6.2. Formen der Datenpublikation#
Um die eigene Forschung sichtbar und nachvollziehbar zu machen und um die erhobenen Daten in anderen Forschungsprojekten nachzunutzen, sollten Datensätze publiziert werden. Für die Form solcher Publikationen hat sich bisher noch kein allgemeingültiger Standard entwickelt. Sophie Einwächter führt aus, dass in der Medienwissenschaft wie auch in anderen Geisteswissenschaften bisher Erfahrungen mit Datenpublikationen fehlen und sich diese zudem erst als anerkannte wissenschaftliche Publikationsform etablieren müssen (Einwächter, 2022).
Als Orte für die langfristige Datenspeicherung bieten sich die im letzten Kapitel dargestellten Repositorien an, die zudem die Kriterien der Zugänglichkeit und Auffindbarkeit erfüllen. Grob lassen sich dabei drei verschiedene Formen der Datenpublikation unterscheiden:
Formen der Datenpublikation
In einem wissenschaftlichen Beitrag werden Forschungsergebnisse veröffentlicht und dabei auf Daten verwiesen, die in einem Repositorium abgelegt sind.
Daten werden mit einer kompakten Beschreibung in einem Repositorium publiziert.
In einem Data Paper werden in einem Repositorium gespeicherte Daten ausführlich beschrieben und deren Potenzial analysiert.
Diesen drei Formen werden im Folgenden betrachtet.
6.2.1. Artikel mit Verweis auf Daten im Repositorium#
Wissenschaftliche Artikel, die Forschungsergebnisse darstellen und deren Qualität durch den Prozess eines Peer-Reviews sichergestellt wird, sind als Publikationsform etabliert. In einem solchen Beitrag können Daten bezüglich einer Forschungsfrage ausgewertet und die Datenanalyse in die Argumentation eingebaut werden. Im Artikel wird auf Daten verwiesen, die an einem öffentlich zugänglichen Speicherort wie einem Repositorium abgerufen werden können. Teilweise schreiben es die Regularien eines Publikationsmediums vor, dass zugehörige Daten für den Review-Prozess verfügbar sein und anschließend auch veröffentlicht werden müssen.
Beispiele für diese Art der Publikationsform werden im Abschnitt zu Filmwissenschaft und Digital Humanities vorgestellt. In einer Special Issue des Journal of Cultural Analytics, das sich mit dem Themenbereich Digital Film Historiography: Challenges of/and Interdisciplinarity beschäftigt und von Malte Hagener und Diana Roig-Sanz herausgegeben wurde, sind Beiträge versammelt, die sich mit digitaler Filmgeschichtsschreibung aus verschiedenen Perspektiven beschäftigen. Die zugehörigen Datensätze wurden in einem Repositorium veröffentlicht. Die vorgestellten Forschungsergebnisse können also mit den Datensätzen nachvollzogen und diese ggf. in anderen, weiterführenden Forschungsprojekten verwendet werden.
