4.1. Datenmodell#
In den letzten Abschnitten wurde eine filmwissenschaftliche Fragestellung entwickelt und ein Filmkorpus eingegrenzt. Als Korpus wurden die studentischen Filme im Archiv der Filmuniversität Babelsberg KONRAD WOLF aus den Jahren 1985 bis 1999 identifiziert, für die nun Metadaten in Form von filmografischen Angaben erhoben werden sollen, die für die weitere Bearbeitung der Fragestellung erforderlich sind. Wie können diese Informationen in einer hierfür geeigneten Form erfasst werden?
4.1.1. Datensätze aus dem Bibliothekskatalog#
Bisher wurden die Datensätze zu einzelnen oder einer Gruppe von Filmen über den Online-Bibliothekskatalog (OPAC) der Filmuniversität mittels gezielter Suchanfragen abgerufen (vgl. Kapitel Materialrecherche). Im Rahmen dieser ersten Überblicks-Recherche zum vorhandenen Filmmaterial war es ausreichend, die filmografischen Daten per “Copy and Paste” aus der Trefferanzeige des Katalogs zu kopieren, z.B. in ein Textverarbeitungsprogramm oder ein Programm zur Tabellenkalkulation. Die Menge der recherchierten Filme blieb dabei übersichtlich, daher konnte auf diese Weise wie im Kapitel Materialrecherche im Abschnitt zur Sichtung von Filmen beschriebenen ein erster Vergleich und eine erste stichpunktartige Auswertung bezüglich potenzieller Gemeinsamkeiten stattfinden.
Für das gesamte Korpus der Filme wäre diese Vorgehensweise nicht durchzuführen: Bei der Überblicks-Recherche ergab sich auf die Suchanfrage nach studentischen Filmen aus den Jahren 1985 bis 1999 im Katalog eine Trefferanzahl von 1366 bibliografischen Einträgen. Welche alternativen Möglichkeiten gibt es nun, einen Datensatz mit den Metadaten bzw. filmografischen Daten zum Filmkorpus unserer Fallstudie zu erstellen?
Um Informationen aus Webseiten zu extrahieren und zu speichern wird häufig das sogenannte “Web Scraping”[1] angewendet. Hierfür stehen verschiedene Software-Tools zur Verfügung, die jedoch meist Programmierkenntnisse und ein grundlegendes Wissen über den technischen Aufbau und die Abfrage von Webseiten voraussetzen. Häufig sind auch ethische und rechtliche Aspekte zu beachten, wie z.B. Fragen des Urheber- und Persönlichkeitsrechtes. Zudem kann Web Scraping aus technischen Gründen nicht bei allen Web-Ressourcen eingesetzt werden. Insgesamt erscheint uns daher im Rahmen dieser OER Web Scarping nicht als das geeignete Mittel, den erforderlichen Datensatz zu erheben.
Für die Abfrage von filmografischen Daten stehen im Internet verschiedene nicht-kommerzielle und kommerzielle Datenbanken zu Verfügung. Deren Daten können meist durch vorhandene Schnittstellen abgerufen und in einen Datensatz zusammengestellt werden. Hierfür sind wiederum Programmierkenntnisse und technisches Wissen über die Funktionsweisen und den Aufbau von Datenbanken notwendig. Insbesondere bei kommerziellen Datenbanken wie IMDb ist oft nur ein Teil der Informationen frei in Form von Datensätzen erhältlich, für zusätzliche Informationen muss bezahlt werden. Einige filmbezogene Datenbanken stellen ihre Einträge als (Teil)datensätze in verschiedenen Formaten frei zum Download zur Verfügung, wie z.B. die omdb. In allen diesen Fällen müssen für die Arbeit mit diesen Daten und insbesondere bei der weiteren Publikation der erstellten Datensätze Rechtliche Rahmenbedingungen wie Urheberrechte und vorhandene Lizenzen beachtet werden.
Ein Großteil der studentischen Produktionen in unserem Untersuchungszeitraum sind in diesen Datenbanken jedoch nicht erfasst, da es sich um unveröffentlichte Werke wie Übungen handelt, die nur im Archiv der Filmuniversität vorhanden und auch nur dort verzeichnet sind. Die Zusammenstellung eines Datensatzes mit den filmografischen Angaben zu unserer Fallstudie ist über diese Datenbanken also nicht möglich.
