Standardisierung der Titel#
Im vorherigen Abschnitt wurde mithilfe der GREL-Methoden replace und contains Einträge in der Spalte Jahr bearbeitet.
In Datensätzen treten jedoch oft Fälle auf, bei denen nicht nur spezifische Zeichenfolgen, sondern Muster aus mehreren aufeinanderfolgenden Zeichen gefunden, entfernt oder umgewandelt werden müssen. Ein Beispiel ist die folgende Liste aus der Spalte Titel:
<<Das>> Bild an der Wand fehlte
<<Der>> Tee war noch warm
<<Ein>> Schatten im Licht
Hier sind die Artikel der Titel in bibliothekarische Nichtsortierzeichen << >> eingefasst. Diese Zeichen verhindern, dass in einem bibliothekarischen Katalog nach den Wörtern in den Klammern sortiert wird. Im Fall von <<Das>> Bild an der Wand fehlte wird also alphabetisch nicht nach Das sondern nach Bild an der Wand sortiert. Da es sich bei unserem Datensatz um einen Auszug aus der Datenbank eines Bibliothekskatalogs handelt, wurden diese Nichtsortierzeichen in den Einträge übernommen.
Allerdings erschwert diese Markierung die alphabetische Sortierung innerhalb unseres Datensatzes sowie den Abgleich mit anderen Datenbanken. Daher sollen die Titel in ein invertiertes Format umgewandelt werden:
Bild an der Wand fehlte, Das
Tee war noch warm, Der
Schatten im Licht, Ein
Grundsätzlich ist es möglich, mit der im vorigen Abschnitt vorgestellten Methode die Titel-Einträge nach jeden einzelnen Artikel zu filtern und diesen an das Ende der entsprechenden Einträge zu setzten. Jedoch erzeugt ein solcher manueller Ansatz viele OpenRefine Edits und ist sehr fehleranfällig – insbesondere bei großen Datensätzen in mehreren Sprachen. Stattdessen empfiehlt es sich, ein Muster bezüglich des Auftretens der Artikel zu bestimmen und sie alle anhand dieses Musters in einem Schritt zu verarbeiten.
Genau diese Möglichkeit bietet eine Regular Expression, kurz Regex. Regex kann dabei im Rahmen eines GREL-Codes angewendet und somit bei OpenRefine Funktionen verwendet werden, die mit GREL-Codes arbeiten.
Einführung in Regex#
Eine Regular Expression ist eine Folge von Zeichen, die ein Textmuster beschreibt. Komplexe Regex Muster wie [+-]?(\d+(\.\d*)?|\.\d+)([eE][+-]?\d+)? wirken auf den ersten Blick sehr abschreckend und sind anders als GREL nicht intuitiv verständlich. Die meisten Muster sind allerdings deutlich einfacher strukturiert.
Code Blocks
Der folgende Text enthält einige Code-Beispiele zur Veranschaulichung des Vorgehens und der GREL- bzw. Regex-Elemente. Wenn Sie möchten, können Sie jedes der Beispiele auch in ihrem eigenen Projekt ausprobieren. Selbst anwenden müssen sie allerdings nur vollständigen Code, der in einem Code Block außerhalb des Fließtextes angezeigt wird. Ein Code Block sieht folgendermaßen aus:
Code Block
Wenn sie mit dem Mauszeiger auf den Codeblock zeigen, erscheint in der rechten oberen Ecke die Anzeige Copy to clipboard. Mit einem Klick auf diese Anzeige können Sie den Code in die Zwischenablage kopieren und in ihr OpenRefine-Projekt einfügen.
Für die Eingabe von GREL-Code mit RegexMustern öffnen Sie wiederum das Dropdown-Menü einer Spalte, den Reiter Edit cells und Transform… und gelangen so in das das entsprechende Menü.
