6.3. Annotationsergebnisse: Datenabgleich und -erläuterung#
Sobald die Annotationsarbeit für das Video abgeschlossen ist, kann das Paket mit unserer Musterlösung verglichen werden. Die Lösungsdatei steht hier zum Download bereit. Bitte beachten Sie, dass die Videodatei stets neu verknüpft werden muss, um das Video in der Anwendung abspielen zu können.
Wichtig
Trotz der Verwendung der Ontologie können sich Annotationsentscheidungen von Person zu Person unterscheiden. Wichtig ist, dass die Ergebnisse miteinander verglichen werden können. Punktuelle Erläuterungen unserer Entscheidungen werden in diesem Kapitel ausgeführt.
6.3.1. Importfunktion#
In Advene gibt es die Möglichkeit ein bestehendes Annotationspaket in ein anderes zu importieren.
Wofür kann in diesem Schritt die Importfunktion nützlich sein?
Antwort
Diese Funktion ist hilfreich, um beispielsweise verschiedene Annotationen, die zum gleichen Video erstellt wurden, miteinander zu vergleichen.
Hierzu folgende Schritte durchführen:
Unter “File” die Option “Import package” anklicken
Das zu importierende Packet auswählen
Im “Package importer view” zur Unterscheidung der Annotationstypen einen Titelzusatz, wie z.B. IMPORTED, angeben. Dieser Zusatz wird hinter die importierten Annotationstypen gehängt
Anschließend die gewünschten Annotationstypen, die importiert werden sollen, anklicken
Die importierten Annotationstypen stehen nun zur Verfügung und können in der Timeline View angezeigt werden
Ein ausführlicherer Guide für das Importieren findet sich sowohl unter Punkt 3.3 (S. 45ff) im Manual als auch im zweiten Videotutorial (Video: Packages: Splitting, Merging, Importing)
Aufgabe 1#
Übungsaufgabe
Ziel: Vegleich und Analyse verschiedener ontologiebasierte Annotationspakete in Advene
