nun Schritt für Schritt durch. Als Erstes ist bei der Vergabe des Projektnamens auffällig, dass hierfür der Namen der Datensatz-Datei verwendet wurde und alle Unterstriche im Dateinamen automatisch durch Leerzeichen ersetzt wurden. Bei der Arbeit mit Daten sollten Leerzeichen generell vermieden werden, da dies zu Problemen beim Einlesen der Datensätze in Bearbeitungs- und Auswertungssoftware führen kann. Daher sollten die Unterstriche anstatt der Leerzeichen wieder eingesetzt werden. Zudem macht es Sinn, den Titel mit zusätzlichen Informationen zu ergänzen, etwa dem Erstellungsdatum, einer Versionsnummer oder einem Personenkürzel. Dies erleichtert später die Unterscheidung verschiedener Fassungen eines OpenRefine Projekts, etwa von gespeicherten Zwischenstufen vor größeren Bearbeitungsschritten. Hier fällt die Wahl auf den Namen 20250609_Datensatz_Uebung_OER_V1.
Im Feld Tags können alternativ durch Leerzeichen getrennte Schlagworte angegeben werden, die gemeinsam mit dem Rest des Projekts im TAR Dateiformat gespeichert und später in der Übersicht der Projekte in Open Project mit angezeigt werden.

Fig. 4.15 Projektname und Schlagworte#
Im großen Vorschaufenster in der Mitte wird ein Ausschnitt des Datensatzes entsprechend der Importeinstellungen ständig aktualisiert. Während des Imports erkennt OpenRefine automatisch das Dateiformat als “CSV / TSV / separator-based files” und nimmt eine Reihe von Einstellungen vor:

Fig. 4.16 Die Importeinstellungen#
Generell ist OpenRefine sehr kompetent in der automatischen Erkennung der korrekten Einstellungen. Hier allerdings hat OpenRefine fälschlicherweise das Komma als Trennzeichen, also CSV, ausgewählt. Wählen Sie stattdessen TSV aus.

Fig. 4.17 Auswahl des Trennzeichens#
Die Spalten sind nun korrekt voneinander getrennt, allerdings enthält die Kopfzeile noch eine Beschreibung des Datensatzes an dessen Anfang:
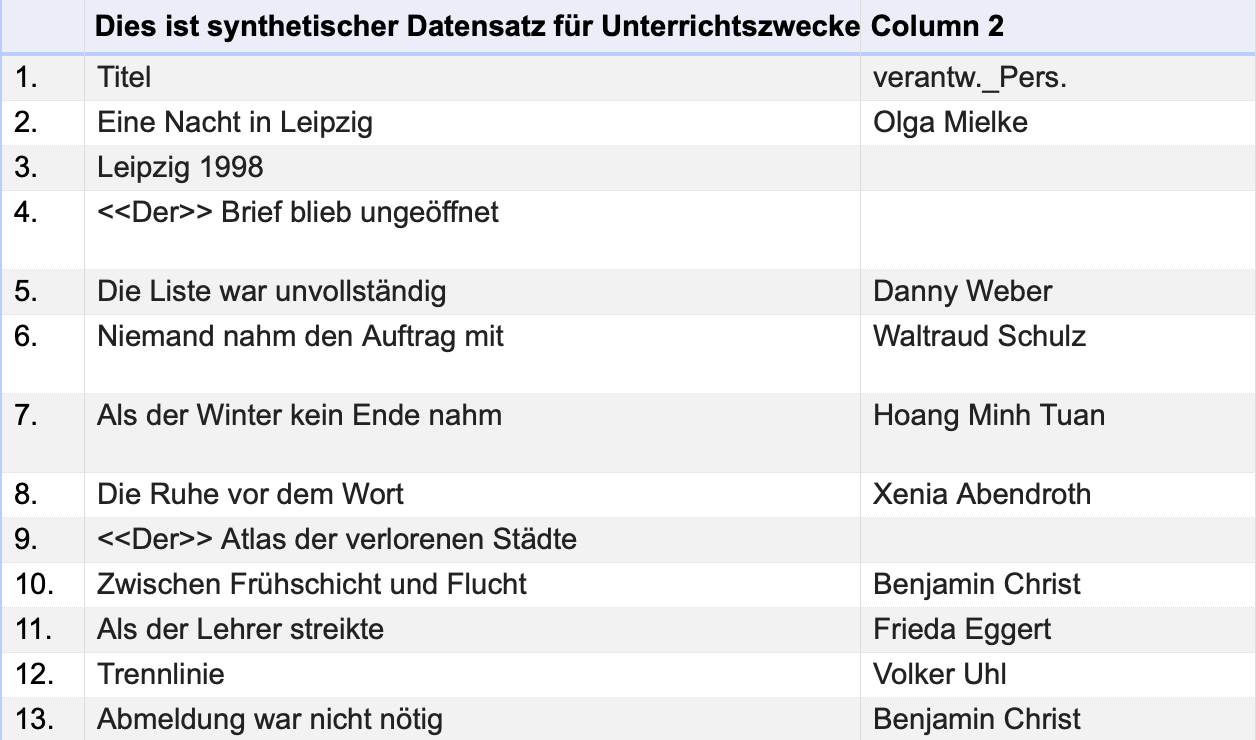
Fig. 4.18 Die Beschreibung des Datensatzes wurde in die Kopfzeile übernommen#
Wählen Sie in den Importeinstellungen Ignore first 1 line(s) at beginning of file aus, um die Beschreibung zu überspringen:

Fig. 4.19 Die Optionen zum Überspringen einer Zeile#
Mit dieser Einstellung sollten nun die korrekten Spaltennamen ausgewählt sein.
