Standardisierung der Jahresangaben#
Datensätze wie der Katalog zum Filmarchiv der Filmuniversität sind häufig das Produkt einer jahrzehntelangen Arbeit unterschiedlicher Personen. Darauf wurde bereits im Kapitel zur Datenquelle eingegangen. Es ist daher wenig verwunderlich, dass die Einträge nicht immer einer vollständig kohärenten Systematik folgen. Eine solche ist jedoch für die digitale Auswertung unabdingbar und das Kernziel der Bereinigung eines Datensatzes.
Die Spalte Jahr ist ein gutes Beispiel für das Fehlen eines Systems innerhalb der Einträge:
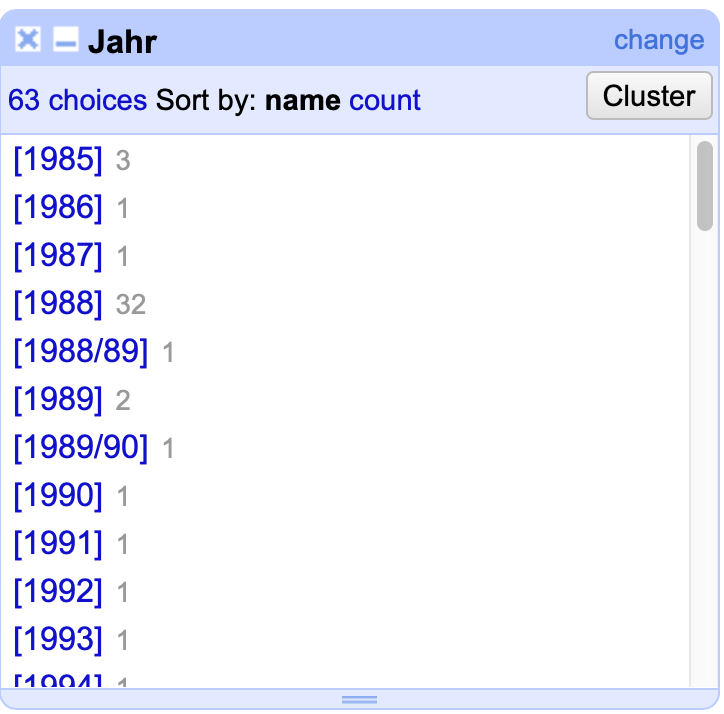
Fig. 4.54 Das Text Facet der Spalte Jahr#
In dieser Spalte sind manche der Jahreszahlen in eckige Klammern eingefasst, andere nicht. Andere wiederum enthalten den Zusatz “ca.” und wurden demnach geschätzt. Besonders bei der Angabe von mehreren Jahren gibt es Unterschiede - sowohl Semikolons als auch Schräg- und Bindestriche finden Verwendung. Die Spalte aufzuteilen, wie im Kapitel zur Bereinigung der Spalten beschrieben, ist damit nicht möglich.
Im Folgenden werden Methoden zur Bereinigung der Einträge eines Datensatzes vorgestellt, die zunächst manueller und dann zunehmend automatischer Natur sind. Falls Sie alle Methoden selbst nachvollziehen möchten macht es ggf. Sinn, von der Undo/Redo Funktion Gebrauch zu machen, um zu einem früheren Stand des Projekts zurückzukehren.
Edit#
Die einfachste Art, Einträge zu bearbeiten ist die Edit Funktion innerhalb des Text Facets.
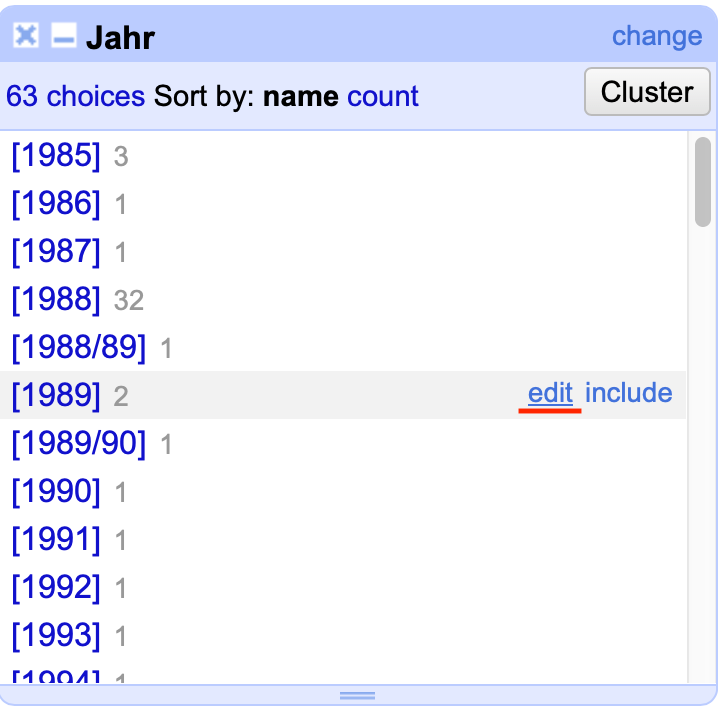
Fig. 4.55 Der Edit-Button innerhalb des Text Facets#
Da im Text Facet identische Einträge zusammengefasst werden, können bei diesem Beispiel - [1989] - die eckigen Klammern bei zwei Einträgen auf einmal bearbeitet werden. Allerdings müssten für jedes weitere Jahr die eckigen Klammern einzeln händisch entfernt werden. Eine solche Vorgehensweise ist nicht nur aufwendig, sondern auch sehr fehleranfällig. Damit lässt sich die Edit Funktion vor allem für Probleme einsetzen, die nur einmalig innerhalb des Datensatzes auftreten und für die sich die folgenden Methoden nicht lohnen bzw. zu aufwändig sind.
Cluster#
Eine Möglichkeit, Einträge effektiver zu bearbeiten, ist deren Zusammenfassung in Cluster. Öffnen Sie das Cluster - Menü über das Text Facet Fenster im linken Teil der Arbeitsoberfläche.
Fig. 4.56 Der Button zum Öffnen des Cluster-Menüs#
Mittels eines Clustering-Algorithmus erkennt OpenRefine passende Eintrags-Gruppen und schlägt für diese in der Spalte New cell value einen Wert vor.
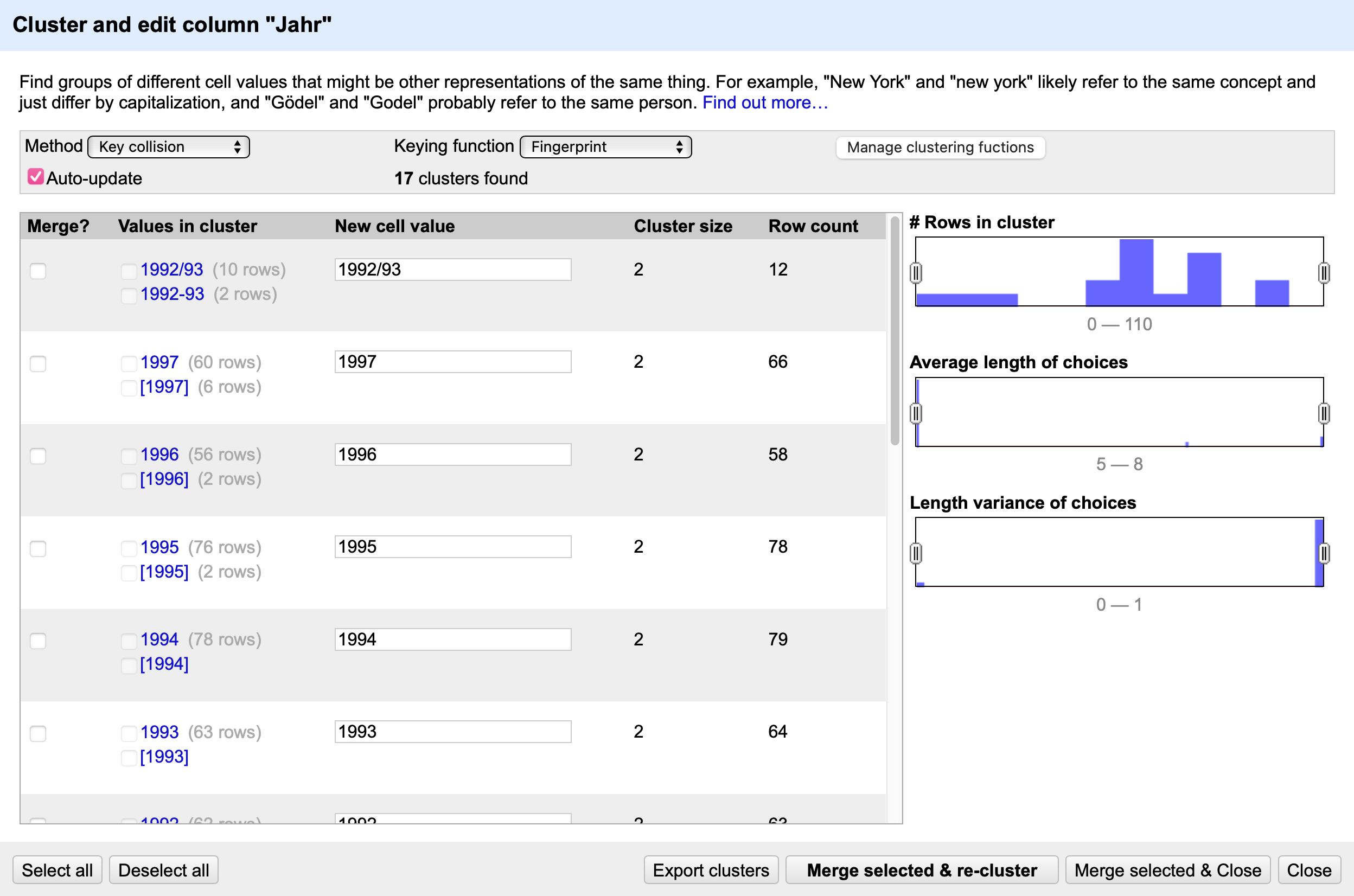
Fig. 4.57 Das Cluster-Menü#
Über die Dropdown-Menüs Method und Keying function kann der Clustering-Algorithmus geändert werden. Grundsätzlich ist es völlig ausreichend, die unterschiedlichen Algorithmen einfach auszuprobieren, ohne deren Funktionsweise im Detail zu verstehen. Falls Sie sich jedoch näher für die Algorithmen interessieren, finden sich weitere Informationen in der OpenRefine Dokumentation.