Gerade bei Datensätzen, die sehr spezielle Informationen enthalten, die evtl. nur in einer bestimmten Datenbank oder bei einer bestimmten Institution vorgehalten werden, bietet es sich an, dort direkt anzufragen. Insbesondere bei nicht-kommerziellen Organisationen ist es für Forschungszwecke häufig möglich, einen Auszug mit den für die eigene Arbeit notwendigen Daten aus der Datenbank zu erhalten. Wir haben daher bei der Bibliothek der Filmuniversität angefragt, ob uns die Daten aus dem Katalog des Filmarchivs für unseren Untersuchungszeitraum 1985 bis 1999 zur Verfügung gestellt werden können.
4.1.2. Auszug aus der Datenbank des Bibliothekskatalogs#
Der Systembibliothekar der Filmuniversität erklärte sich bereit, für unsere Fallstudie einen Auszug aus der Datenbank des Bibliothekskatalogs zu erstellen, der alle Einträge aus dem OPAC für die Filme unseres Korpus enthält.
Achtung
Bei unserer weiteren Arbeit mit dem auf dem Auszug basierenden Datensatz zu den studentischen Filmen zur Wendezeit stellte sich heraus, dass dieser in den filmografischen Angaben personenbezogene Daten enthält. Da für diese Angaben nicht gesichert ist, dass die betroffenen Personen einer Veröffentlichung zugestimmt haben, können wir diesen Datensatz nun nicht publizieren. Auf die genauen Probleme die sich ergeben haben und die geltenden rechtlichen Rahmenbedingungen gehen wir im Kapitel zu Problemfeldern bei der Datenpublikation noch ein. Für die Veranschaulichung der weiteren Arbeitsschritte verwenden wir einen synthetischen Datensatz, der im Kapitel zur Datenbereinigung besprochen wird.
Auch wenn der originale Datensatz im Rahmen unserer Fallstudie nicht veröffentlicht werden kann, stellen wir im Folgenden dennoch unsere weitere Vorgehensweise dar. Als Screenshots werden Einträge zu einem Werk genutzt, das später auf DVD veröffentlicht wurde – Andreas Dresens Film “Stilles Land” (1992). In diesem Fall kann davon ausgegangen werden, dass die Zustimmung der beteiligten Mitwirkenden für eine Veröffentlichung ihrer personenbezogenen Daten erteilt wurde.
Der Auszug aus der Datenbank des Bibliothekskatalogs liegt uns als tsv-Datei vor, also in Form einer Text-Datei, bei der die einzelnen Einträge zu den Filmtiteln durch Tabulatoren voneinander getrennt werden.[2] Dabei sind die Informationen in einzelne Felder untergliedert, die innerhalb des OPACs unter “Vollanzeige des Titels” angezeigt werden. (Fig. 4.2)
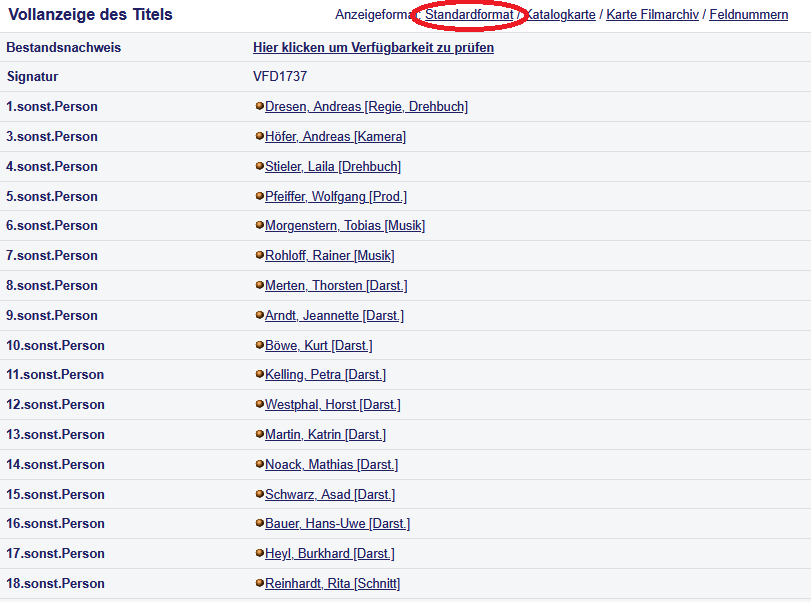
Fig. 4.2 Ausschnitt aus der Vollanzeige eines Einzeltitels im “Standardformat” im OPAC der Filmuniversität.#
Wird in der Vollanzeige des Titels das Anzeigeformat “Feldnummern” angewählt, werden weitere Felder angezeigt, die im “Standardformat” nicht sichtbar waren, aber in der Auszugs-Datei enthalten sind. (Fig. 4.3)

Fig. 4.3 Ausschnitt aus der Vollanzeige eines Einzeltitels im Anzeigeformat “Feldnummern” im OPAC der Filmuniversität.#
In der Vollanzeige des Titels und in den verschiedenen Anzeigeformaten wird deutlich, dass die filmografischen Daten und damit die Metadaten zu den Titeln einer bestimmten Struktur, einem bestimmten Modell folgen. Auf die Funktion und auf den Aufbau solcher Datenmodelle geht Johanna Drucker ein (Drucker, 2021). Sie weist darauf hin, dass jede Erzeugung von Daten eine Modellierung beinhaltet. Durch ein Modell wird festgelegt, was als Merkmal des Datenobjekts – hier des jeweiligen Films – aufgeführt wird, d.h. was für die Charakterisierung als notwendig erachtet wird. Zudem muss entschieden werden, in welchem Format diese Informationen vorliegen sollen.