In GREL können Regex-Muster eingesetzt werden, indem statt Anführungszeichen " " Schrägstriche / / verwendet werden, um Inhalt in Form eines Textes anzuzeigen. Ändert sich darüber hinaus nichts, bleibt auch das Ergebnis identisch:
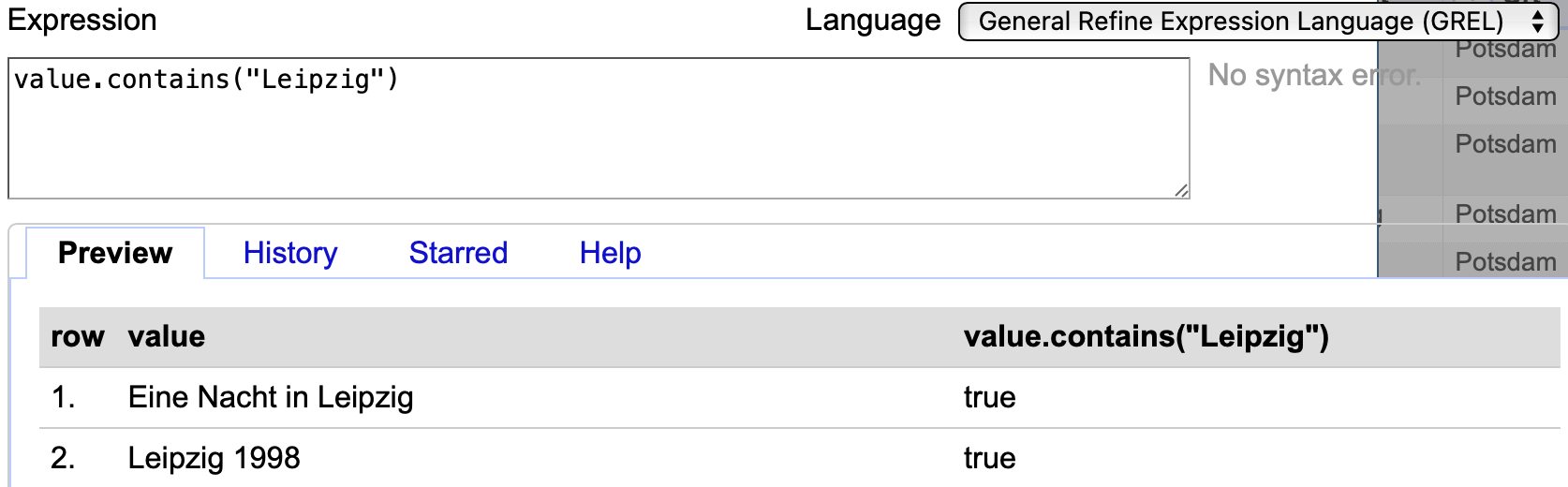
Fig. 4.77 Anwendung des Codes value.contains("Leipzig")#
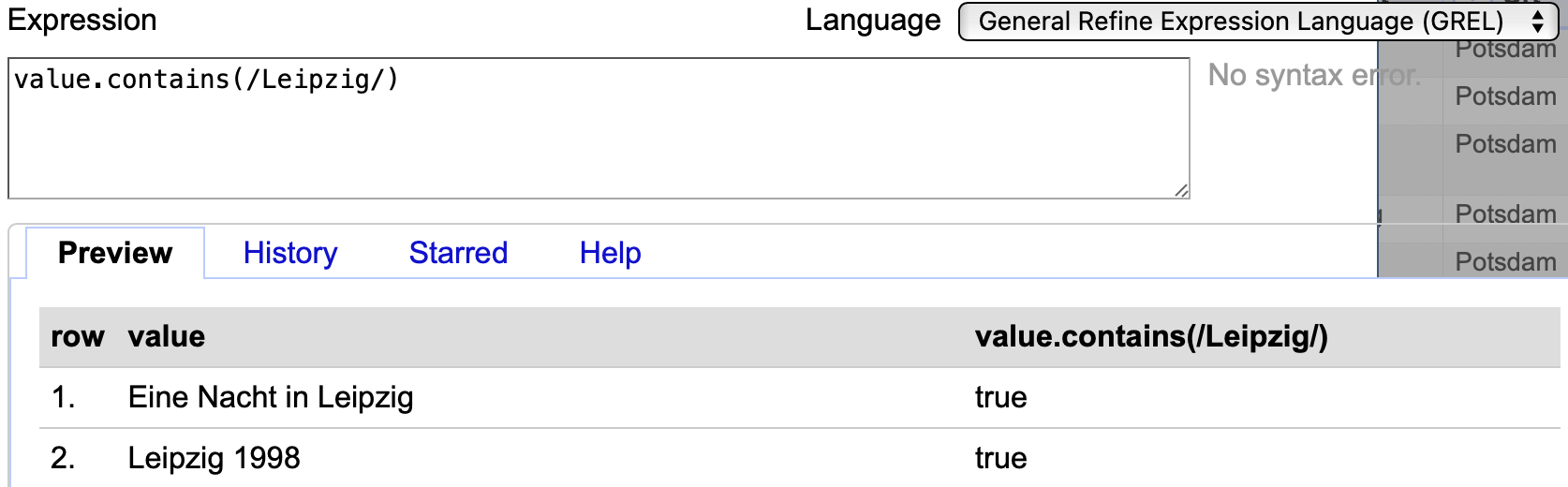
Fig. 4.78 Anwendung des Regex-Codes value.contains(/Leipzig/)#
Mittels der Methode match ist es möglich, eine Gruppe von Zeichen aus einem Eintrag zu extrahieren. Die