Aufgabe:
Laden Sie die Musterlösung herunter
Verknüpfen Sie die Videodatei neu für die korrekte Wiedergabe
Nutzen Sie die Importfunktion, um Ihr eigenes Annotationspaket mit der Musterlösung zu vergleichen
Vergleichen Sie anschließend Ihre Annotationsergebnisse und -entscheidungen mit der Musterlösung
Bearbeitungzeit: Ca. 20 Min.
6.3.2. Error-Package: Fehlersuche & Korrektur#
Im Folgenden steht hier ein Annotationspaket bereit, das einige Fehler enthält.
Aufgabe 2#
Übungsaufgabe
Ziel: Identifikation und Behebung von Fehlern in einem Annotationspaket
Aufgabe:
Laden Sie das fehlerhafte Annotationspaket herunter
Nutzen Sie die zuvor erlernte Importfunktion für den Vergleich
Identifizieren Sie alle Fehler
Korrigieren Sie die gefundenen Fehler mit den passenden Advene-Werkzeugen
Bearbeitungzeit: Ca. 25-30 Min.
Welche Fehler konnten gefunden werden?
Lösung
Auf der Spur ‘Dialogue Text’ wurden 2 Annotationen gelöscht

Auf der Spur ‘Shot’ wurden Annotationen gemerged und nicht renummeriert
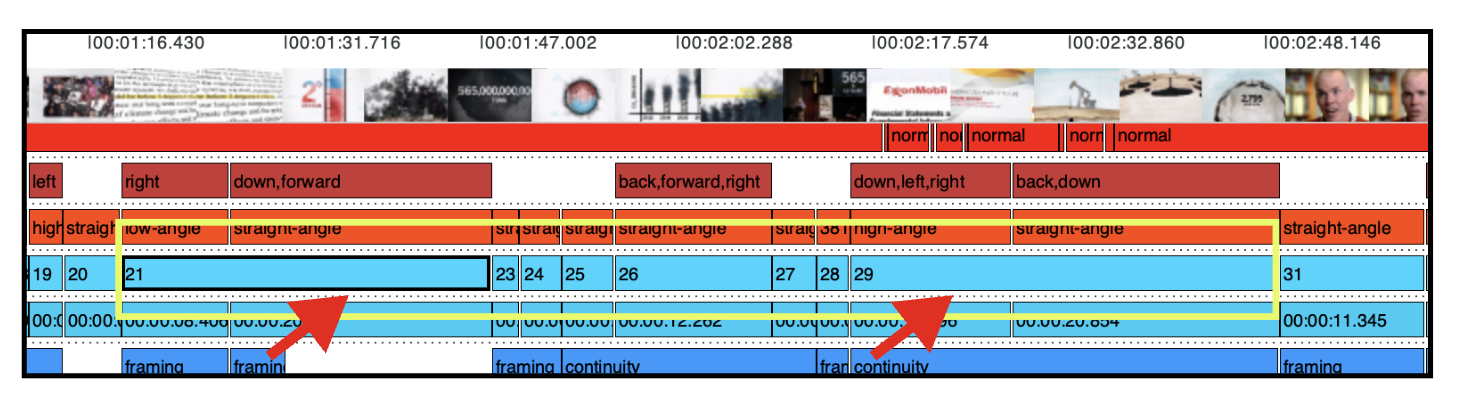
Auf der Spur ‘Recording/Playback Speed’ hat die erste Annotation einen falschen Wert ➡️ statt ‘timelapse’ müsste dort ‘normal’ eingetragen werden
Der Annotationstyp ‘Volume’ wurde gelöscht
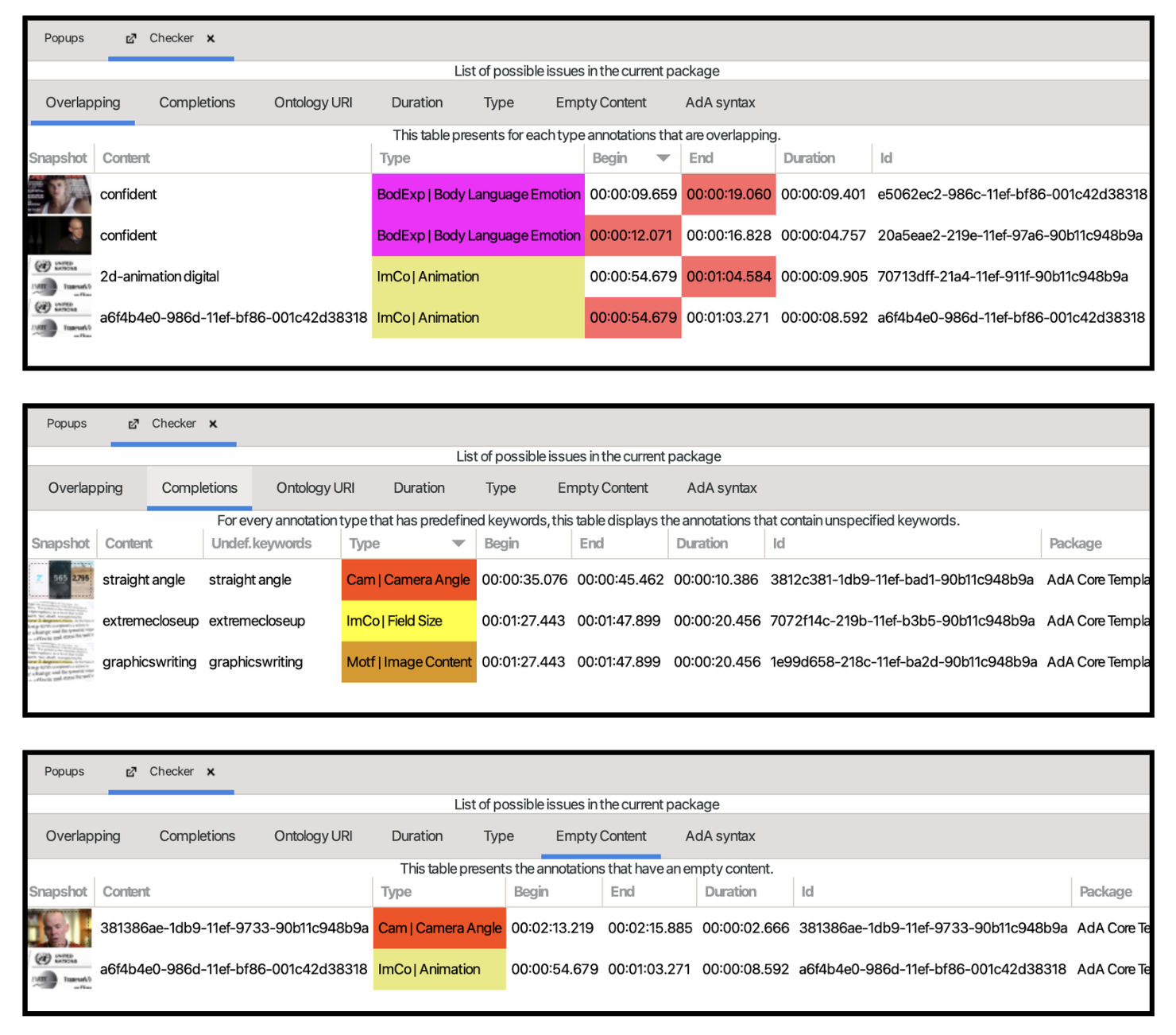
Weitere Fehler können durch eine Überprüfung mit der Checker-Funktion gefunden werden. Um den Checker als View zu öffnen, oben in der Menüleiste auf ‘View > Open View’ gehen und den Checker anklicken. Folgende Fehler sind über den Checker auffindbar:
a) Overlapping: Annotationen, die sich in ihrer Dauer überlappen
b) Completions: Undefinierte Keywords, die von den Keywords der Ada-Ontologie abweichen
c) Empty Content: Annotationen ohne Inhalt
Wie können die Fehler korrigiert werden?