Sobald Sie einen passenden Algorithmus gefunden haben, können Sie die Einträge, die Sie ändern wollen, in der Spalte Merge? auswählen und im Textfeld New Cell Value den neuen Eintrag festlegen.
In der Spalte Jahr ist das Cluster-Menü besonders für die jene Einträge geeignet, die mehrfache Jahreszahlen enthalten, etwa 1992/93 und 1992-93. Wählen Sie für den neuen Eintrag eine Schreibweise, durch die sich die Einträge leicht in mehrere Spalten aufteilen lassen, etwa 1992 ; 1993.

Fig. 4.58 Auswahl eines Cluster#
Nachdem Sie Ihre Änderungen ausgewählt haben, klicken sie auf den Button Merge selected & re-cluster, um von OpenRefine die Einträge entsprechend anpassen und neue Cluster erstellen zu lassen. Sie können nun mit einem neuen Algorithmus versuchen, weitere Cluster dieser Art zu finden – Sie werden allerdings vermutlich ausschließlich Cluster finden, die mehrere unterschiedliche Jahreszahlen enthalten.
Durch die Anwendung der Cluster hat sich in der Spalte Jahr eine Mischung aus mehreren Datentypen ergeben – die bearbeiteten Einträge wurden zu text umgewandelt, während die unbearbeiteten Einträge ohne Sonderzeichen als number weiterhin grün hinterlegt sind:
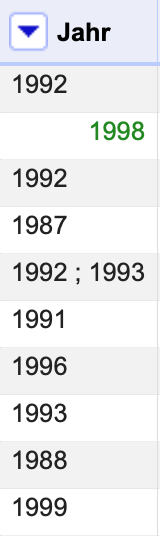
Fig. 4.59 Unterschiedliche Datentypen in der Spalte Jahr#
Bei den weiteren Bereinigungsschritten kann dies zu Problemen und Inkonsistenzen führen. Wandeln Sie daher die komplette Spalte zunächst in text um:
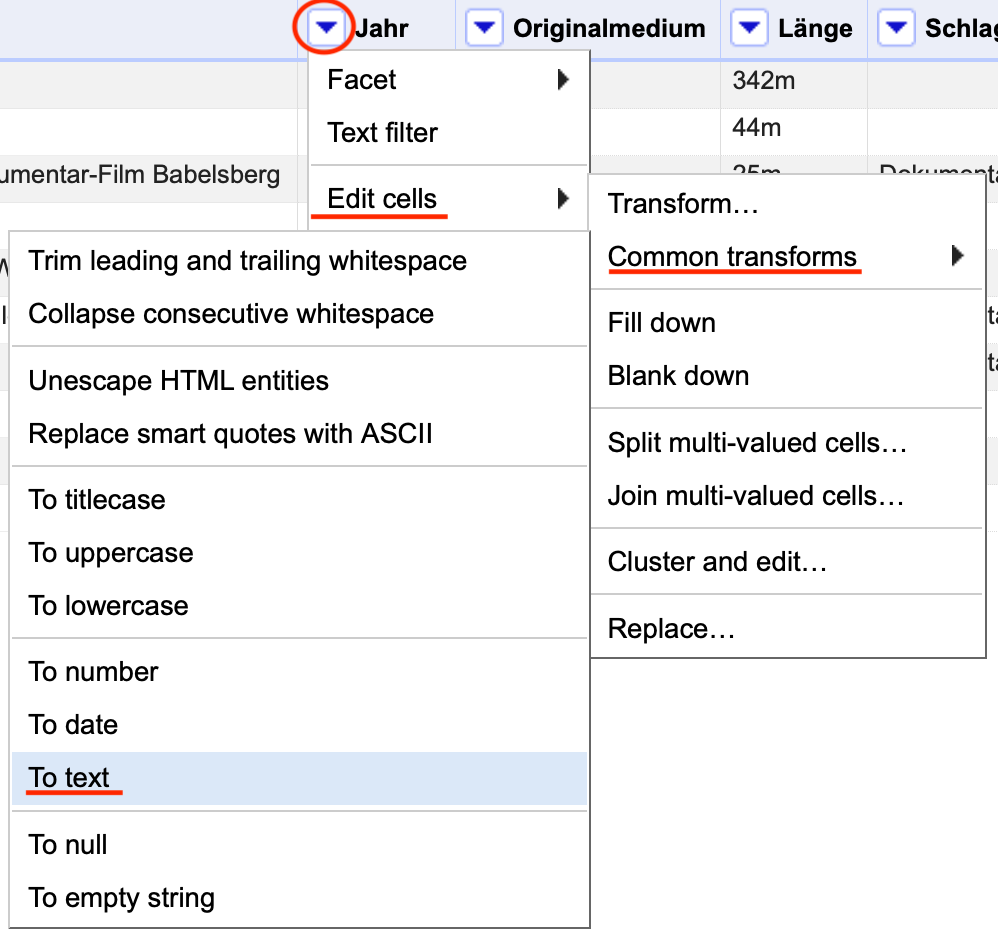
Fig. 4.60 Die Umwandlung des Datentyps number zum Datentyp text#
Mit der Cluster-Funktion konnten noch nicht alle Einträge in der Spalte Jahr bereinigt werden. Es finden sich noch Angaben, die z.B. Schrägstriche oder den Vermerk “ca.” enthalten. Auf die weitere Bereinigung dieser Einträge gehen wir nach der folgenden Übung zur Cluster-Funktion genauer ein.
Übung
In den Verlagsspalten finden sich unterschiedliche Schreibweisen der selben Unternehmen. Vereinheitlichen Sie diese mittels der Cluster-Funktion.
Lösung
Wenden Sie die Funktion Text Facet auf die Verlag-Spalten an, indem sie im Dropdown-Menü der Spalte Verlag_1 im Reiter Facet auf Text Facet klicken. Auf der linken Seite der OpenRefine Arbeitsfläche erscheint das Ergebnis der Text Facet Funktion. Klicken Sie dort auf den Button Cluster (siehe Fig. 4.56).
Es öffnet sich das Fenster zur Cluster Funktion. Im Dropdown-Menü Key function ist bereits der Algorithmus Fingerprint ausgewählt. Starten Sie die Cluster-Bildung durch einen Klick auf den Button Cluster in der Mitte des Fensters.