Wählen Sie als nächstes die Option Attempt to parse cell text into numbers aus und achten Sie dabei auf die Spalte Jahr.
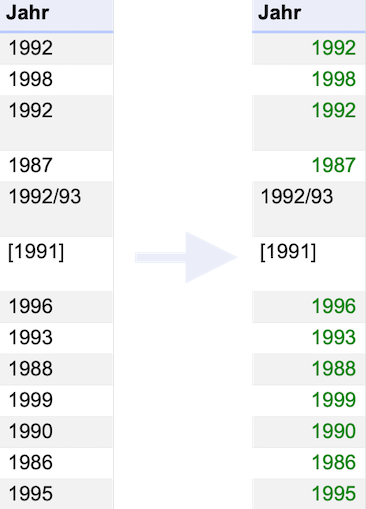
Fig. 4.20 Die Spalte Jahr vor und nach Auswahl der Option Attempt to parse cell text into numbers#
Wie Sie feststellen können, haben sich einige der Jahreszahlen grün gefärbt. Dies bedeutet, dass OpenRefine diese Einträge als einen anderen Datentyp als Text erkannt hat – nämlich als Zahlen, auf die sich etwa mathematische Operationen anwenden lassen. Dazu mehr im nächsten Kapitel Sichtung des Datensatzes.
Eine weitere interessante Option ist Trim leading & trailing whitespace from strings
Escape special characters with \ .
Diese Option entfernt Leerzeichen am Anfang und Ende der Einträge und versieht Sonderzeichen mit einem Backslash.
Der Eintrag Hallo Welt! würde damit zu Hallo Welt\! werden.
Der Backslash signalisiert OpenRefine, dass das Sonderzeichen ! Teil des Eintrags ist und nicht versehentlich als Trennzeichen interpretiert wird, da dieses nun am Ende des Eintrags steht.
Wählen Sie diese Option ebenfalls aus.
Die übrigen Einstellungen können für den Import des Übungsdatensatzes so übernommen werden. Ggf. hat OpenRefine bei Ihnen zu Beginn andere Importoptionen ausgewählt – für diese OER werden diese Optionen verwendet:

Fig. 4.21 Die vollständigen Importoptionen#
Der Import wird mit einem Klick auf “Create project” in der oberen rechten Ecke der Eingabeoberfläche abgeschlossen.