Mit Bezug auf Herbert Stachowiak führt Fotis Jannidis genauer aus, was mit dem Oberbegriff “Modell” gemeint ist (Jannidis, 2017). Er nennt drei Aspekte:
Aspekte eines Modells
Ein Modell ist immer eine Abbildung, es repräsentiert etwas.
Es ist nicht das Original, auch nicht dessen Kopie; es weist nicht alle Merkmale des Originals auf, sondern nur ausgewählte.
Ein Modell hat einen oder mehrere Verwendungszwecke.
Dass eine Auswahl aus Merkmalen getroffen wird, impliziert auch, dass Modelle und damit Datenmodelle, wie schon im Abschnitt zu Metadaten ausgeführt, bestimmte Weltanschauungen, Werte und Werturteile enthalten (Drucker, 2021).
4.1.3. Analyse des Modells als Ausgangspunkt#
Bevor existierende Daten – in dieser Fallstudie die Daten zu den Filmen aus dem OPAC der Filmuniversität – verwendet werden, sollte daher nach Drucker immer das zugrundeliegende Modell analysiert und verstanden werden. Welche Merkmale wurden aufgenommen? Fehlen evtl. bestimmte Merkmale? Wie sind Felder benannt und welche Klassifikationssysteme sind erkennbar?
Eine tiefgreifende Analyse des Datenmodells und der Struktur der OPAC-Daten kann an dieser Stelle nicht erfolgen. Auf Teile dieses Themenbereichs wird im folgenden Abschnitt zur Analyse der Datenquelle und im Abschnitt Datenbereinigung nochmals eingegangen. Einen ausführlichen Überblick über die Prozesse bei der Erschließung von Metadaten zu Filmen für Kataloge liefert Anna Bohn (Bohn, 2018).
Da es sich bei den OPAC-Daten um Daten aus einer existierenden Datenbank handelt, liegen diese in einer strukturierten Form vor. Aus der Vollanzeige des Titels im Bibliothekskatalog wird etwa deutlich, dass der Datensatz Informationen zu beteiligten Personen, Titel, Jahr und Format enthalten sollte. Zudem sind Schlagworte, Stichwörter und eine Inhaltsbeschreibung aufgeführt. Es zeigt sich jedoch auch, dass in einem Feld häufig mehrere Einträge aufgeführt