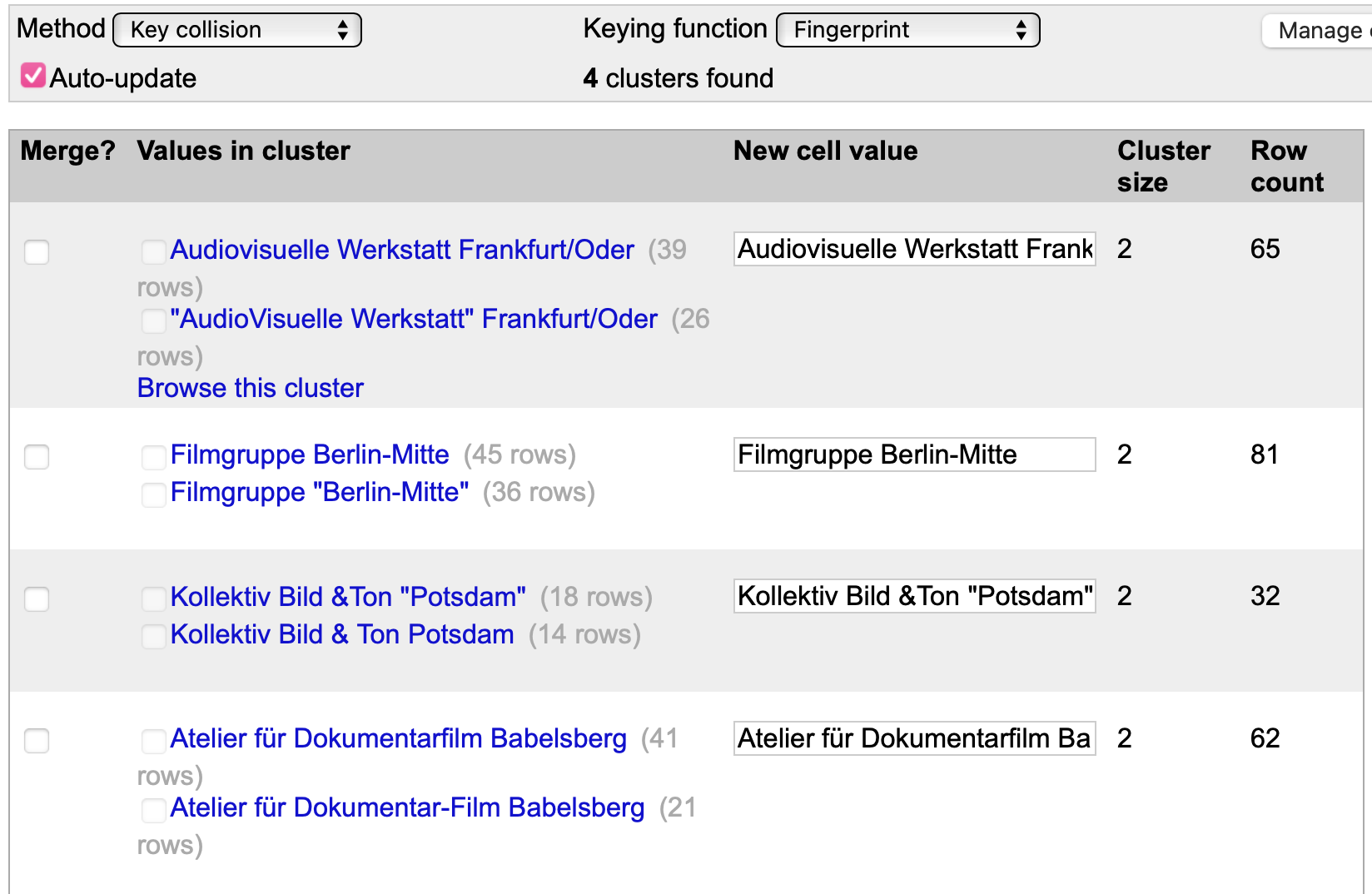
Fig. 4.61 Die Ergebnisse mittels des Fingerprint-Algorithmus#
Prüfen Sie das Ergebnis des Clustering für jeden Eintrag und korrigieren Sie ggf. die New cell value.
Setzen Sie jeweils einen Haken in den Auswahlfeldern Merge? und klicken Sie auf den Button Merge selected & re-cluster (siehe Fig. 4.57).
Wählen Sie einen neuen Algorithmus aus und fahren Sie mit dem Umbenennen der Einträge fort.
Wiederholen Sie im Anschluss die selben Schritte für die Spalte Verlag_2. Achten Sie dabei darauf, die gleichen Schreibweisen zu verwenden wie in der vorherigen Spalte. Vergleichen Sie die Ergebnisse mittels eines Text Facets für beide Spalten.
Zurück zur Bereinigung der Jahresangaben: Durch die Kombination eines Text Facets mit einem Text Filter (siehe Kapitel Sichtung) ist es möglich, alle Einträge in der Spalte Jahr anzeigen zu lassen, die einen Schrägstrich enthalten.
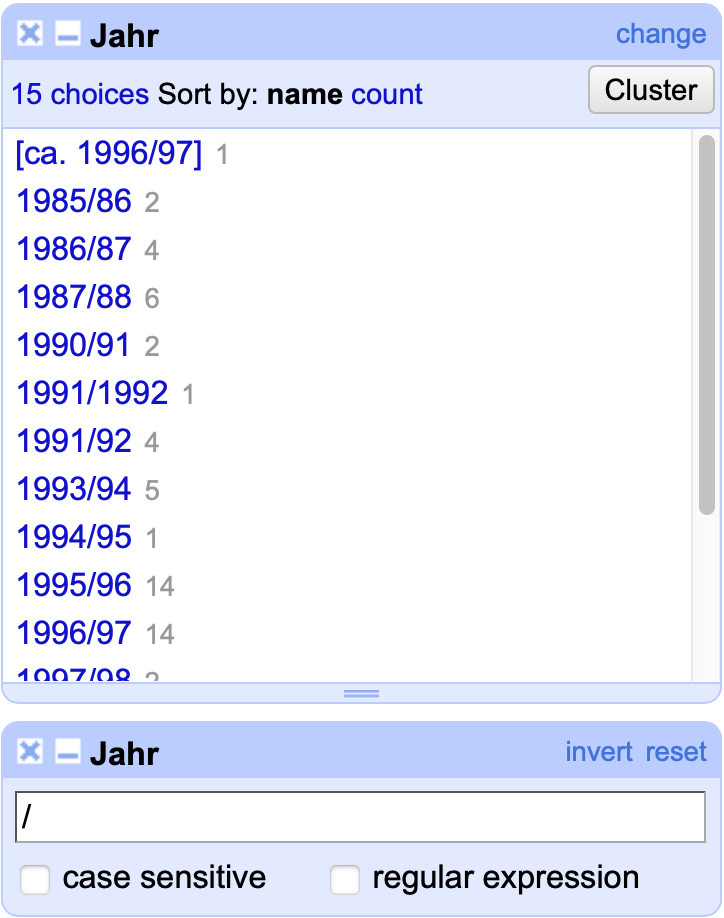
Fig. 4.62 Die Einträge mit einem Schrägstrich innerhalb der Spalte Jahr#
Diese Einträge konnten leider mit der Cluster Funktion nicht erfasst werden, da für sie kein ähnlichen Eintrag vorhanden ist, mit dem sie als sinnvolles Cluster zusammengefasst werden könnten.
GREL#
Die Anzahl an Einträgen mit Schrägstrichen ist überschaubar und ließe sich auch händisch bearbeiten. Stellen Sie sich jedoch einen Datensatz vor, der die hundertfache Anzahl der Filme dieses Datensatzes enthält. Generell sollten während der Bereinigung so wenige händische Änderungen vorgenommen werden wie möglich, um menschliche Fehler zu vermeiden. Das primäre Werkzeug zur automatischen Bereinigung in OpenRefine ist GREL, die General Refine Expression Language.
GREL ist eine an Javascript angelehnte Programmiersprache, die eigens für OpenRefine und die Bereinigung von Datensätzen entwickelt wurde. GREL ist auch für Personen ohne vorherige Programmierkenntnisse leicht verständlich und anwendbar, da keine eigene Programmierumgebung eingerichtet werden muss und GREL-Code typischerweise nur wenige Zeilen umfasst.
Öffnen Sie das Dropdown-Menü einer Spalte, den Reiter Edit cells und Transform…, um das das Menü zur Transformation von Zellen mittels GREL anzuzeigen.
Fig. 4.63 Öffnen des Transform-Menüs#
Das sich nun öffnende Menü ist sehr einfach aufgebaut und Sie müssen neben dem GREL-Code keine Änderungen vornehmen. Den Code geben Sie im Expression Textfeld ein, dessen Größe Sie in der rechten unteren Ecke des Textfelds verändern können. Achten Sie darauf, den Code möglichst genau in der hier dargestellten Schreibweise einzugeben. Abweichungen wie z.B. fehlende Klammern oder Anführungszeichen können zu Fehlermeldungen führen und der Code kann nicht ausgeführt werden.
Fig. 4.64 Das Transform-Menü#
In der Preview-Anzeige darunter wird die aktuelle Auswahl des Datensatzes angezeigt. Die Änderungen, die durch den GREL-Code stattfinden würden, werden dort automatisch in einer Vorschau aktualisiert, noch bevor Sie diesen final durchführen.
Kombination von Filtern und Code
Im obigen Screenshot können Sie erkennen, dass weiterhin nur Einträge mit einem Schrägstrich angezeigt werden – das Text Facet und der Text Filter sind also weiterhin aktiviert und alle Transformationen werden nur auf diese Auswahl des Datensatzes angewendet.
Achtung
Achten Sie darauf, nach abgeschlossener Bearbeitung gegebenenfalls den gesetzten Text Filter wieder zu entfernen. Ansonsten wird eventuell lediglich eine leere Tabelle angezeigt, da der Text oder der Wert, nach dem gefiltert wurde, nach der Bearbeitung im Datensatz nicht mehr enthalten ist.
Nun zu den Grundlagen von GREL. Im Expression Textfeld steht bereits das Wort value, welches die einzelnen Einträge repräsentiert. Der Code wird auf jeden einzelnen Eintrag in der Spalte identisch angewendet. Zwischen den Einträgen und den Spalten untereinander werden keine Verbindungen hergestellt – es sei denn, dass ein solches Verhalten explizit programmiert wird.
Die replace Methode#
Die values können mittels Methoden verändert werden. Eine solche Methode ist etwa replace, mittels derer ein Teil des Eintrags durch einen neuen Text ersetzt werden kann. value und eine Methode wie replace werden mit einem Punkt . miteinander verbunden; die Syntax lautet value.replace(). Innerhalb der Klammern einer Methode werden deren Argumente angegeben, sozusagen deren Optionen. replace enthält zwei Argumente: Den zu verändernden Text und den neuen Text. Texte werden in Abgrenzung zu Zahlen durch Anführungszeichen gekennzeichnet, zum Beispiel als "Text". Die Argumente werden mittels Kommata voneinander getrennt. Die vollständige Syntax lautet also value.replace("zu ändernder Text", "neuer Text").