runden Erfassungsklammern ( ) geben dabei als Argument an, welcher Teil des Musters erfasst werden soll:
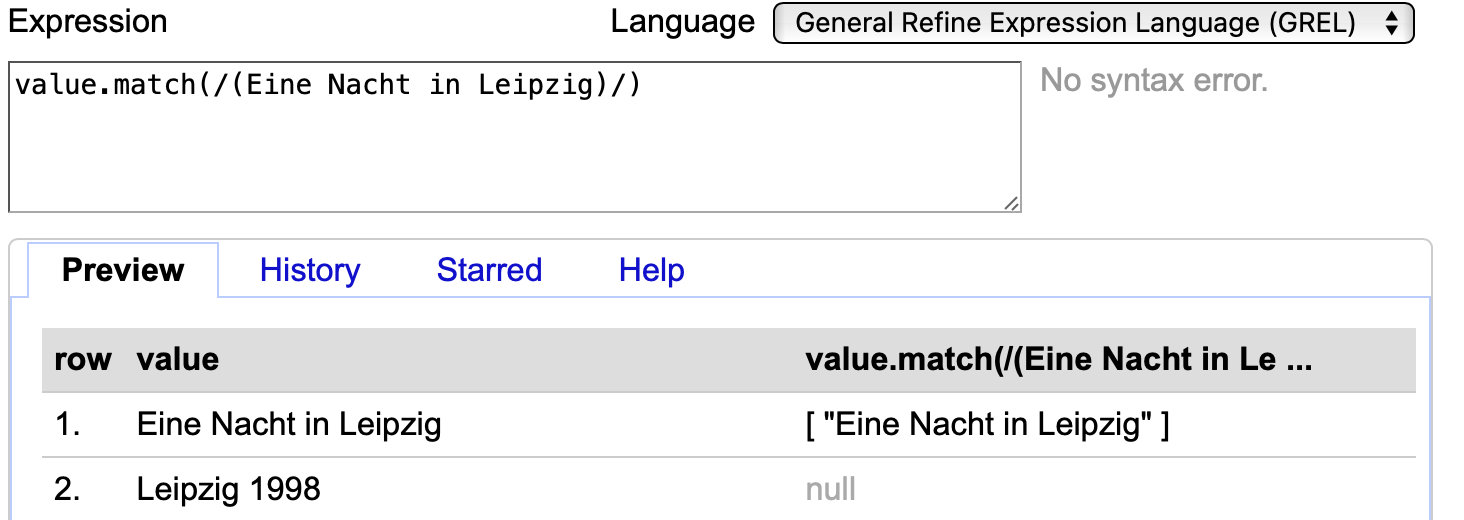
Fig. 4.79 Anwendung des Regex-Codes value.match(/(Eine Nacht in Leipzig)/)#
Enthält die Erfassungsklammer allerdings nur einen Teil des gesamten Eintrags führt dies zu keinem Ergebnis:
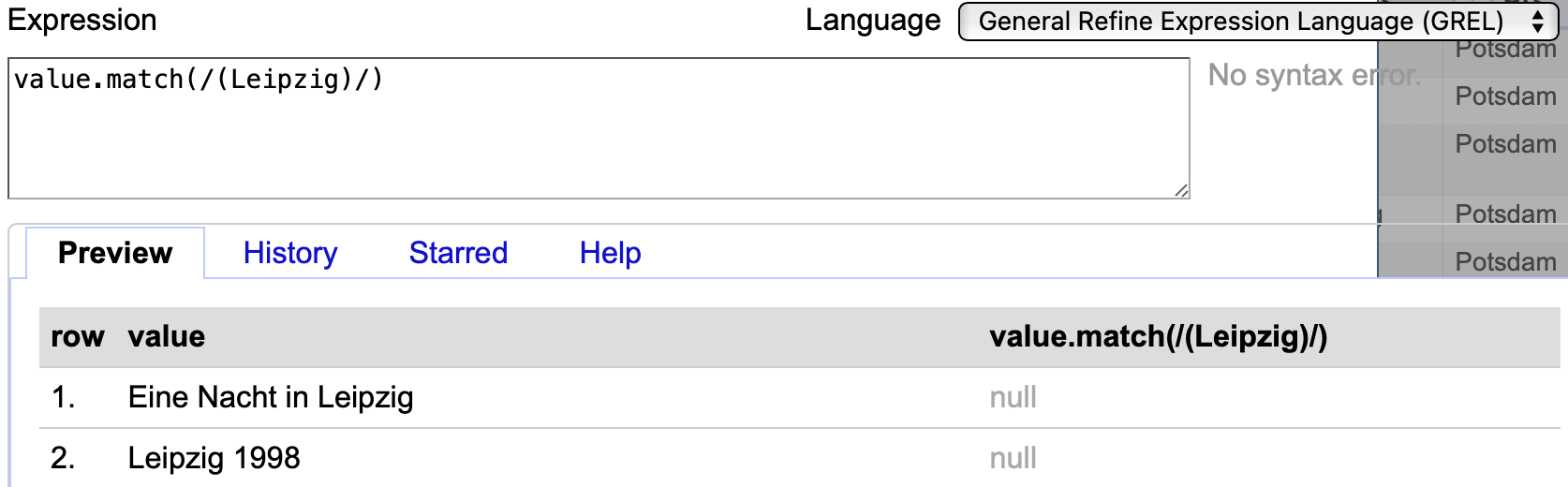
Fig. 4.80 Anwendung des Regex-Codes value.match(/(Leipzig)/)#
Ohne zusätzliche Angaben bedeutet dieses Muster, dass der komplette Text aus “Leipzig” bestehen