4.3. Datenbereinigung#
Im vorigen Abschnitt wird deutlich, dass unser Datensatz zu den studentischen Filmen im Archiv der Filmuniversität inkonsistent ist und z.B. Doppelungen enthält. Daher muss der Datensatz noch bereinigt werden. Erst dann kann er fundiert hinsichtlich der Fragestellung unserer Fallstudie ausgewertet werden. Für diesen Prozess stehen verschiedene Softwarelösungen zur Verfügung. So können mit Microsoft Excel Schritte der Datenbereinigung durchgeführt werden. Das Programm ist zwar kostenpflichtig, viele haben es jedoch bereits auf ihren Computern installiert. Zudem existieren zahlreiche kommerzielle Produkte, die speziell für die Vorbereitung von Datensätzen zur Auswertung mit digitalen Tools entwickelt wurden – wie z.B. Tableau Prep.
Für die Bereinigung des Datensatzes zu unserer Fallstudie haben wir mit OpenRefine gearbeitet, einer frei zugänglichen und kostenlosen Open-Source-Software, die speziell für die Datenbereinigung entwickelt wurde. Sie weist einen großen Funktionsumfang auf und verfügt über eine hilfreiche Dokumentation. Die grundlegenden Schritte zur Bedienung des Programms sind leicht erlernbar.
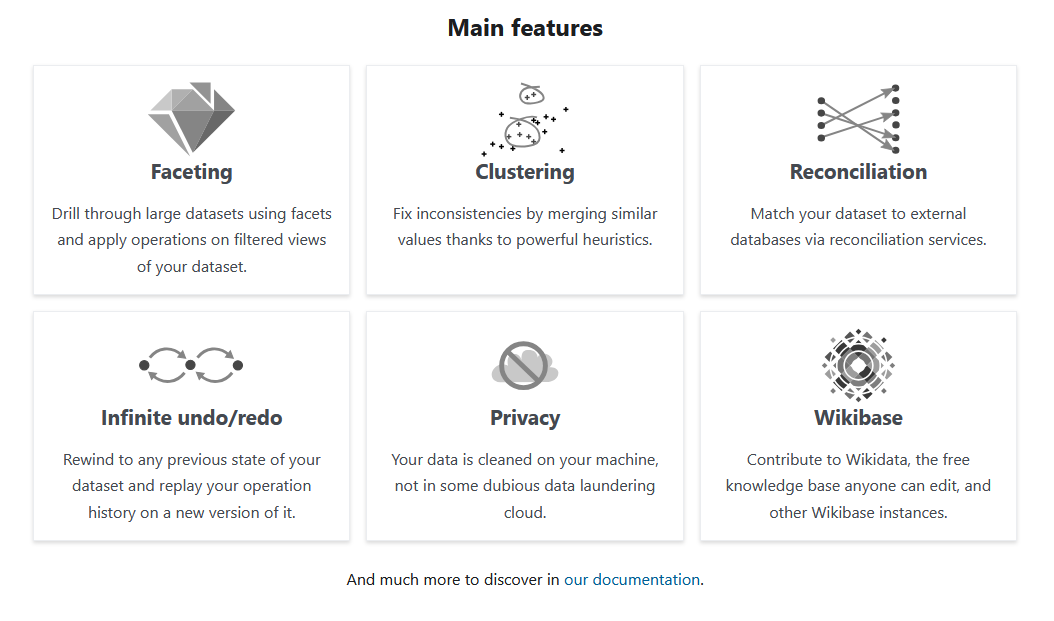
Fig. 4.9 Screenshot von der OpenRefine-Webseite mit den Merkmalen der Software#
Ziele der Datenbereinigung
Die Ziele der Datenbereinigung werden bereits im Abschnitt zum Datenmodell kurz angesprochen. Am Ende der Bereinigung soll ein konsistenter, einheitlich strukturierter Datensatz stehen, der maschinenlesbar ist und im besten Fall auch von Menschen verstanden werden kann. In jeder Zeile sollen die Daten zu einem Objekt enthalten sein – in unserem Fall zu einem Filmtitel. Für jede Variable (hier z.B. Regie, Jahr, Dauer etc.) existiert eine Spalte, jede Zelle der Spalte enthält nur einen eindeutigen Wert (in unserem Fall z.B. nur den Namen der Regie und nicht gleichzeitig weitere Namen oder Gewerke). Der Datensatz weist keine doppelten Einträge mehr auf, auch leere Zeilen oder Spalten wurden entfernt.
Für eine solche Bereinigung des Datensatzes unserer Fallstudie sind zahlreiche Bearbeitungsschritte notwendig, die wir hier nicht alle darstellen und für Sie nachvollziehbar machen können. Dieses Vorgehen wäre zu kleinteilig und würde das Verständnis des Ablaufs eines Bereinigungsprozesses erschweren. Wir beschränken uns daher auf einige exemplarische Schritte bei der Bereinigung mit OpenRefine. Diese wurden jedoch so ausgewählt, dass das Vorgehen auch auf Probleme übertragen werden kann, die bei der Bearbeitung anderer Datensätze auftreten. Zudem verweisen wir im Folgenden auf passende weiterführende Informationen in der OpenRefine Dokumentation.