Code Blocks
Der folgende Text enthält einige Code-Beispiele zur Veranschaulichung des Vorgehens und der GREL-Elemente. Wenn Sie möchten, können Sie jedes der Beispiele auch in ihrem eigenen Projekt ausprobieren. Selbst anwenden müssen sie allerdings nur den vollständigen Code, der in einem Code Block außerhalb des Fließtextes angezeigt wird. Ein Code Block sieht folgendermaßen aus:
Code Block
Wenn sie mit dem Mauszeiger auf den Codeblock zeigen, erscheint in der rechten oberen Ecke die Anzeige Copy to clipboard. Mit einem Klick auf diese Anzeige können Sie den Code in die Zwischenablage kopieren und in ihr OpenRefine-Projekt einfügen.
In obigen Beispiel sollen die Schrägstriche zwischen den Jahren durch ein anderes Sonderzeichen wie ein Semikolon mit Leerzeichen ersetzt werden. Der dafür zu verwendende Code lautet value.replace("/", " ; ").
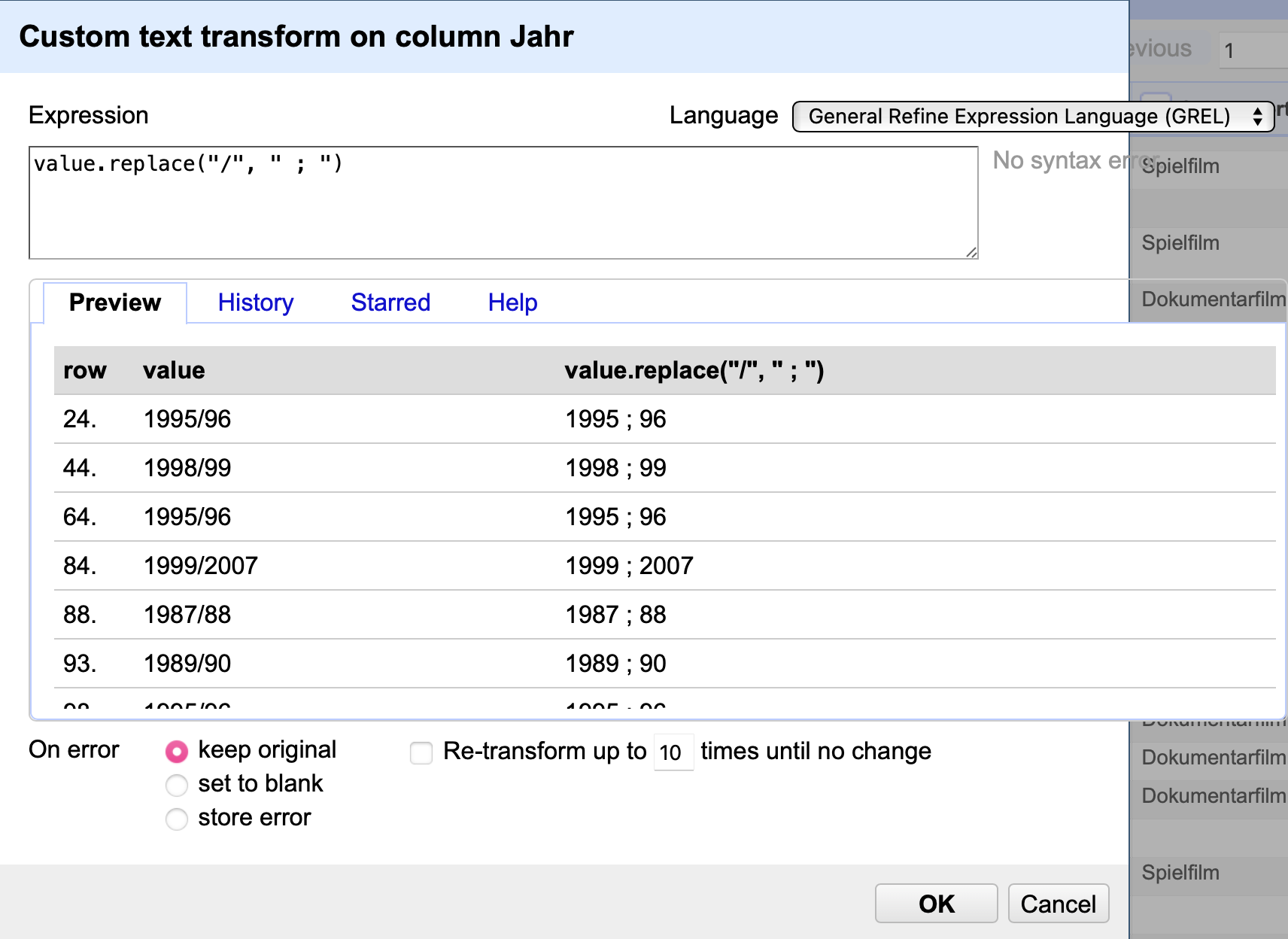
Fig. 4.65 Anwendung des Codes value.replace("/", " ; ")#
Im Preview-Fenster ist zu sehen, wie die Einträge verändert und die Schrägstriche ersetzt werden. Allerdings zeigt sich ein Problem: Bei vielen der Einträge wurde die Jahrhundert-Angabe des zweiten Jahres abgekürzt, nach dem Schema 1995/96. Wird der Code auf solche Einträge angewendet, fehlt z.B. die 19 vor der 96. Insgesamt gibt es vier Kategorien, in die sich die Eintragungen einordnen lassen:
Zwei Jahre aus den 90ern, vollständig ausgeschrieben: 1997/1998.
Zwei Jahre aus den 90ern und 2000ern, vollständig ausgeschrieben: 1999/2007.
Zwei Jahre aus den 90ern, abgekürzt: 1997/98.
Zwei Jahre mit mindestens einem Jahr aus den 80ern, abgekürzt: 1985/86.
Um dieses Problem zu lösen, müssen für jede dieser Kategorien passende Argumente der replace-Methode gefunden werden.
Eine Möglichkeit ist es, neben dem Schrägstrich auch einen Teil des Jahres zu ersetzen und anschließend den fehlenden Teil des Jahres hinzuzufügen. Widmen wir uns den Kategorien in absteigender Reihenfolge ist der Anfang des Codes value.replace("/8", " ; 198").
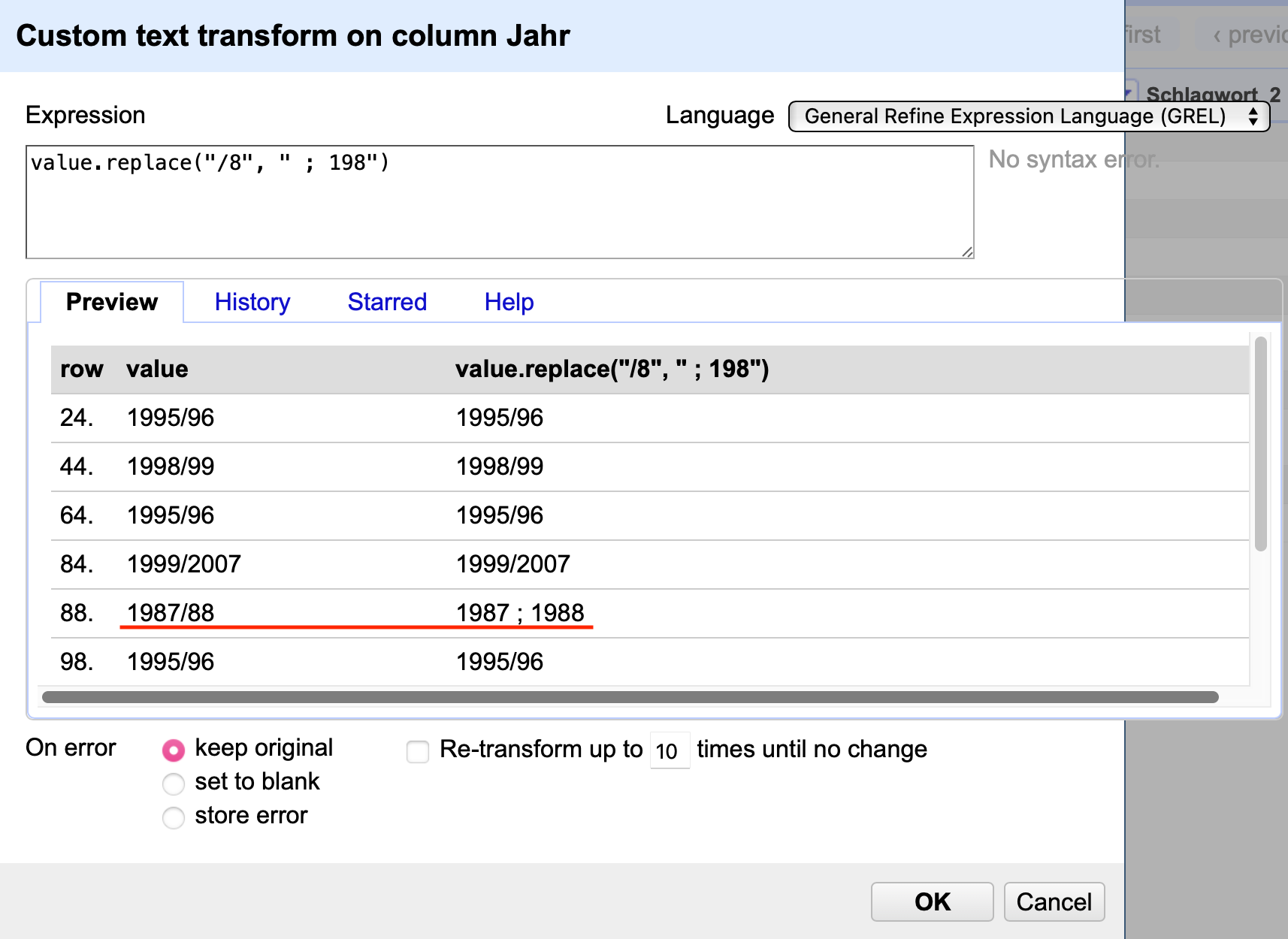
Fig. 4.66 Anwendung des Codes value.replace("/8", " ; 198")#
Da nur Einträge der Kategorie vier die Zeichenfolge /8 enthalten, wurden auch nur diese bearbeitet, etwa der oben rot unterstrichene Eintrag. Auf dieselbe Weise kann für die Kategorie 3 verfahren werden und glücklicherweise lassen sich mehrere Methoden einfach hintereinander reihen, die nacheinander ausgeführt werden:
value.replace("/8", " ; 198").replace("/9", " ; 199").