muss. Damit der Eintrag mit “Leipzig” tatsächlich erfasst wird, muss angegeben werden, dass sich der Text nach dem Wort “Leipzig” fortsetzt, etwa durch value.match(/Eine Nacht in (Leipzig)/). Allerdings würden durch dieses Muster andere Verwendungen von “Leipzig” nicht mit einbezogen werden, wie etwa “Leipzig 1989”:
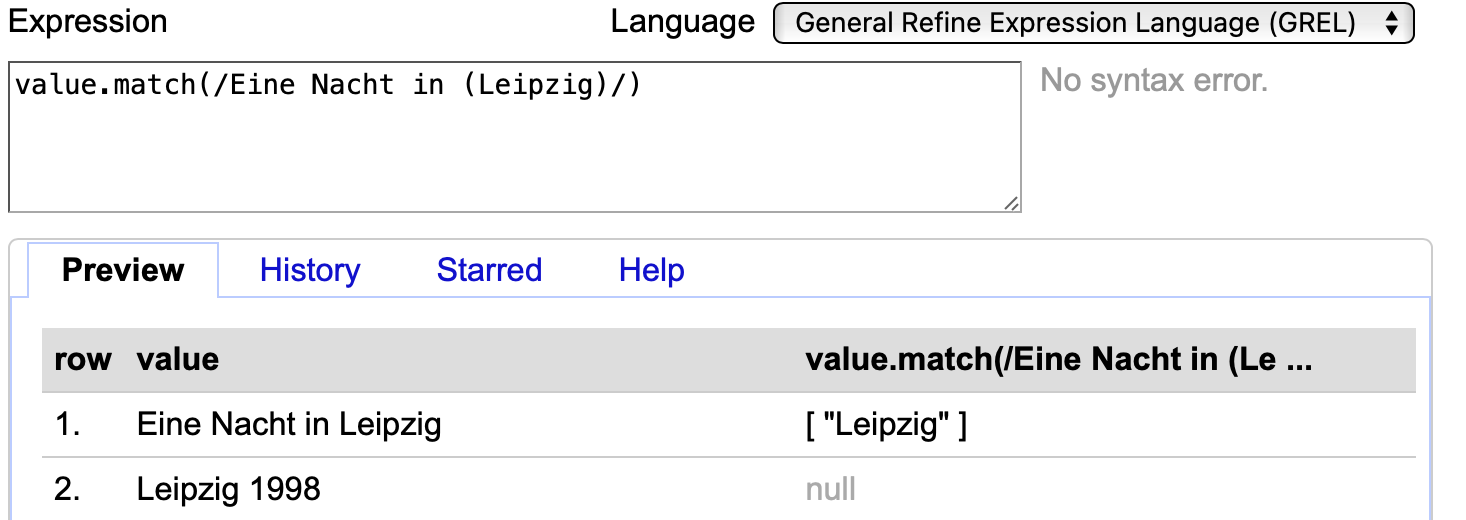
Fig. 4.81 Anwendung des Regex-Codes value.match(/Eine Nacht in (Leipzig)/)#
Um “Leipzig” für beide Titel zu erfassen, muss eine unspezifische restliche Zeichenfolge vorausgesetzt werden. Dies geschieht mit value.match(/.*(Leipzig).*/):
