5.1. Von der Freitextannotation zur Ontologie#
Im vorigen Kapitel haben wir anhand von zwei Tools gezeigt, wie mithilfe digitaler Werkzeuge filmanalytisches Vokabular sowie formalästhetische Beschreibungen als Freitextannotationen entlang einer Timeline angelegt werden können. Die Annotationsspuren und Annotationen sowie ihre dazugehörigen Werte beruhen in diesem Schritt auf Freitexteingaben. Ein festgesetztes Datenframework zur Vereinheitlichung und Konzeptualisierung dieses Grundvokabulars lag dieser Arbeit noch nicht zugrunde.
In diesem Kapitel soll es darum gehen, diese Konzeptualisierung bzw. Systematisierung des Grundvokabulars der Filmanalyse in so ein Framework nachvollziehbar und als Übung reproduzierbar zu machen. Entwickelt wurde die sogenannte AdA-Filmontologie basierend auf den Ordnungsprinzipien und Funktionsweisen von Semantic Web Standards. Diese werden nachfolgend erläutert.
5.1.1. Semantische Triple#
Nachdem wir die die praktischen Möglichkeiten der digitalen Annotation kennengelernt haben, stellt sich nun die zentrale Frage: Wie können diese beiden Bereiche – also filmanalytische Beschreibungen (Annotationen) und Semantic Web Prinzipien – konkret zusammengeführt werden? Anders formuliert: Wie lassen sich die durch Annotationen erfassten filmanalytischen Beschreibungen in ontologische Strukturen des Semantic Web integrieren?
Der Schlüssel liegt in der Transformation der Annotationsdaten in ein Format, das sowohl den Semantic Web Standards entspricht als auch für filmanalytische Zwecke praktikabel ist. Denn die in den Annotationstools erfassten Informationen – seien es Einstellungsgrößen, Schnittrhythmen oder Farbwerte – müssen so strukturiert werden, dass sie Teil einer maschinenlesbaren Ontologie werden können.
Dazu müssen die filmanalytischen Beschreibungen der Annotationen maschinenlesbar gemacht werden. Gleichzeitig soll es nicht um eine reine “computer vision” gehen, sondern die Daten sollen auch für Menschen lesbar und verständlich sein. Die informationstechnologische Antwort darauf sind sogenannte semantische “triple”. Diese bestehen aus für Menschen als einfache Sätze lesbare Aussagen nach dem Schema: “Subjekt” - “Prädikat” - “Objekt”.