werden. In dem jeweiligen Feld für “sonstige Personen” ist z.B. sowohl der Name der Person als auch deren Funktion(en) eingetragen (z.B. Regie, Drehbuch, Kamera, Darsteller:in etc.). Und das Feld “Umfang/Format” führt neben dem Filmformat (16mm, 35mm etc.) u.a. die Dauer in Minuten auf. (Fig. 4.4)
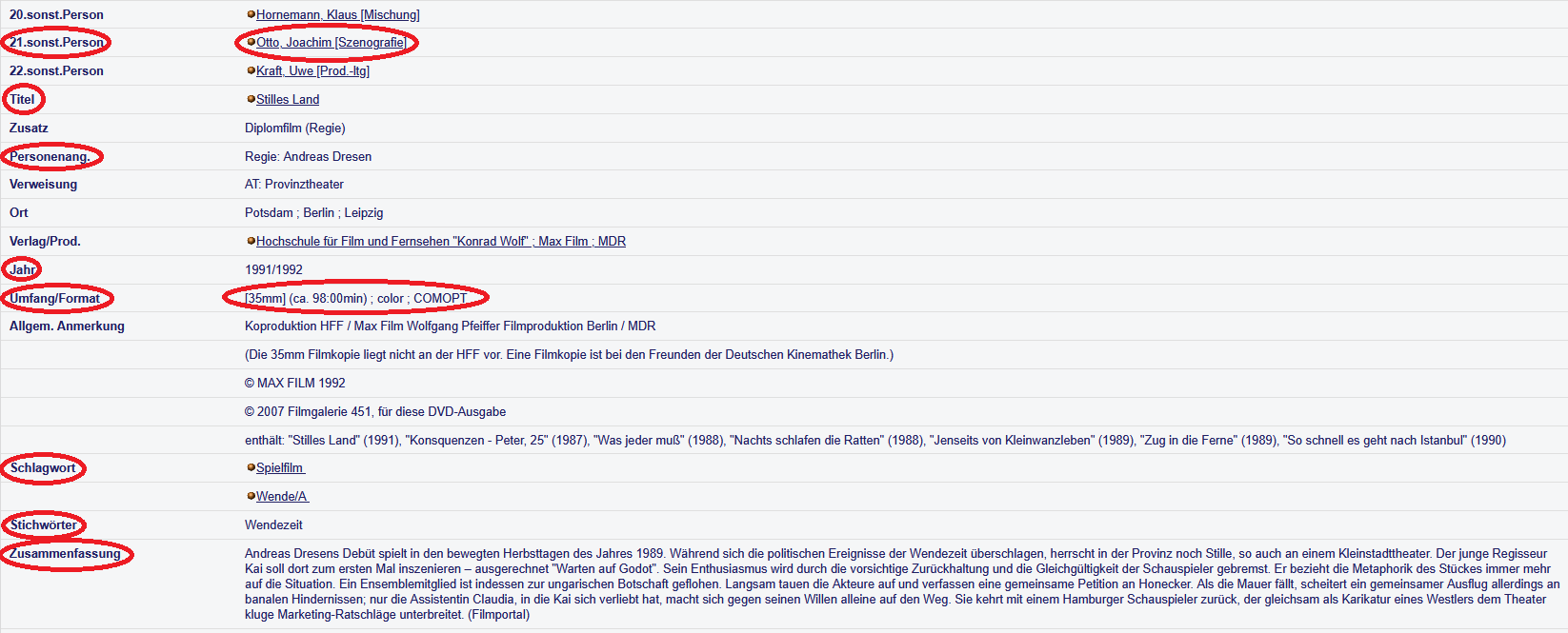
Fig. 4.4 Felder in der Vollansicht eines Eintrags des Bibliothekskatalogs#
4.1.4. Notwendige Datenbereinigung#
Bereitet man die Daten zu den Filmen in Form einer Tabelle auf, enthält eine Zelle der Tabelle mehrere Informationen. Für eine Datenstruktur, die maschinell ausgewertet werden kann, darf jede Zelle lediglich einen eindeutigen Wert bzw. Eintrag aufweisen. Dies deutet darauf hin, dass der Datenauszug aus dem OPAC der Filmuniversität noch bearbeitet – also “bereinigt” werden muss, z.B. indem mehrere Werte in einer Zelle jeweils auf einzelne neue Zellen aufgeteilt werden. Für diese Bereinigung, aber auch für die weitere Arbeit mit dem Datensatz, ist es sinnvoll zu verstehen, nach welchen Kriterien die Erfassung der filmografischen Daten im Bibliothekskatalog stattgefunden hat, und warum diese Struktur gewählt wurde. Darauf wird im folgenden Abschnitt eingegangen.
4.1.5. Literatur#
Bohn, A. (2018). Film-Metadaten. Standards der Erschließung von Filmen mit RDA und FRBR im internationalen Vergleich und Perspektiven des Datenaustauschs. Berlin: Institut für Bibliotheks- und Informationswissenschaft der Humboldt Universität zu Berlin. doi:10.18452/19220
Drucker, J. (2021). The Digital Humanities Coursebook: An Introduction to Digital Methods for Research and Scholarship. London, New York: Routledge. doi:10.4324/9781003106531
Jannidis, F. (2017). Grundlagen der Datenmodellierung. In F. Jannidis, H. Kohle, & M. Rehbein (Eds.), Digital humanities: eine Einführung, 99–108. Stuttgart: J.B. Metzler Verlag. doi:10.1007/978-3-476-05446-3_7