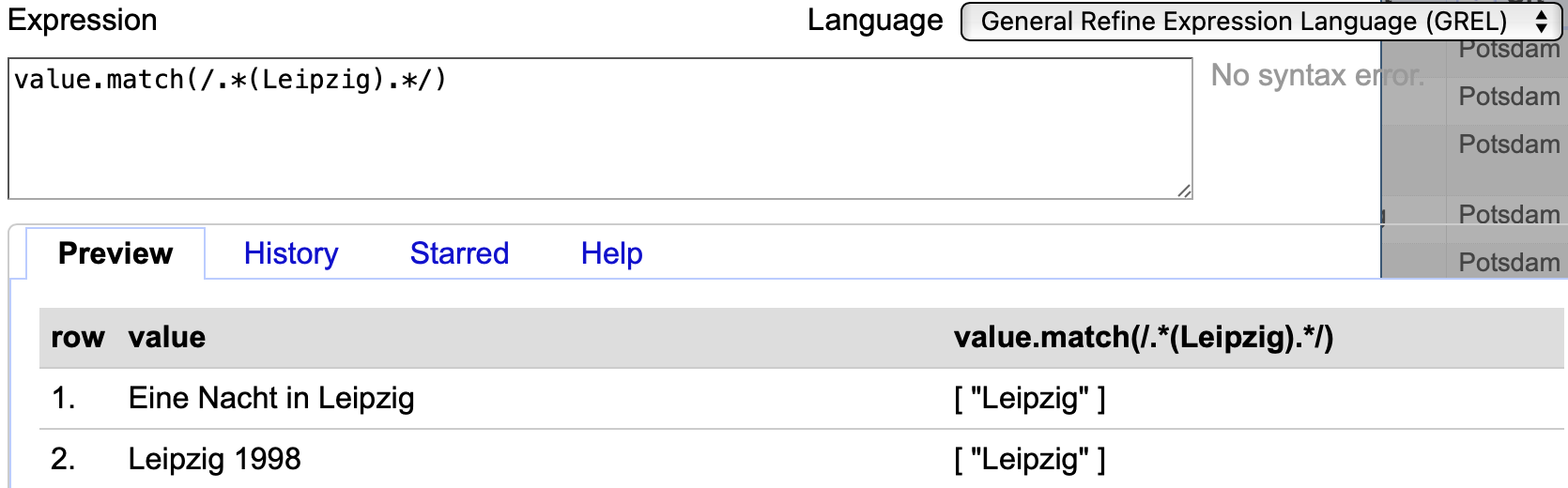
Fig. 4.82 Anwendung des Regex-Codes value.match(/.*(Leipzig).*/)#
Ein Punkt . steht in einem Regex für jedes beliebige Zeichen. Das Sternchen * gibt an, dass das vorhergegangene Zeichen in unbestimmter Häufigkeit vorkommt. Demnach bedeutet die Kombination .* , dass auf “Leipzig” eine unbestimmte Anzahl unbestimmter Zeichen folgt.
“Leipzig” ist damit erfolgreich aus zwei unterschiedlichen Einträgen extrahiert, allerdings ist das