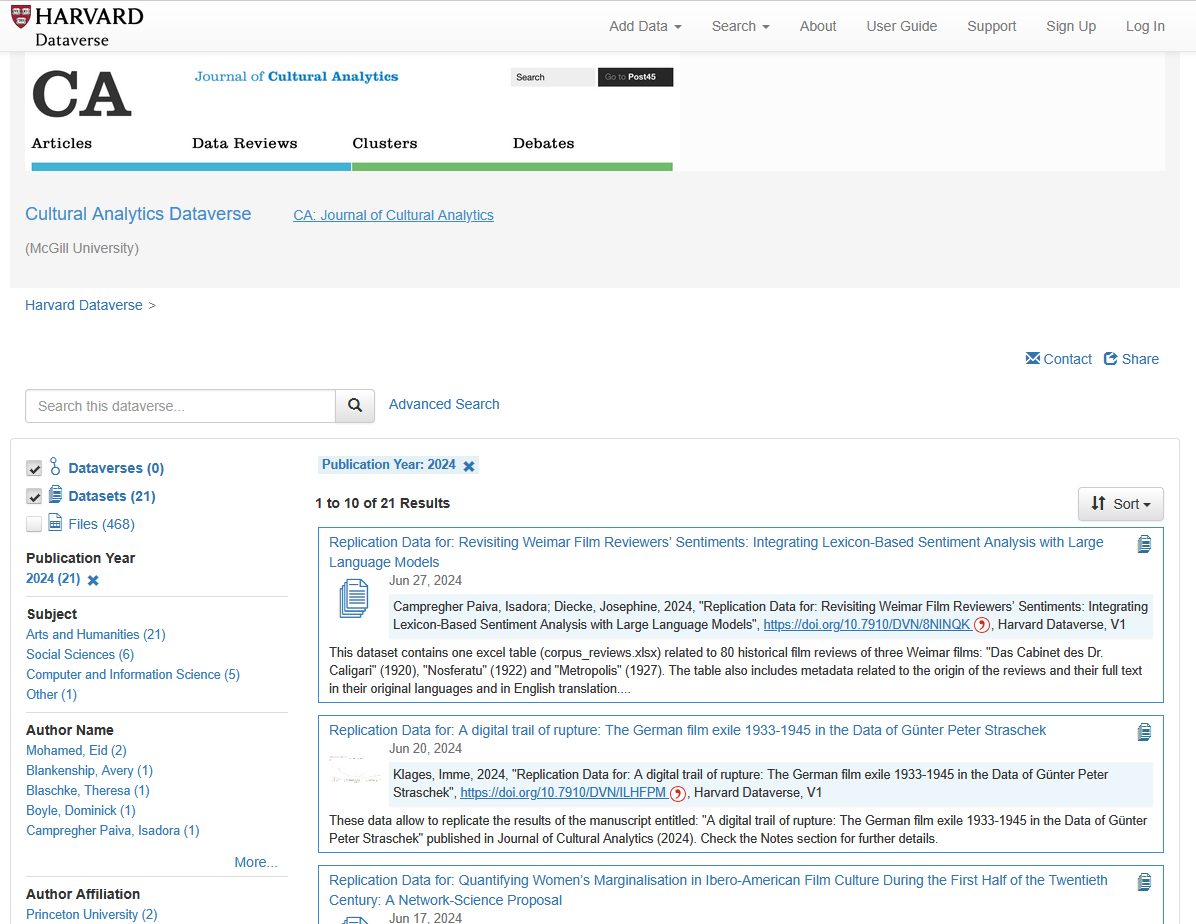
Fig. 6.7 Screenshot einer Liste mit Datensätzen zu Beiträgen im Journal of Cultural Analytics#
6.2.2. Daten in einem Repositorium#
Datensätze können in einem Repositorium nicht nur im Kontext eines veröffentlichten Artikels abgelegt werden, sondern auch als eigenständige Datenveröffentlichung. In beiden Fällen sollten bestimmte Kriterien erfüllt werden. Neben dem Titel sollten die Autor:innen des Datensatzes, das Veröffentlichungsdatum und die Version ersichtlich sein – Datensätze können auch weiterentwickelt und aktualisierte Versionen zur Verfügung gestellt werden. Wichtig ist ein kompakter Beschreibungstext, aus dem hervorgeht, in welchem Kontext die Daten entstanden sind, wie sie erhoben wurden und was in einzelnen Dateien des Datensatzes enthalten ist. Deutlich erkennbar sollte sein, unter welcher Lizenz der Datensatz veröffentlicht wurde (z.B. CC BY 4.0), unter welchen Bedingungen er also weiter genutzt werden kann. Oft werden auch Stichworte und Themen angegeben, was der einfacheren Auffindbarkeit dient.
Es folgen die einzelnen Dateien des Datensatzes, versehen mit entsprechenden beschreibenden Metadaten. Für diese Dateien sollten bevorzugt Dateiformate verwendet werden, die programmunabhängig sind, wie z.B. Textdateien im csv-, tsv- oder xml-Format, wie sie im Abschnitt zu Datenformaten im Kapitel zur Datenbereinigung beschrieben wurden. Diese haben den Vorteil, dass sie in zahlreiche digitale Tools zur Weiterverarbeitung und Auswertung der Daten eingelesen werden können. Oft werden aber auch Excel-Tabellen dort abgelegt. Es bietet sich an, Dateien hinzuzufügen, die den Inhalt und die Struktur der in den Dateien enthaltenen Daten beschreiben (z.B. in Form eines “Codebooks”, das einzelne Variablen und Spaltennamen aufschlüsselt). Für eine genauere Einordnung des gesamten Datensatzes erweist sich eine readme-Datei als nützlich, also eine einfache Textdatei mit den zentralen Informationen zum Datensatz, die zusammen mit den Daten heruntergeladen wird.