Datenbasis und synthetische Datensätze
Die Datenbasis für die Bereinigung bildet ein Auszug aus der OPAC-Datenbank, den wir vom Systembibliothekar der Universitätsbibliothek erhalten haben. Der Auszug liegt uns als Datei im tsv-Format vor (siehe auch Kapitel Datenformte) und enthält sämtliche OPAC-Einträge für unser Korpus aus dem Untersuchungszeitraum – also zu den studentischen Filmen der Jahre 1985 bis 1999 aus dem Filmarchiv der Filmuniversität. Auf der Grundlage dieser Datenbasis haben wir die Daten bereinigt.
Achtung
Nach der Bereinigung der Daten zu unserem Korpus stellte sich heraus, dass im finalen Datensatz personenbezogene Daten beinhaltet sind. Die filmografischen Daten enthalten Angaben zu den an den Filmen beteiligten Personen und welche Funktion sie jeweils übernommen haben.
Da es sich um größtenteils unveröffentlichte, studentische Filmproduktionen handelt, kann leider nicht mit Sicherheit gewährleistet werden, dass alle am Film beteiligten und in den Daten genannten Personen der Veröffentlichung ihrer Daten zugestimmt haben. Zusätzlich müsste überprüft werden, ob die Funktion der Person korrekt wiedergegeben wird.
Daher ist es uns leider nicht möglich, die Datenbasis oder den bereinigten Datensatz zu publizieren. Auf die Problemfelder, personenbezogene Daten und rechtlichen Rahmenbedingungen bei der Datenpublikation gehen wir in einem eigenen Kapitel noch genauer ein.
In diesem Kapitel wollen wir dennoch die wichtigsten Schritte einer Datenbereinigung mit OpenRefine anhand eines Beispiels darstellen und für Sie nachvollziehbar machen. Daher haben wir vom bereinigten Originaldatensatz ausgehend einen synthetischen Datensatz erstellt, in dem ein Personenbezug nicht mehr besteht. Für diesen Datensatz haben wir die Filmtitel und die Namen der Personen durch fiktive Einträge ersetzt. Die Zuordnung der fiktiven Personennamen zu den fiktiven Filmtiteln wurde zufällig vorgenommen, ebenso wurden Schlagworte und Stichworte nach dem Zufallsprinzip durchmischt. Die proportionale Verteilung einzelner Einträge innerhalb eines Jahres sollte dabei annäherungsweise erhalten bleiben.
Synthetische Datensätze
Auf dieser Grundlage haben sich zwei synthetische Datensätze für den weiteren Einsatz in der OER ergeben
ein synthetischer Auswertungsdatensatz, der dem bereinigten Originaldatensatz in seiner Struktur nachgebildet ist und im Kapitel zur Datenauswertung und Datenvisualisierung zum Einsatz kommen wird
ein synthetischer Übungsdatensatz, der für die Darstellung der Arbeitsschritte mit OpenRefine bei der Datenbereinigung verwendet wird und auf dem Auswertungsdatensatz basiert.
Beide synthetischen Datensätze stellen wir für Übungszwecke zum Download zur Verfügung.
In den folgenden Abschnitten werden wir für die Demonstration des Vorgehens bei einer Datenbereinigung und der Funktionen von OpenRefine zunächst mit dem reduzierten synthetischen Übungsdatensatz arbeiten. Einige bisher nicht bereinigte Spalten wurden für die Darstellung der Arbeitsschritte und die Übungen wieder in den Datensatz aufgenommen. Ein Großteil der Spalten, die nicht für die Beschreibung des Bereinigungsprozesses notwendig sind, wurden gelöscht, z.B. solche, die Informationen zu beteiligten Personen und Gewerke enthalten. Dadurch soll die Übersichtlichkeit und die Handhabbarkeit des Datensatzes im Rahmen der OER gewährleistet werden.
Das weitere Vorgehen
Wie soll nun im Folgenden weiter vorgegangen werden? Die ersten beiden Abschnitte widmen sich der Installation des Programms und dem Import eines Datensatzes, der anschließend im dritten Abschnitt mit den Funktionen von OpenRefine gesichtet wird. In den nächsten beiden Abschnitten wird auf die Bereinigung von Spalten und Zellen bzw. Einträgen eingegangen, bevor der Datensatz im letzten Abschnitt für die Auswertung exportiert wird.

Fig. 4.10 Schritte in diesem Abschnitt#
Wenn nicht anders angegeben, stammen sämtliche verwendeten Screenshots von der Arbeitsoberfläche OpenRefines und wurden ebenso wie die Grafiken speziell für diese OER selbst erstellt.