Ergebnis noch von eckigen Klammern und Anführungszeichen umgeben. Die Methode match() kann als Ergebnis eine Liste von mehreren Einträgen ausgeben, da sich auch mehrere Erfassungsklammern verwenden lassen:
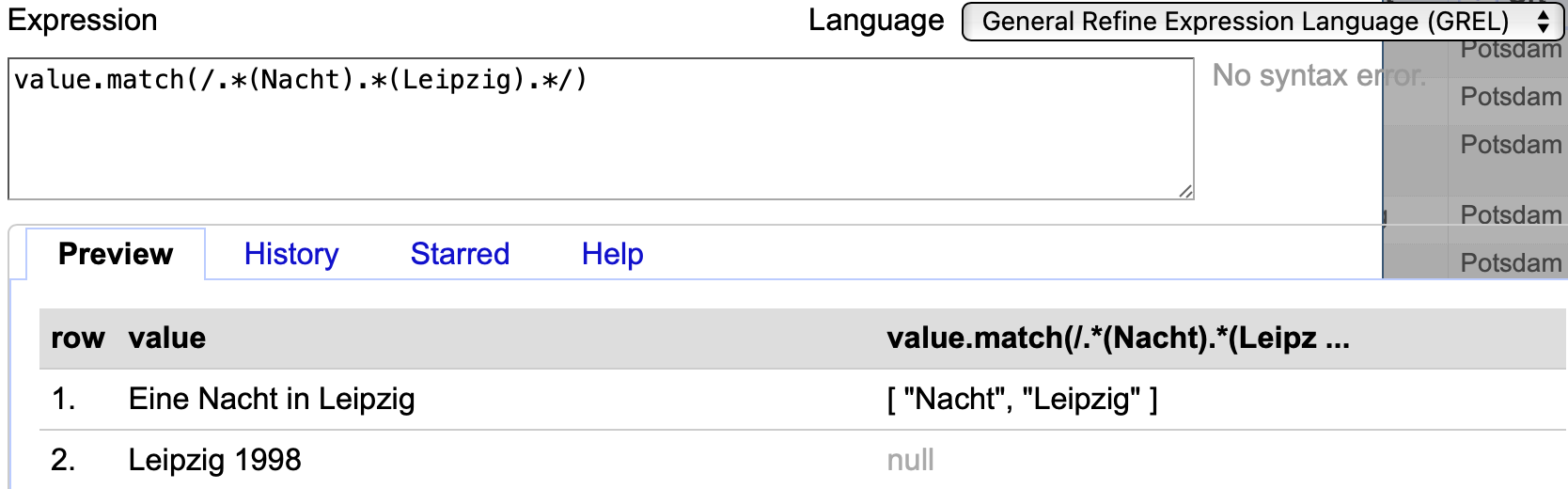
Fig. 4.83 Anwendung des Regex-Codes value.match(/.*(Nacht).*(Leipzig)/)#
Durch eckige Klammern [ ] im Anschluss an .match() ist es möglich anzugeben, welcher Eintrag aus der Liste als Zeichenfolge übernommen werden soll. Dabei steht [0] für den ersten Eintrag, [1] für den zweiten usw.