Die einzelnen Dateien eines Datensatzes können meist entweder einzeln angewählt und heruntergeladen werden oder als gesamter Datensatz mit allen Dateien.
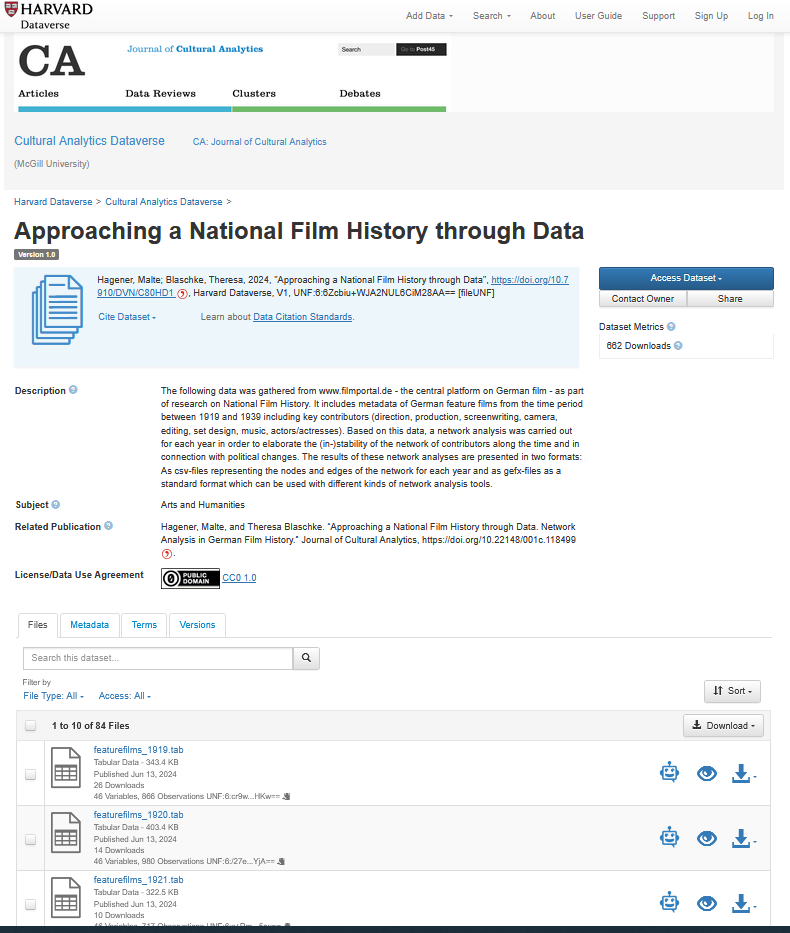
Fig. 6.8 Screenshot eines Eintrags zu einem Beitrag im Journal of Cultural Analytics#
6.2.3. Data Papers#
Data Papers unterscheiden sich von Artikeln mit publizierten Daten dadurch, dass ihr Fokus nicht auf Forschungsergebnissen liegt, sondern auf der Datenaufbereitung, der genauen Beschreibung des veröffentlichten Datensatzes und dessen Potenziale für die Forschung. Data Papers werden in speziellen Journals oder in Rubriken von fachspezifischen Journals veröffentlicht. Für die Film- und Medienwissenschaft wurde z.B. eine Rubrik für Data Papers im NECSUS_European Journal of Media Studies eingerichtet.