Die übrigen Kategorien 1 & 2 können nun mit den Code-Schnipsel vom Anfang bereinigt werden, da das Problem der abgekürzten Jahreszahlen bereits gelöst ist. Der vollständige Code lautet
value.replace("/8", " ; 198")
.replace("/9", " ; 199")
.replace("/", " ; ")
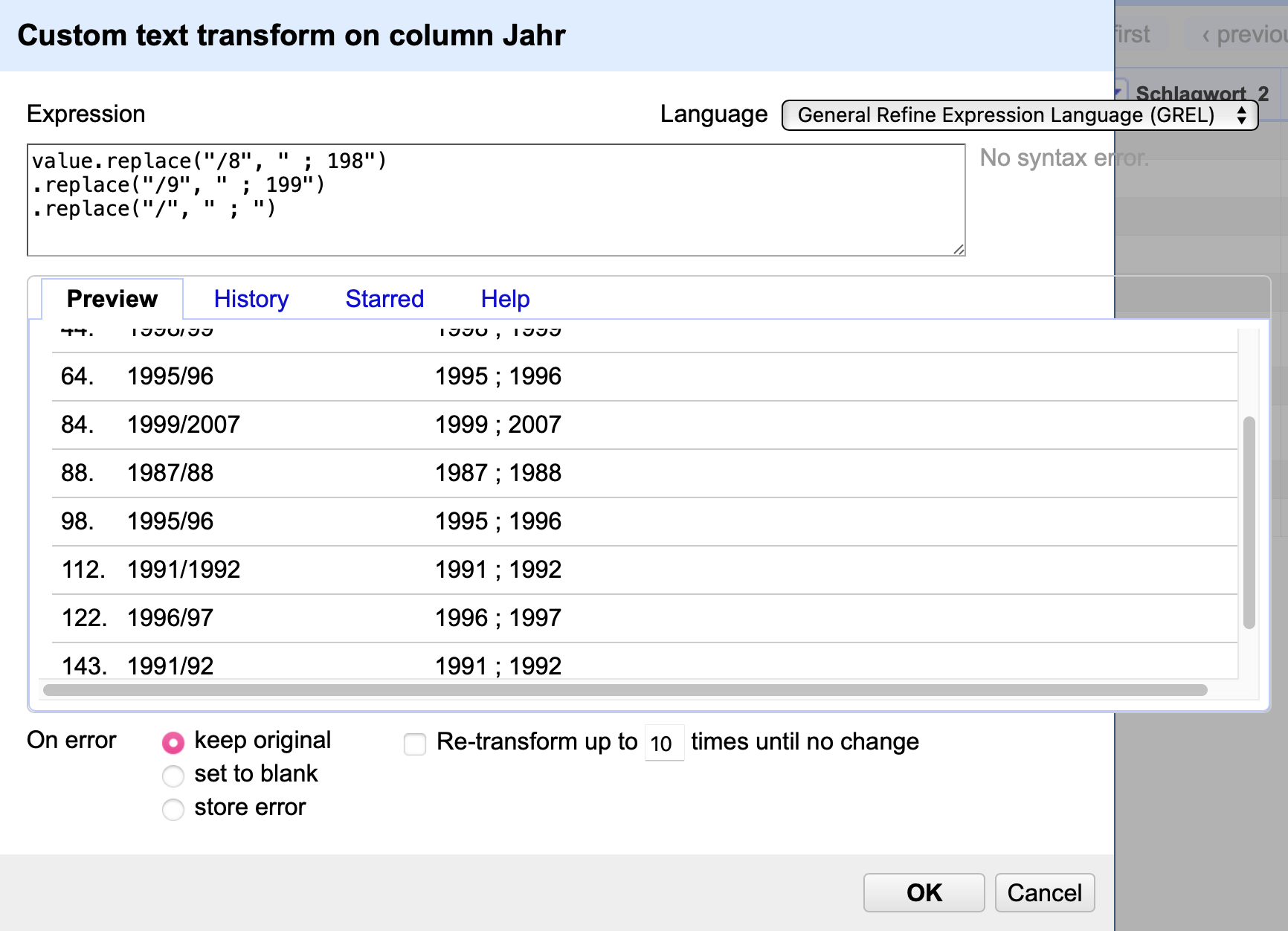
Fig. 4.67 Anwendung des Codes value.replace("/8", " ; 198").replace("/9", " ; 199").replace("/", " ; ")#
Damit sind alle Schrägstriche erfolgreich ersetzt!
Achtung
Entfernen Sie ggf. den zuvor eingestellten Text Filter, um wieder alle Einträge sehen zu können.
Hinweis
Falls Sie die Ausführungen zur Bereinigung der Jahreszahlen weiter selbst am Datensatz nachvollziehen möchten, müssen Sie die folgenden Übungen absolvieren. Die in den Übungen durchgeführten Bereinigungsschritte sind Teil des weiteren Bereinigungsprozesses.
Übung
Die Spalte Jahr enthält noch Einträge mit Bindestrich, z.B. 1993-1995. Adaptieren Sie den vorherigen Code, um auch die Bindestriche durch ein Semikolon und Leerzeichen ; zu ersetzen. Nutzen Sie dabei ein Text Facet und einen Text Filter, um sich sich die relevanten Einträge anzeigen zu lassen.
Lösung
Wählen Sie im Dropdown-Menu der Spalte Jahr im Reiter Facet die Funktion Text Facet aus. Anschließend klicken Sie in Dropdown-Menu der Spalte Jahr auf Text Filter und geben im auf der linken Seite des OpenRefine Arbeitsbereiches erscheinenden Eingabefeld - ein. Nun sind alle Jahresangaben, in denen Bindestriche enthalten sind, ausgewählt. (vgl. Fig. 4.62).
Öffnen Sie nun das Dropdown-Menü der Spalte Jahr und wählen im Reiter Edit cells die Funkion Transform… aus (vgl. Fig. 4.63). In dem sich öffnenden Fenster geben Sie im Feld Expression den GREL-Code ein, der den Bindestrich durch ein Semikolon mit vorangestellten und folgenden Leerzeichen ersetzt.
Der korrekte Code lautet
value.replace("-9", " ; 199")
.replace("-", " ; ")
Im Fenster unter dem Eingabefeld wird eine Vorschau auf die Anwendung des Codes angezeigt (vgl. Fig. 4.64). Führen Sie den GREL-Code durch einen Klick auf OK aus. - wurde durch ; ersetzt!
Übung
Entfernen Sie die eckigen Klammern, die einige der Einträge in der Spalte Jahr einrahmen.
Lösung
Wählen Sie im Dropdown-Menu der Spalte Jahr im Reiter Facet die Funktion Text Facet aus. Anschließend klicken Sie in Dropdown-Menu der Spalte Jahr auf Text Filter und geben im auf der linken Seite des OpenRefine Arbeitsbereiches erscheinenden Eingabefeld [ ein. Nun sind alle Jahresangaben ausgewählt, die von eckigen Klammern eingerahmt werden (vgl Fig. 4.62).
Öffnen Sie das Dropdown-Menü der Spalte Jahr und wählen im Reiter Edit cells die Funkion Transform… aus (vgl. Fig. 4.63). In dem sich öffnenden Fenster geben Sie im Feld Expression den GREL-Code ein, der die eckigen Klammern löscht.
Mittels eines leeren Textes als zweites Argument können Teile eines Eintrags entfernt werden, ohne sie durch einen anderen Text zu ersetzen. Der korrekte Code lautet
value.replace("[", "").replace("]", "")
Im Fenster unter dem Eingabefeld wird eine Vorschau auf die Anwendung des Codes angezeigt (vgl. Fig. 4.64). Führen Sie den GREL-Code durch einen Klick auf OK aus. Die eckigen Klammern wurden gelöscht!
Die contains Methode#
Die Spalte Jahr ist beinahe vollständig bereinigt. Ein Problem verhindert jedoch weiterhin, die Einträge in Jahr auf mehrere Spalten aufzuteilen und numerisch auszuwerten: Die ca. Angaben einiger Einträge.