![Anwendung des Regex-Codes value.match(/.*(Nacht).*(Leipzig)/)[0]](../../_images/grel_entry0.png)
Fig. 4.84 Anwendung des Regex-Codes value.match(/.*(Nacht).*(Leipzig)/)[0]#
Indem .* in der Erfassungsklammer verwendet wird, werden auf dieselbe Weise die Artikel innerhalb der Nichtsortierzeichen << >> gefunden: value.match(/<<(.*)>>.*/).
Für die folgenden Screenshots wurde die Spalte Titel mittels eines Text Filter nach den Nichtsortierzeichen << >> gefiltert (siehe Text Filter).
![Anwendung des Regex-Codes value.match(/<<(.*)>>.*/)[0]](../../_images/grel_selectArticle.png)
Fig. 4.85 Anwendung des Regex-Codes value.match(/<<(.*)>>.*/)[0]#
Nun müssen die Artikel nur noch versetzt werden. Da wir neben den Artikeln auch das anschließende Leerzeichen entfernen wollen, ergänzen wir \s innerhalb der Erfassungsklammer, welches in Regex für ein Leerzeichen steht. Um die Artikel am Anfang zu entfernen bietet sich erneut die Methode replace in Kombination mit einer Regex an: value.replace(value.match(/(<<.*>>\s).*/)[0], "").
Fällt Ihnen auf, wie die die Erfassungsklammern verschoben wurden, um auch die Nichtsortierzeichen zu entfernen?
![Anwendung des Regex-Codes value.replace(value.match(/(<<.*>>\s).*/)[0], "")](../../_images/grel_removeArticle.png)
Fig. 4.86 Anwendung des Regex-Codes value.replace(value.match(/(<<.*>>\s).*/)[0], "")#
Als nächstes fügt + ", " ein Komma hinzu, bevor mit + value.match(/<<(.*)>>.*/)[0] der Artikel am Ende des Eintrag wieder hinzugefügt wird. Als letztes wird mit der Methode .toTitlecase() der Artikel großgeschrieben. Damit ist die Schreibweise erfolgreich invertiert:
value.replace(value.match(/(<<.*>>\s).*/)[0], "")
+ ", " + value.match(/<<(.*)>>.*/)[0].toTitlecase()
![Anwendung des Regex-Codes value.replace(value.match(/(<<.*>>\s).*/)[0], "") + ", " + value.match(/<<(.*)>>.*/)[0].toTitlecase()](../../_images/grel_moveArticle.png)
Fig. 4.87 Anwendung des Regex-Codes value.replace(value.match(/(<<.*>>\s).*/)[0], "") + ", " + value.match(/<<(.*)>>.*/)[0].toTitlecase()#
Der obige Code funktioniert nur für Einträge mit Artikeln in Nichtsortierzeichen. Bei allen anderen Einträgen führt die Ausführung des Codes zu einem Fehler:
![Fehler bei der Anwendung des Regex-Codes value.replace(value.match(/(<<.*>>\s).*/)[0], "") + ", " + value.match(/<<(.*)>>.*/)[0].toTitlecase()](../../_images/grel_moveArticle_errors.png)
Fig. 4.88 Fehler bei der Anwendung des Regex-Codes value.replace(value.match(/(<<.*>>\s).*/)[0], "") + ", " + value.match(/<<(.*)>>.*/)[0].toTitlecase()#
Dies ist allerdings kein Problem, denn mittels der Einstellung keep original im Transform-Menü wird bei einem Fehler der Code einfach nicht angewendet, sodass die Einträge ohne Artikel unverändert bleiben.