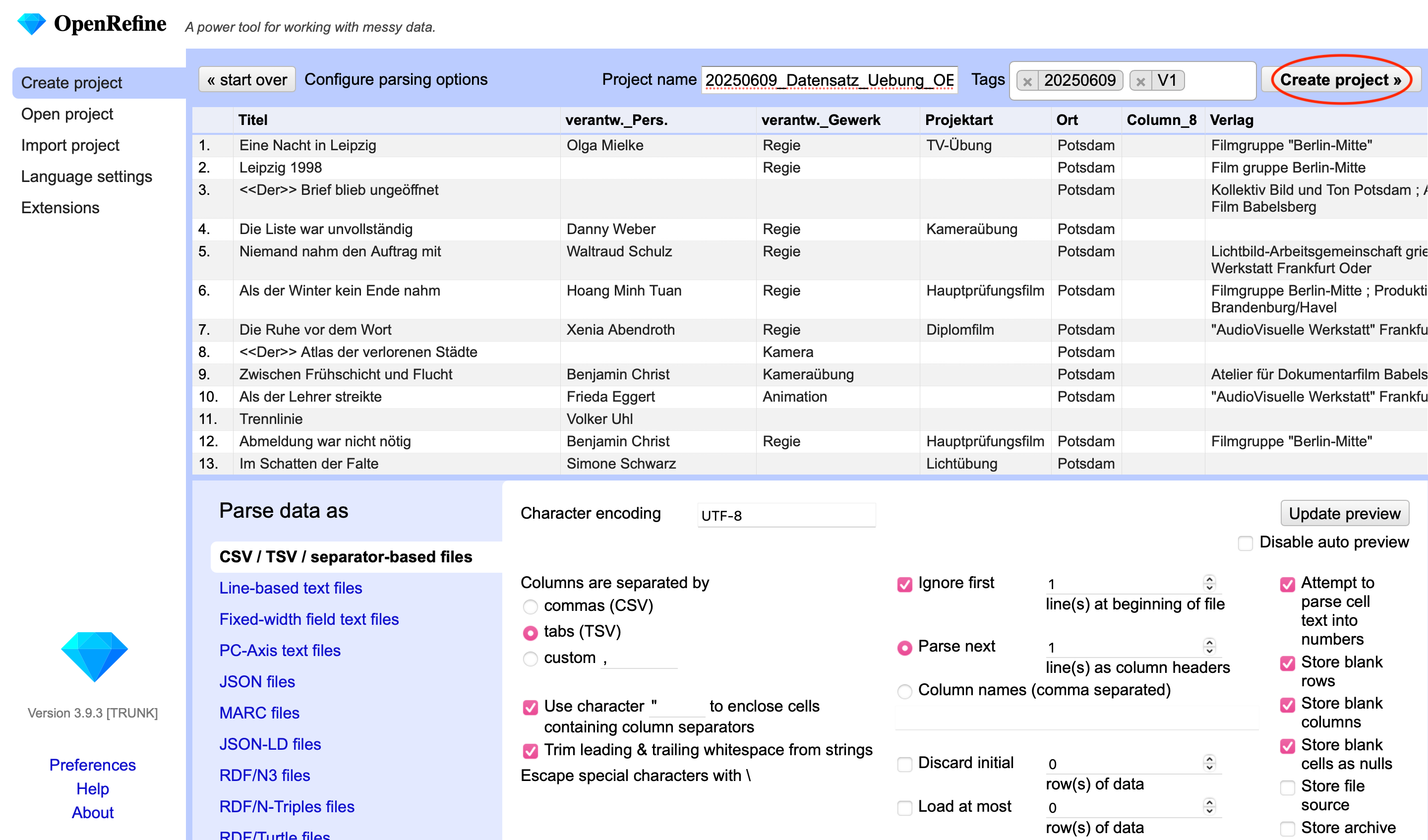
Fig. 4.22 Create Project#
Es öffnet sich das Hauptfenster von OpenRefine, in dem Sie während der Bereinigung eines Datensatzes die meiste Zeit verbringen werden. Falls Sie direkt mit dem Übungsdatensatz weiterarbeiten möchten, können Sie die folgenden Ausführungen überspringen und mit dem Abschnitt zur Sichtung des Datensatzes fortfahren. Es lohnt sich dennoch, die einzelnen Einstellungsmöglichkeiten kurz zu erläutern, da sie für das Einlesen komplexer strukturierter Datensätze nützlich sein können.
Die Importeinstellungen im Überblick#
Character encoding
Hier kann die Zeichenkodierung des Datensatzes ausgewählt werden. In den meisten Fällen sollte der Webstandard UTF-8 zutreffen.
Columns are separated by
Hier kann das Trennzeichen des Datensatzes ausgewählt werden. Neben dem Komma (CSV) und dem Tabulatorzeichen (TSV) ist es möglich, im Feld custom eigene Trennzeichen anzugeben – hier können alternative Trennzeichen wie | ausgewählt werden.
Use character “ to enclose cells containing column separators
Manchmal werden Einträge, die das generelle Trennzeichen des Datensatzes enthalten, durch Anführungszeichen gekennzeichnet, um so eine versehentliche Aufteilung des Eintrags zu vermeiden. Diese Einstellung funktioniert etwas missverständlich: Wird sie ausgewählt, werden die Anführungszeichen als Kennzeichen interpretiert, den entsprechenden Eintrag nicht aufzuteilen und nicht mehr angezeigt, andernfalls bleiben sie erhalten und die Einträge werden getrennt.
Optionen zu den Zeilen
Die Optionen zu den Zeilen auf der rechten Seite legen fest, welche Zeilen importiert und wie sie interpretiert werden sollen.