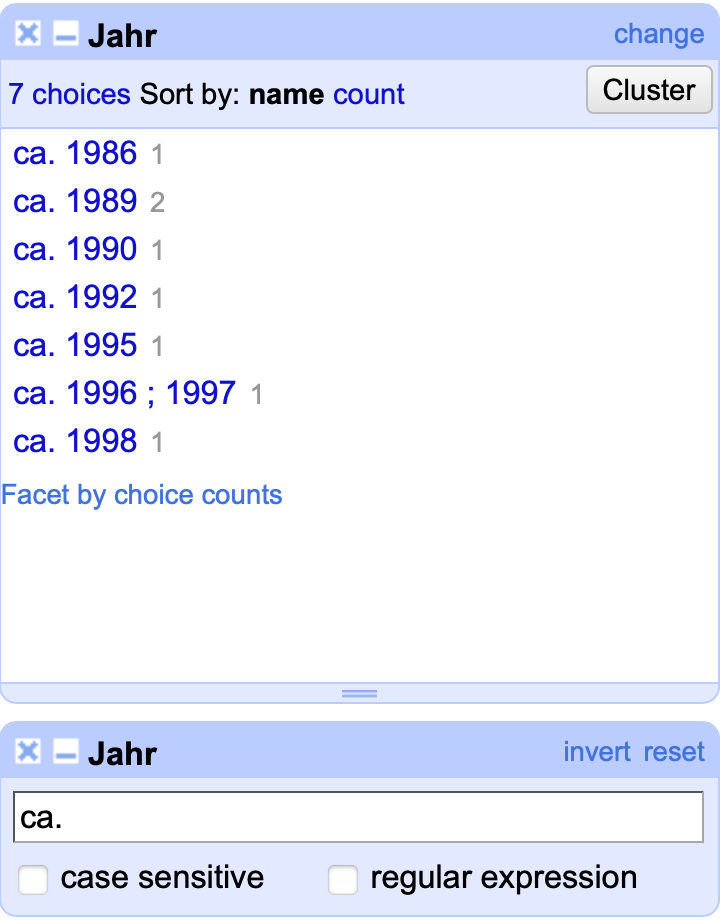
Fig. 4.68 Die Einträge mit einem ca. innerhalb der Spalte Jahr#
Achtung
Entfernen Sie diesen Filter wieder, bevor Sie den folgenden Code anwenden.
Wie können diese Einträge in Zahlen umgewandelt werden, ohne die ca. Angabe einfach zu entfernen? Die Lösung liegt im Anlegen einer neuen Spalte, in die die ca. Angabe übertragen wird.
Eine interessante Methode für dieses Ziel ist contains.
contains gibt darüber Auskunft, ob ein Eintrag das Argument der Methode enthält oder nicht. Wird der Code value.contains("Hallo") auf den Eintrag “Hallo Welt” angewendet, ist das Ergebnis true, bei dem Eintrag “Welt” hingegen false. true und false sind dabei nicht einfache Texte, sondern Boolean Werte. Boolean, benannt nach George Boole, ist der grundlegende Datentyp in der Programmierung – ein Wert kann entweder wahr oder falsch sein, true oder false.
Wird value.contains("ca.") im Transform-Menü angewandt, werden alle Einträge durch true oder false ersetzt.
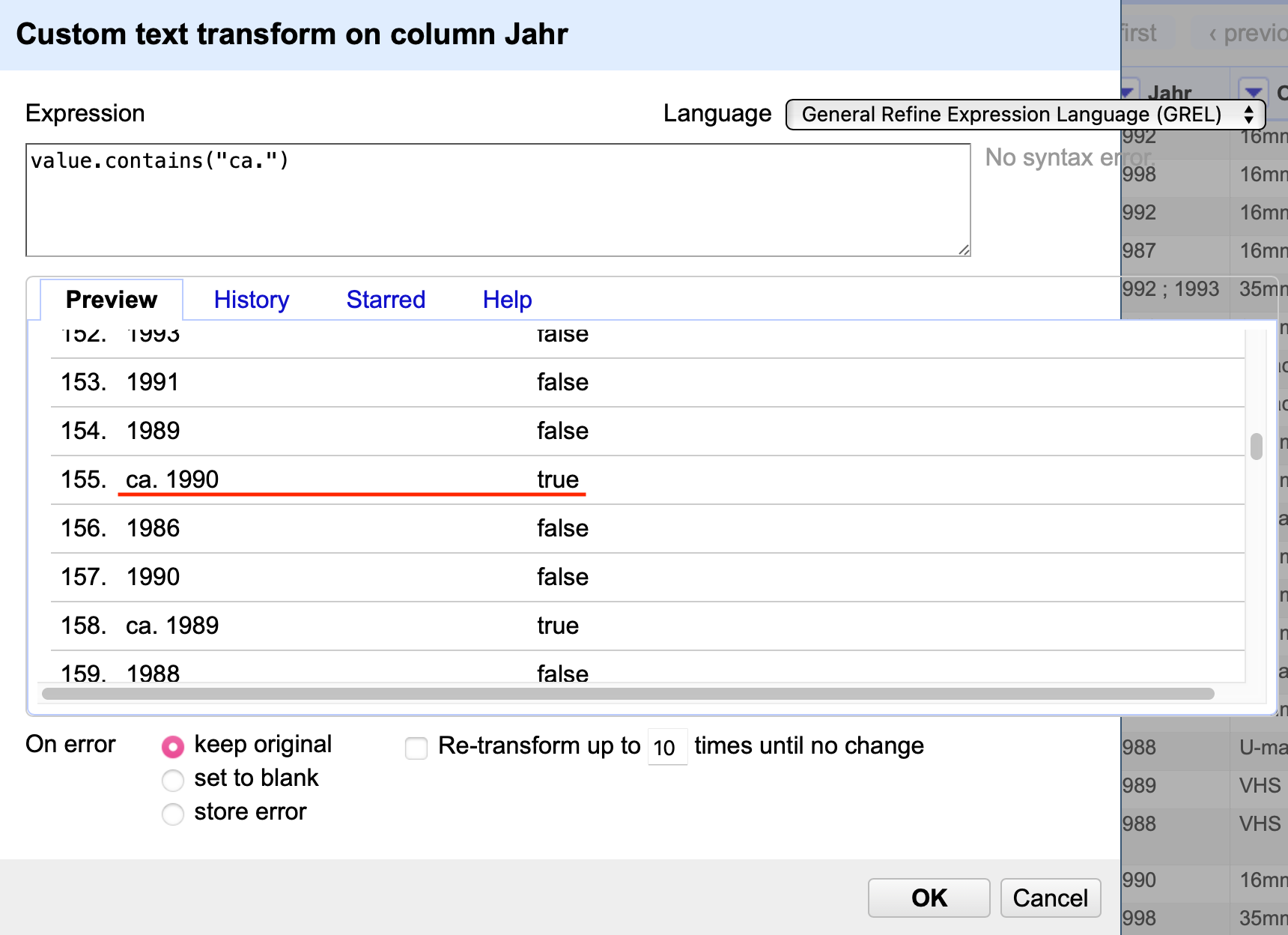
Fig. 4.69 Anwendung des Codes value.contains("ca.")#
Das ist natürlich nicht das erwünschte Ergebnis. Stattdessen soll eine neue Spalte auf der Grundlage der Spalte Jahr erstellt werden, die dann wie Werte true oder false enthält. Die passende Funktion findet sich im Dropdown-Menü der entsprechenden Spalte: Im Reiter Edit columns klicken Sie auf Add column based on this column….
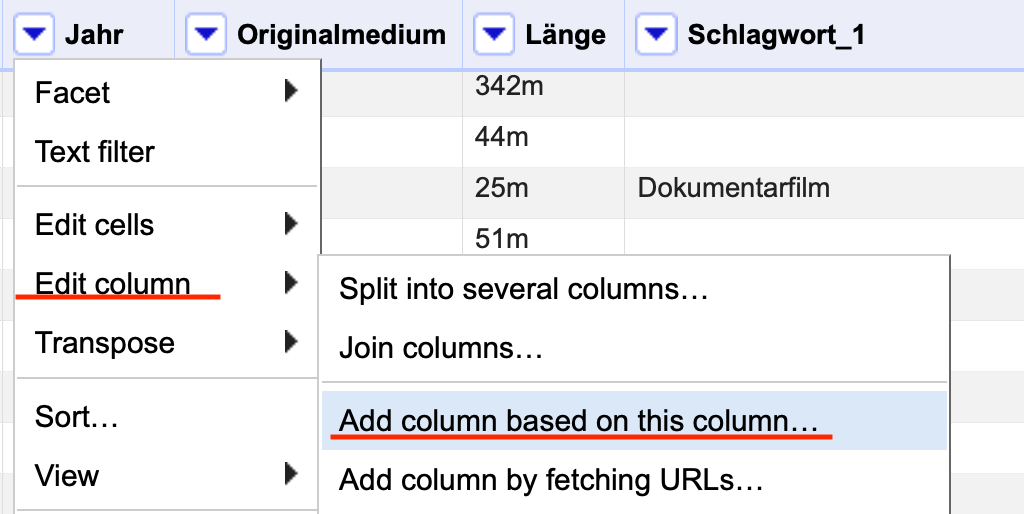
Fig. 4.70 Öffnen des Menüs zur Erstellung einer neuen Spalte#
In diesem Menü kann ebenfalls GREL-Code angewendet werden, allerdings wird das Ergebnis auf eine neue Spalte übertragen, anstatt die Einträge der Spalte zu ersetzen. Wenden Sie die vorherigen Code value.contains("ca.") an und wählen Sie einen sinnvollen Namen für die neue Spalte im Feld New column name, wie z.B. Jahr_Schätzung. Achten Sie darauf, dass Sie vor der Anwendung des GREL-Codes den Text filter für “ca.” in der Spalte Jahr deaktiviert haben. Bleibt dieser aktiv, erhält die neue Spalte lediglich die true, nicht jedoch die false-Werte.
value.contains("ca.")