Fig. 4.89 Die Einstellungen bezüglich Fehlern im Transform-Menü#
Alternativ können die Einträge, auf welche der Code angewendet werden soll, zuvor mittels eines Text Filters oder Text Facets eingeschränkt werden.
Damit sind die Artikel innerhalb der Nichtsortierzeichen erfolgreich ans Ende der Einträge versetzt. Allerdings kommen in dem Datensatz auch eine Reihe von Artikeln vor, die nicht in die Nichtsortierzeichen eingefasst wurden – etwa im Falle von “Eine Nacht in Leipzig”. Diese Artikel sollten nun ebenfalls an das Ende der Einträge versetzt werden. Grundsätzlich wäre es möglich, mehrere der replace Methoden aneinanderzureihen, etwa nach dem Schema value.replace("Der").replace("Das").replace("Die") usw.
Angesichts der relativen Komplexität des zuvor verwendeten Codes ist ein solches Vorgehen jedoch recht mühselig. Glücklicherweise bietet OpenRefine die Funktion, auch mehrere mögliche Artikel innerhalb der replace Methode zu verwenden. Diese müssen lediglich durch das Pipe-Zeichen | voneinander getrennt werden: Der|Die|Das|Den|Dem|Des|Ein|Eine|Einen|Einem|Eines|Einer.
Nun müssen diese Artikel in die Erfassungsklammern des zuvor verwendeten Codes eingesetzt werden:
value.replace(value.match(/(?i)(Der|Die|Das|Den|Dem|Des|Ein|Eine|Einen|Einem|Eines|Einer)\s.*/)[0], "").trim()
+ ", " + value.match(/(?i)(Der|Die|Das|Den|Dem|Des|Ein|Eine|Einen|Einem|Eines|Einer)\s.*/)[0].toTitlecase()
Können Sie feststellen, welche weiteren Änderungen vorgenommen wurden?
Den Erfassungsklammern wurde die Zeichenfolge (?i) vorangestellt. Dadurch wird das match case-insensitive: Groß- und Kleinschreibung werden bei der Suche nach den Artikeln nicht beachtet. Das Leerzeichen \s wurde hinter die Erfassungsklammer verschoben – somit muss nicht jedem Artikel noch ein \s hinzugefügt werden. Zudem wurde die Methode trim
am Ende der ersten Zeile des Codes ergänzt. Diese entfernt Leerzeichen am Anfang und Ende des Titel.
Der Code kann nun angewendet werden:
![Die Anwendung des Regex-Codes value.replace(value.match(/(?i)(Der|Die|Das|Den|Dem|Des|Ein|Eine|Einen|Einem|Eines|Einer)\s.*/)[0], "").trim() + ", " + value.match(/(?i)(Der|Die|Das|Den|Dem|Des|Ein|Eine|Einen|Einem|Eines|Einer)\s.*/)[0].toTitlecase()](../../_images/grel_moveArticle_noBrackets.png)
Fig. 4.90 Die Anwendung des Regex-Codes value.replace(value.match(/(?i)(Der|Die|Das|Den|Dem|Des|Ein|Eine|Einen|Einem|Eines|Einer)\s.*/)[0], "").trim() + ", " + value.match(/(?i)(Der|Die|Das|Den|Dem|Des|Ein|Eine|Einen|Einem|Eines|Einer)\s.*/)[0].toTitlecase()#
Mit der Anwendung des GREL-Codes sind die Artikel bei den Filmtiteln nun nachgestellt und großgeschrieben. Die Spalte Titel somit in dieser Hinsicht erfolgreich bereinigt.