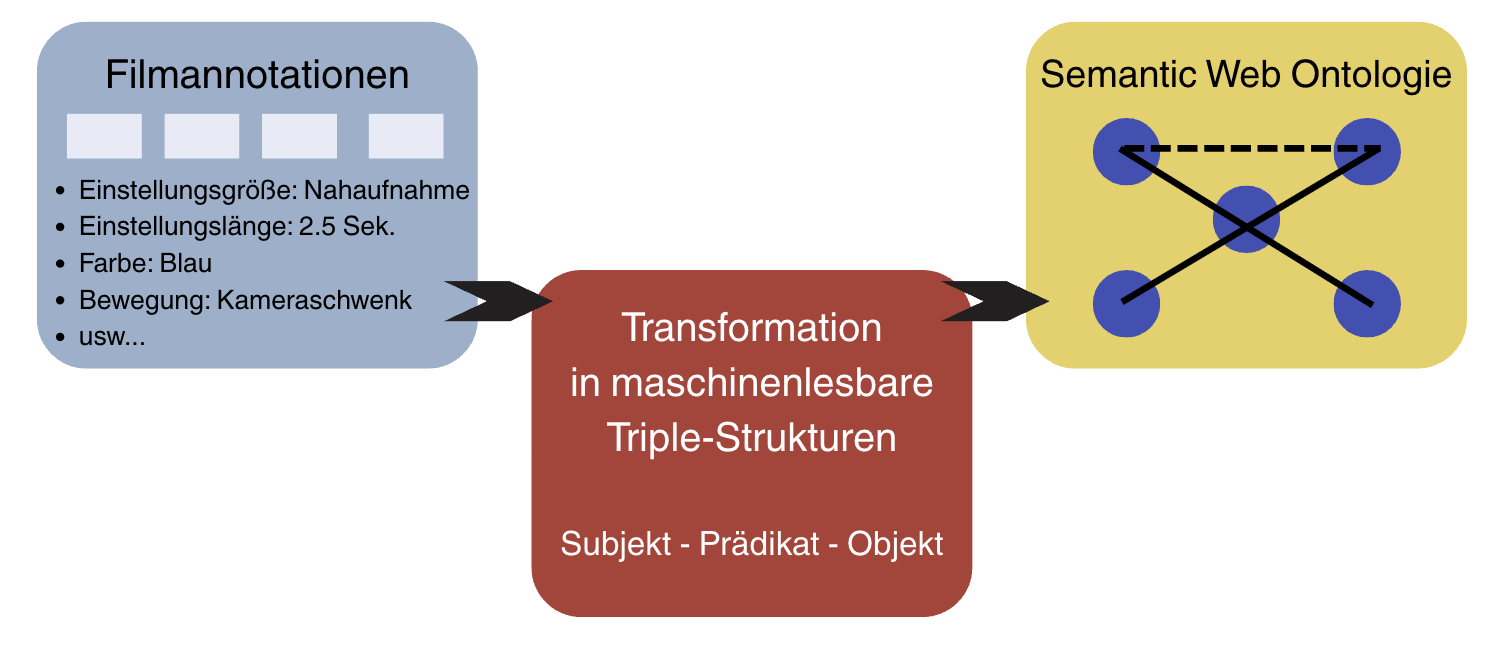
Fig. 5.1 Abstrakte Visualisierung: Tranformation filmanalytischer Begriffe in Triple-Struktur nach Semantic Web#
Darin bezeichnet das “Prädikat” eine spezifische Relation zwischen dem “Subjekt” und dem “Objekt”. Der entscheidende Schritt zur Maschienenlesbarkeit ist, dass alle drei Teile dieser Aussage mit eindeutigen “identifiern (URI)” verknüpft sind. Das kann für geschlossene Datensysteme eine einfache Zahlenkombination oder ein QR-Code sein, im Sinne der Vernetzung von Wissen sind es i.d.R. eine URL, also nach dem Format von Webadressen.
Ein einfaches Beispiel:
“Berlin” (Subjekt) - “ist die Hauptstadt von” (Prädikat) - “Deutschland” (Objekt)
“Berlin” (Subjekt) - “hat eine Einwohnerzahl von” (Prädikat) - “3.878.100” (Objekt)
Dadurch ist die Abfrage, wie viele Einwohner die Hauptstadt von Deutschland habe, möglich: Was ist der Wert für das Prädikat “hat Einwohnerzahl von” für die Entität auf die das Prädikat “ist die Hauptstadt von” den Wert “Deutschland” hat? Wenn in einer Datenbank - bzw. nennt man diese Verlinkung von Triplen zusammen einen “Graph” – alle Informationen auf diese Weise formalisiert sind, lassen sich alle möglichen Relationen abfragen: Eine Liste aller Hauptstädte, eine Liste von Städten nach Einwohnerzahl etc.
Das Semantic Web arbeitet mit Sprachen zur Beschreibung der Inhalte, einer der bekanntesten ist “RDF” (Resource Description Framework). RDF ist eine Standardsprache zur Beschreibung von Ressourcen (Ressourcen können sein: ein Wort, ein Dokument, eine Grafik, eine Website usw.) im World Wide Web und wurde vom World Wide Web Consortium (W3C) entwickelt.
Nehmen wir unser Beispiel von oben, als semantisches Triple formuliert in RDF mit URLs als URIs können unsere Relationen folgendermaßen aussehen:
<http://example.org/Berlin> <http://example.org/istDieHauptstadtVon> <http://example.org/Deutschland>
Wie kann nun eine solche Formalisierung für die Begriffe der Filmanalyse aussehen? D.h., welche “Subjekte”, “Prädikate” und “Objekte” sind hier sinnvoll festzulegen?