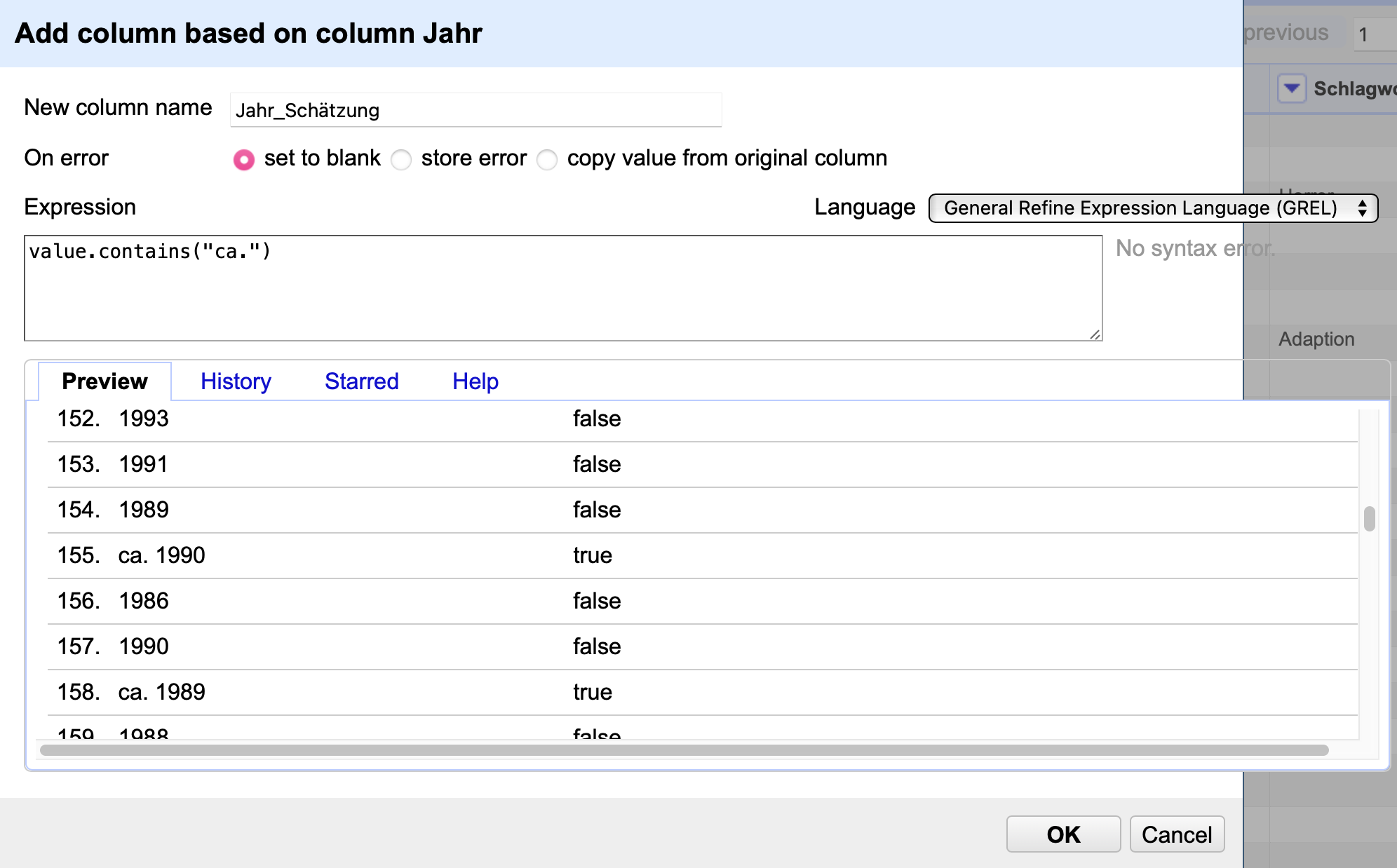
Fig. 4.71 Anwendung des Codes value.contains("ca.") zur Erstellung einer neuen Spalte Jahr_Schätzung#
Nach der Erstellung der neuen Spalte können die ca.-Angaben in der Spalte Jahr mit dem folgenden Code entfernt werden:
value.replace("ca. ", "")
Wichtig ist dabei, auch das Leerzeichen nach dem ca. zu entfernen.
Nun kann die Spalte Jahr endlich über das Split into several columns…-Menü in mehrere Spalten mit jeweils einer Jahresangabe aufgeteilt werden (siehe Bereinigung der Spalten). Als Trennzeichen dient dabei das Semikolon eingerahmnt von Leerzeichen: ;. Wählen Sie die Option Guess cell type aus, wird OpenRefine automatisch die Einträge in den neuen Spalten als Zahlen erkennen (siehe Aufteilung von Spalten).
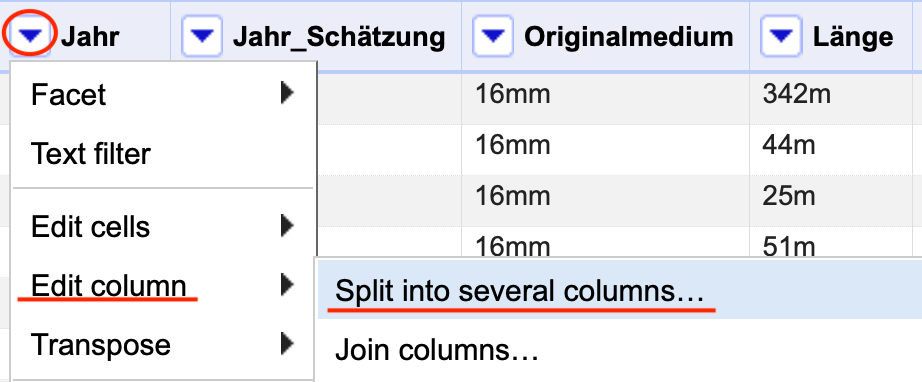
Fig. 4.72 Öffnen des Menüs zum Aufteilen von Spalten#
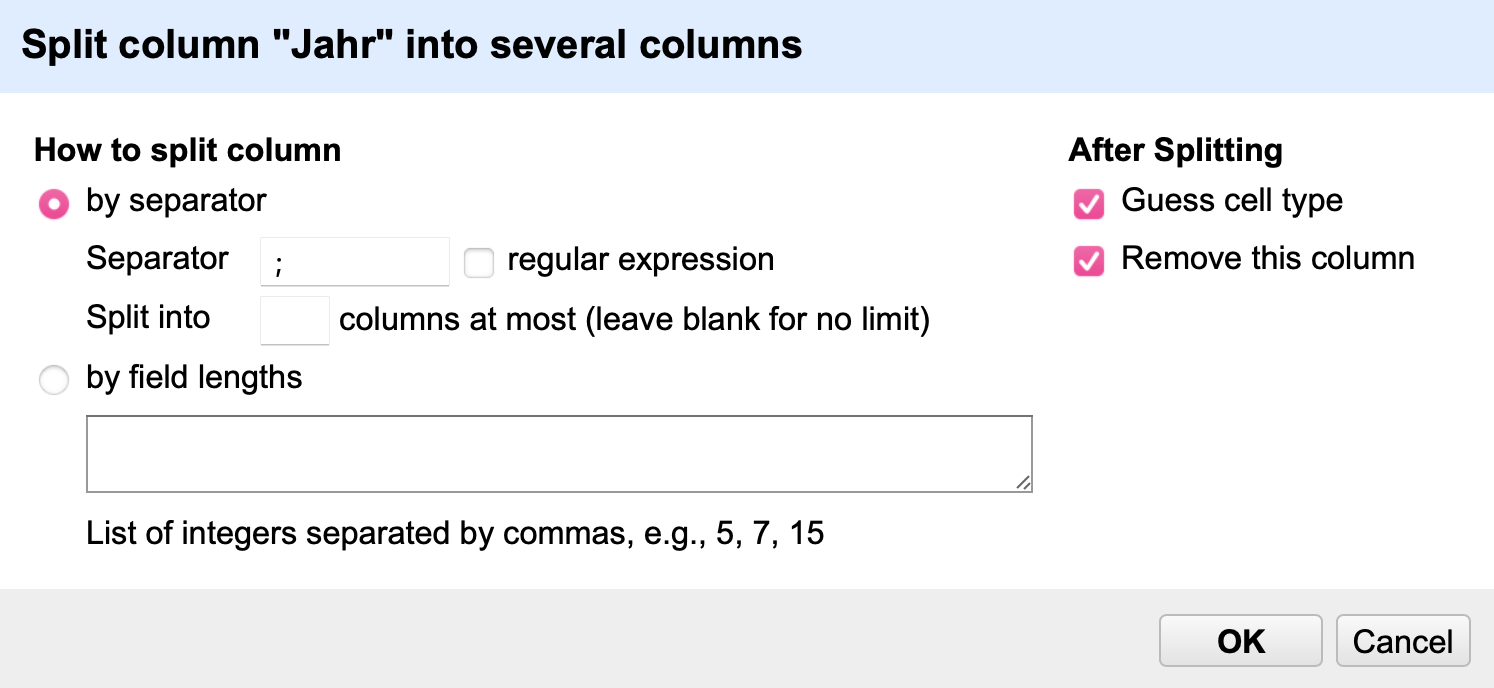
Fig. 4.73 Das Menüs zum Aufteilen von Spalten#
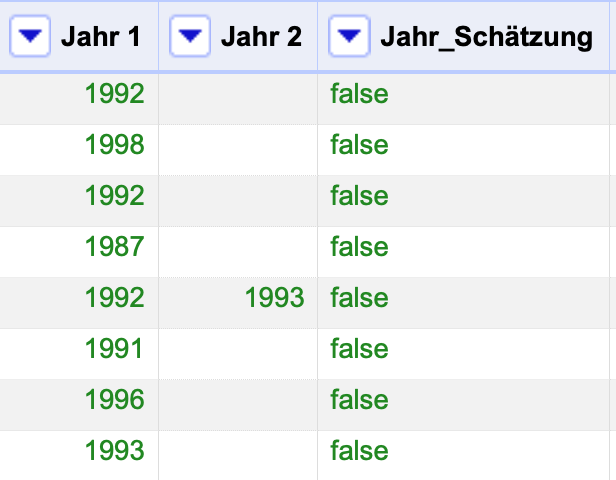
Fig. 4.74 Das Endergebnis der Bereinigung der Spalte Jahr#
Zum Ende der Bereinigung einer Spalte lohnt es sich, das Ergebnis noch einmal mittels eines Facets zu überprüfen. Für die Spalte Jahr 1 fällt auf, dass ein Eintrag noch ein zweites Jahr in runden Klammern enthält:
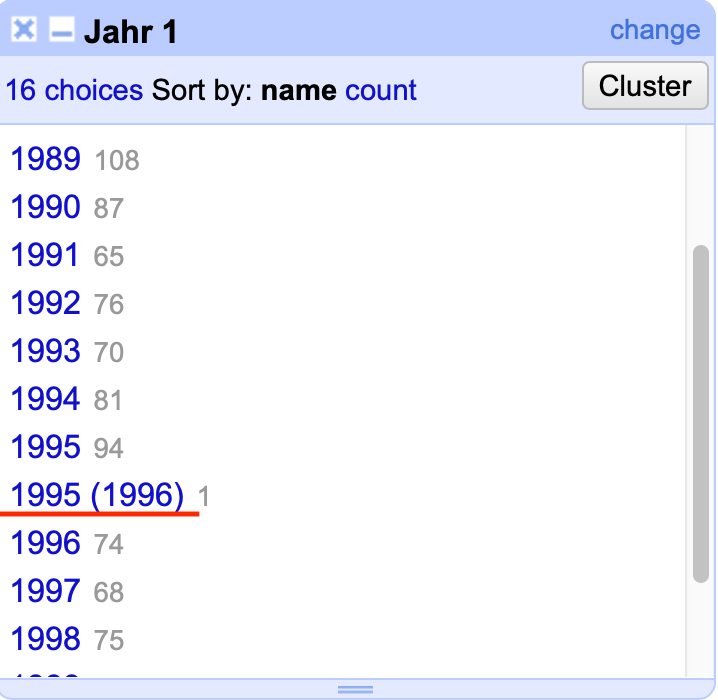
Fig. 4.75 Ein letzter fehlerhafter Eintrag#
Mit einem Klick auf den Eintrag wird Ihnen die entsprechende Zeile angezeigt. Dort können Sie nun die einzelnen Zellen mit einem Klick auf den edit-Button bearbeiten und den Eintrag so händisch bereinigen. Denken Sie bei der händischen Bearbeitung daran, den Datentyp number auszuwählen, da alle Einträge in den Jahres-Spalten in diesem Datentyp vorliegen.