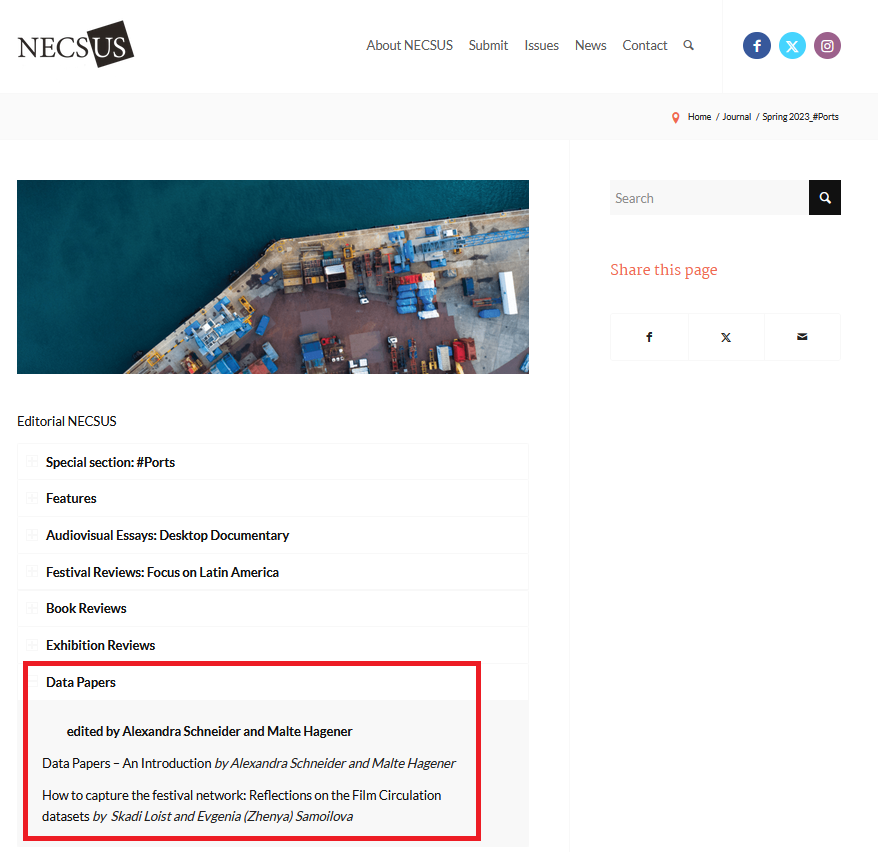
Fig. 6.9 Screenshot der der Rubrik ”Data Papers” im NECSUS_European Journal of Media Studies#
Der Aufbau eines Data Papers kann variieren und wird häufig vom publizierenden Journal vorgegeben. Meist fokussiert sich ein Data Paper zunächst auf die Beschreibung des Datensatzes und dessen Struktur: Welche Dateien sind enthalten und wie ist die Beziehung zwischen den Dateien? Handelt es sich z.B. um einen Auszug aus einer Datenbank mit verschiedenen Tabellen, die untereinander mit eindeutigen Identifikatoren in Beziehung gesetzt werden können?
Daran anschließend wird das Datenmodell beschrieben. Bei komplexen Datenmodellen werden auch grafische Darstellungen der Modelle eingefügt. Darauf aufbauend werden die Datenerhebung und die Datenquellen dargelegt. Wer hat die Daten in welchem Kontext erhoben? Wurden die Daten automatisch oder manuell erfasst? Welche Quellen wurden verwendet, z.B. Angaben aus Zeitungen, Handelsregistern, Förderinstitutionen oder Festivals-Archiven? Und falls mehrere Quellen ausgewertet wurden: Wie wurden diese zusammengeführt? Wie sah der Prozess der Standardisierung aus?
Im Diskussionsteil wird das Datenmodell ausführlich reflektiert (z.B. ob die Variablen und Feldnamen sinnvoll gewählt sind oder an welchen Stellen Lücken im Datensatz erkennbar sind), ebenso wie die Datenquellen (z.B. die Methoden der Datenerhebung, wo sind die Grenzen der Quellen, was kann mit ihnen erforscht werden). Auch die Möglichkeiten der Nachnutzung und der Erweiterung des Datensatzes sollten diskutiert werden.
Auf die Diskussion folgt eine Zusammenfassung der Ergebnisse des Papers, die auch einen Ausblick auf weitere Einsatzmöglichkeiten des Datensatzes enthalten kann. Ein Data Paper sollte einen Datensatz verständlich erschließen, ihn durchdringen und kritisch reflektieren und damit eine optimale Grundlage für eine mögliche Nachnutzung legen.
6.2.4. Literatur#
Einwächter, S. G. (2022 , March). Was hindert uns daran, Forschungsdaten zu publizieren? | Zeitschrift für Medienwissenschaft.