5.1.2. Filmanalytische Begriffe als semantische Triple#
Unser “Subjekt” ist immer “Segment X”. Dieser Identifier ist zum einen verknüpft mit dem Film (Prädikat: “ist aus”, Objekt: “Film ABC”) und hat dort eine konkrete Anfangs- und Endzeit (Prädikat “hat Timecode von”, Objekt: “ff:ss:mm:hh - ff:ss:mm:hh”). Diese Zeitangabe kann einer Einstellung entsprechen, einem einzelnen Frame oder einer freien Segmentierung. Zum anderen werden ihm auf verschiedenen Ebenen analytische Werte zugeschrieben. Damit diese Angaben als Relationen formulierbar sind, ist der erste Schritt, das Vokabular als Prädikate im Sinne von “hat in einer bestimmten analytischen Dimension” und Objekte der Art “eine bestimmte Eigenschaft” schematisch darzustellen.
Für diesen Zweck hat das BMBF-geförderte Projekt ”Affektrhetoriken des Audiovisuellen” einen Prototyp der Formalisierung vorgenommen und die Ada-Filmontologie publiziert (Pfeilschifter et al., 2021). Die Annotationen haben darin stets das Format: “Segment X” “hat auf dem analytischen Type Y” “den Value Z” (für einen besseren Überblick sind die einzelnen Typen zusätzlich auf analytischen “Leveln” gebündelt).
Zur Veranschaulichung haben wir eine Grafik erstellt, die die Triple-Struktur anhand eines konkreten Beispiels nachvollziehbar macht. Bitte beachten Sie, dass es sich dabei um eine vereinfachte Darstellung handelt – die Systematik der AdA-Filmontologie, die wir im übernächsten Kapitel ausführlich erläutern, ist in ihrer tatsächlichen Struktur deutlich komplexer.
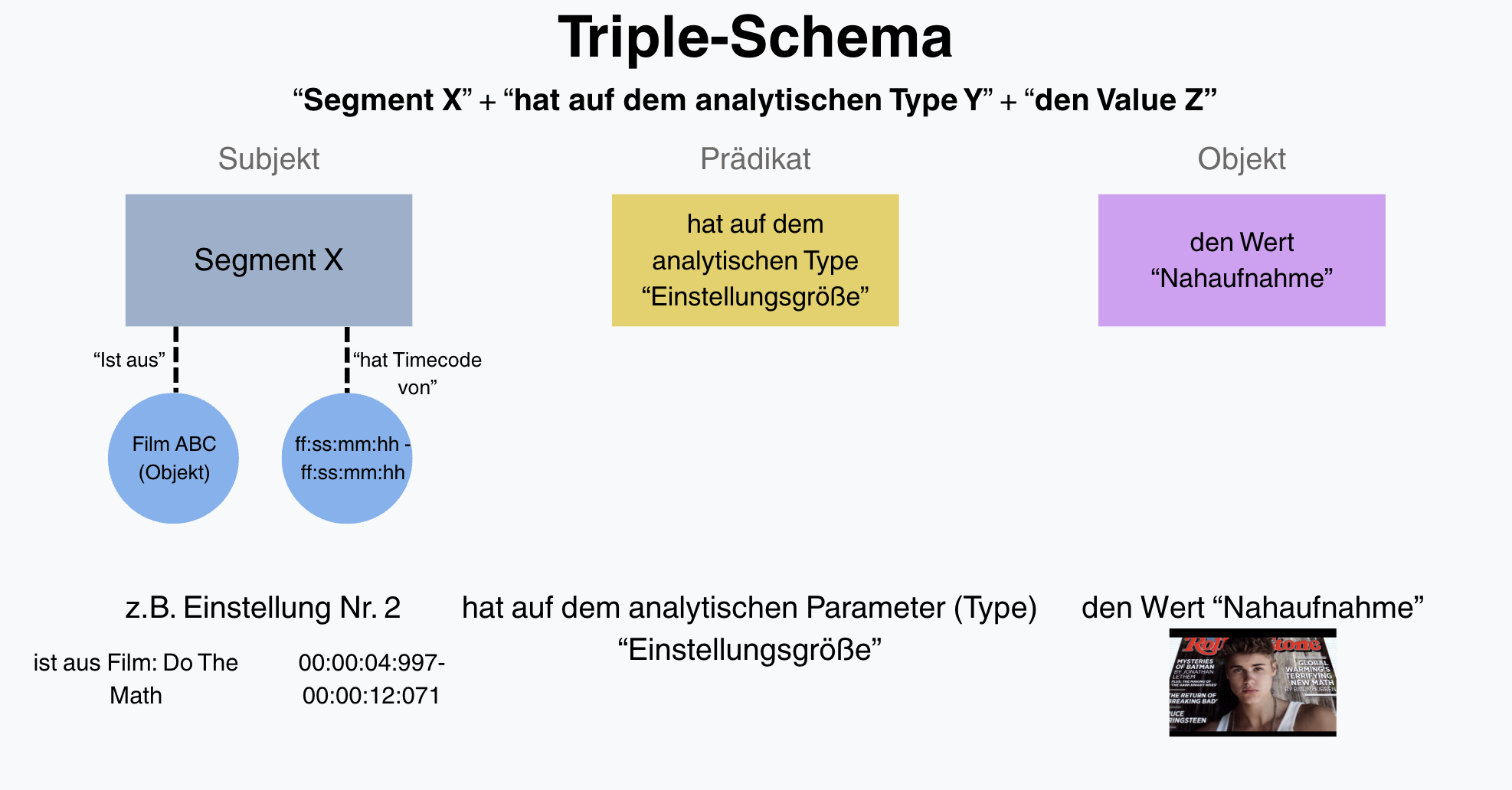
Fig. 5.2 Vereinfachte Darstellung der Triple-Struktur nach dem AdA-Ontologieprinzip#
5.1.3. Ontologie#
Eine Auflistung aller Subjekte/Individuen, Prädikate/Klassen/Typen oder Objekte/Eigenschaften/Werte eines Wissensgebiets wird in diesem Kontext als “Ontologie” bezeichnet.
Insofern beschreiben Ontologien ein semantisches Modell, das Wissen struktuiert. Sie beschreiben und ordnen Begriffe und Beziehungen zueinander, um das formulierte Wissen maschinenlesbar zu machen. Wie bereits erwähnt, ermöglichen spezifische Sprachen, wie z.B. RDF, OWL oder XSD, Standards für die Formulierung sowie Formalisierung von Ontologien.