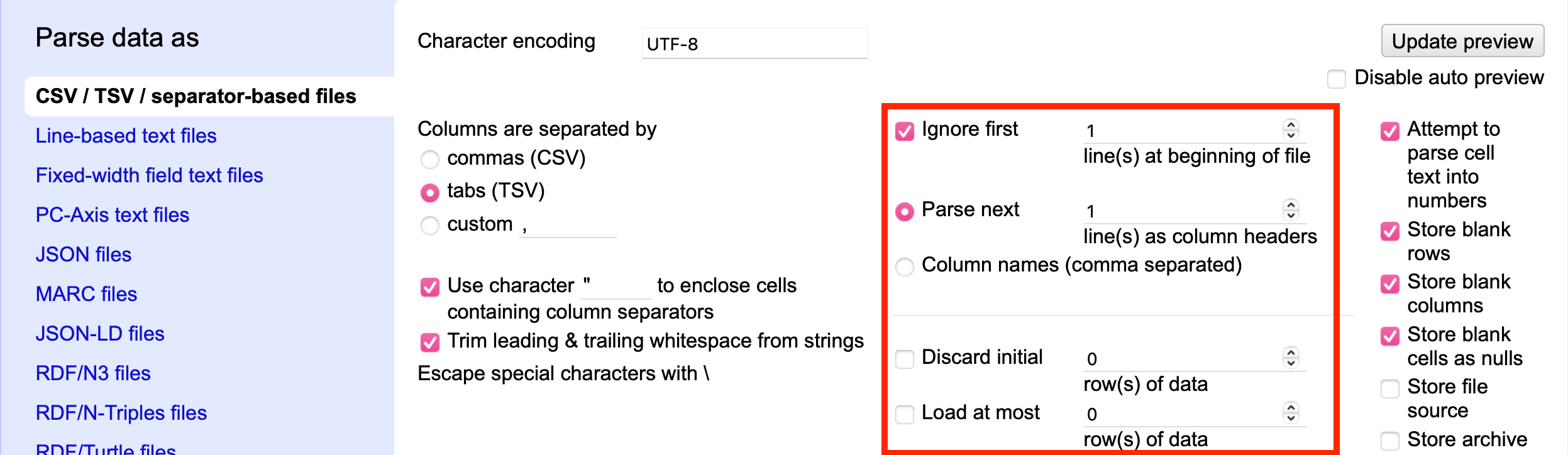
Fig. 4.23 Die Importeinstellungen für Zeilen#
Manche Textdateien enthalten vor dem eigentlichen Datensatz Kommentare oder andere Informationen, die nicht als Teil des Datensatzes importiert werden sollten – dafür ist die bereits verwendete Option Ignore first x line(s) at beginning of file zuständig.
Generell sollte die erste Zeile eines Datensatzes die Namen der Spalten enthalten; die entsprechende Zeile wird mittels Parse next x line(s) as column headers ausgewählt.
Als Alternative können auch direkt eigene durch Komma getrennte Spaltennamen im Textfeld der Option Column names (comma separated) angegeben werden.
Die letzten beiden Optionen Discard initial (0) row(s) of data und Load at most (0) row(s) of data können genutzt werden, um nach den der Zeile mit den Spaltennamen eine Anzahl an Zeilen zu überspringen oder nur eine maximale Anzahl an Zeilen zu importieren.
Store blank rows/columns
Diese Option führt zum Import von leeren Zeilen oder Spalten. Manche Dateien nutzen leere Zeilen und Spalten zur Strukturierung, etwa um zwei Datensätze in der selben Datei voneinander zu trennen. Da der Datensatz keine leeren Zeilen und Spalten enthält, macht diese Option für dieses Beispiel keinen Unterschied.
Store blank cells as nulls
Bei blank cells handelt es sich um leere Text- oder Zahlen-Einträge. Null ist ein eigener Datentyp der anzeigt, dass eine Zelle keinen Eintrag enthält. Wo genau liegt nun der Unterschied? In vielen Situationen müssen alle Text- oder Zahlen-Einträge auf einmal bearbeitet werden, etwa um Nachkommastellen hinzuzufügen. In solchen Fällen sollten leere Einträge i.d.R. übersprungen werden, weshalb der Import von leeren Einträgen als Nulls in den meisten Fällen sinnvoll ist – so auch hier.
Store file source & Store archive file Diese Optionen dienen der Archivierung des originalen unbereinigten Datensatzes innerhalb des OpenRefine Projekts. Die erste Option Store file source speichert den Ursprung des Datensatzes, etwa die URL. Die Option Store archive file speichert den ursprünglichen Datensatz selbst als Archivdatei. Sie können beide Optionen in diesem Fall deaktivieren.