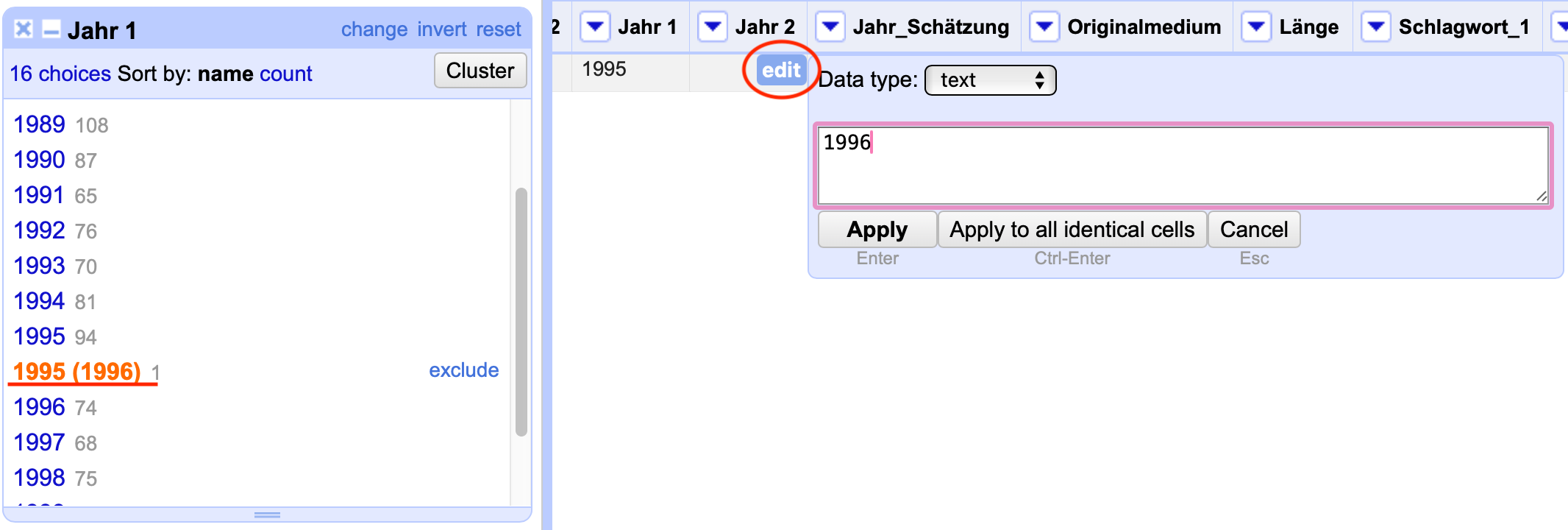
Fig. 4.76 Die händische Bereinigung von Zellen#
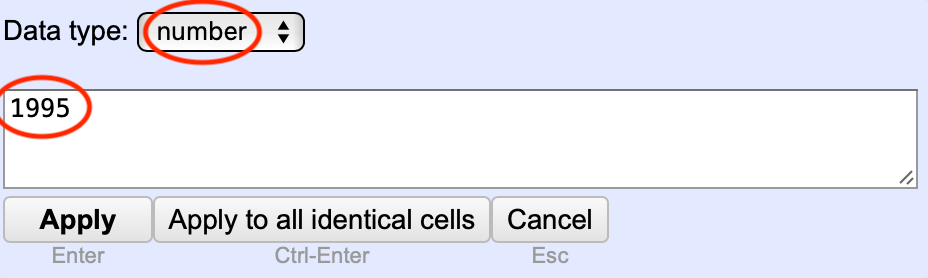
Die zweite Jahreszahl kann auf dieselbe Weise in die Spalte Jahr 2 übertragen werden.
Ersetzten Sie in einem letzten Schritt erneut die Leerzeichen in den Namen der neuen Jahresspalten durch Unterstriche.
Übung
Die Spalte Stichwort konnte bisher nicht aufgeteilt werden, da sie mehrere Trennzeichen enthält. Nutzen Sie die Methoden aus diesem Kapitel, um die Trennzeichen zu vereinheitlichen und die Spalte anschließend aufzuteilen.
Lösung
Mittels eines Text Facets können Sie feststellen, welche Trennzeichen in der Spalte vorkommen. Es sind die Zeichen
Punkt gerahmt von Leerzeichen (
.),und Semikolon gerahmt von Leerzeichen (
;),
Um die Spalte Stichwort effizient zu trennen, müssen diese Trennzeichen vereinheitlicht werden. Generell kann jedes Zeichen (oder jede Zeichenkombination) als Trennzeichen verwendet werden. In diesem Fall genügt es, eines der beiden Zeichen in das andere mittels der replace Methode zu transformieren.
Ein möglicher GREL-Code zur Lösung lautet:
value.replace(" . ", " ; ")
Im Anschluss kann die Spalte entlang des von Ihnen gewählten Zeichens aufgeteilt werden (siehe Fig. 4.72). Vergessen Sie nicht, im Anschluss die Leerzeichen in den neu entstandenen Spalten durch Unterstriche zu ersetzten!