Für eine bessere Übersicht fassen wir die Kernprinzipien des Semantic Web kurz zusammen:
Kernprinzipien des Semantic Web
Maschinenlesbarkeit von Daten
Informationen werden so strukturiert, dass sie sowohl für Maschinen als auch für Menschen lesbar sind
Verknüpfung von heterogenen Datenquellen
Eindeutige Identifikation durch URIs
Verwendung von URIs zur eindeutigen Benennung von Ressourcen
Jedes Objekt, jede Person, jeder Ort erhält eine eindeutige Webadresse
Verknüpfung von Daten (Linked Data)
Daten werden miteinander verknüpft, um Zusammenhänge herzustellen
Standardisierte Technologien (bzw. Sprachkonzepte)
Resource Description Framework (RDF) und Web Ontology Language (OWL) als Grundtechnologien
Gemeinsame Datenformate und Austauschprotokolle
Semantische Beschreibung von Beziehungen
Ontologien beschreiben Konzepte, Beziehungen und Relationen von Entitäten
Triple-Struktur (Subjekt-Prädikat-Objekt) zur Darstellung von Beziehungen
Interoperabilität
Ermöglicht die Zusammenarbeit verschiedener Datenquellen und Systeme
Wiederverwendung bestehender Web-Strukturen
Automatisierung
Ermöglicht automatische Verarbeitung und Schlussfolgerungen aus Daten
Unterstützt intelligente Suche und Datenverknüpfung
Im nächsten Schritt gehen wir im Detail auf die AdA-Filmontologie ein, um die hier genannten Kernprinzipien am konkreten Beispiel einer entwickelten Filmontologie verständlich zu machen. Vorher sind Sie gefragt: Wir haben ein paar Übungen erstellt, anhand derer nachvollziehbar gemacht werden soll, wie diese Ontologie einige grundlegende Vokabularien formalästhetischer Beschreibung in eine hierarchische Dateninfrastruktur erfasst.
5.1.4. Literatur#
Pfeilschifter, Y., Prado, J., Zorko, R., Buzal, A., Scherer, T., Stratil, J., & Bakels, J.-H. (2021). AdA-Filmontologie – Ebenen, Typen Werte. Accessed: 2025-03-04, Lizenz: [CC BY-SA 3.0].