Lösung
Es kann auch hier für einen direkten Abgleich nützlich sein das korrekte Annotationspaket zu importieren.
Nachfolgend gehen wir alle Fehler kurz durch und stellen eine Lösung bereit:
Annotation neu hinzufügen und durch Freitext-Eingabe Untertitel als Annotionswert ergänzen. ODER: Import der Lösungsdatei und die fehlende Annotation aus der Spur reinkopieren; ebenso kann die Gesamtzahl der Annotationen für einen Typ durch einen Rechtsklick (ganz unten in der Pop-up-Liste) angezeigt werden, so kann durch die Überprüfung der Gesamtzahl der Annotationen für eine Spur direkt nach Abweichungen kontrolliert werden
Shots wieder richtig segmentieren und korrekt renummerieren
Falschen Wert korrigieren
Durch Import des Templates kann der Annotationstyp ‘Volume’ erneut importiert werden. Anschließend automatische Erkenner für ‘Waveform’ durchführen und die automatisch generierte Annotation auf die Spur ‘Volume’ duplizieren; danach die neu erstellte Spur löschen (so bleibt die Spur als Teil der vordefinierten AdA-Syntax erhalten)
a) Overlapping Annotations, b) Unspecified Keywords und c) Empty Content: hier zunächst die Checker Funktion aktivieren. Anschließend Fehler beheben indem für a) eine Korrektur des Timecodes für die sich überschneidenden Annotationen durchführt, für b) die richtigen Keywords gemäß Ontologie einträgt und c) den leeren Annotationen die richtigen Werte zuordnet
6.3.3. Diskussion der Ergebnisse#
Mit der AdA-Filmontologie kann ermöglicht werden auf der Grundlage eines Klassifikationsschemas filmanalytische Beobachtungen zu systematisieren. Die Systematisierung ist also ein notwendiger Schritt, um Metadaten einerseits unter ganz spezifischen Kriterien herzustellen als auch anschließend vergleichen zu können.
Ziel dieser Fallstudie ist es in einem nächsten Schritt durch die Visualisierung dieser Metadaten audiovisuelle Inszenierungsmuster zu analysieren und als Affekrhetorik zu qualifizieren. Doch bevor wir uns der eigentlichen Analyse widmen, wollen wir die Ergebnisse der Annotationsarbeit diskutieren. Denn Annotationsentscheidungen sind nicht immer selbsterklärend. Und auch eine Ontologie kann ihre Grenzen aufweisen.
Für die Diskussion gehen wir nachfolgend punktuell auf konkrete Probleme und Fragen ein, die während des Annotierens aufgekommen sind. Da eine ganzheitliche Diskussion aller Annotationsentscheidungen und Schritte den Rahmen dieser Übungen sprengt, adressieren wir hier die wichtigsten.
Annotationstyp: Field Size (Einstellungsgröße)#
Die Frage nach dem Referenzobjekt zur Bestimmung der Einstellungsgröße ist nicht immer eindeutig. Dies gilt insbesondere für die Einstellungen, die 2D animiert sind oder in denen eine Frame-in-Frame Anordnung zu sehen ist.
Bei Einstellungen also, in denen die Bestimmung des Referenzobjekts zur Messung der Einstellungsgröße unklar blieb, haben wir den Wert ‘neither’ eingetragen, wie beispielsweise hier:

Die UUID dieser Annotation ist folgende: 0aac70ea-219b-11ef-9bca-90b11c948b9a
Warum ist die Festlegung auf einen Wert in dieser Einstellung schwierig?
Antwort
Auf eine 2D simulierte Ansicht eines Papierblocks blendet sich von links nach rechts der in blau gefärbte Schriftzug “The Numbers” ein. Diese Ansicht erinnert an eine Präsentationsfolie. Obwohl die Einstellung im Verhältnis zu unserem Standpunkt nah wirken mag, lässt sich eine Distanz nicht eindeutig festlegen, da die Einbettung in eine räumliche Umgebung fehlt, die eine Skalierung zulassen würde.
2D-Animationen#
Bei multiplen und/oder simultan auftretenden Animationselementen sieht es ähnlich aus. Es gibt keine klaren Relationen oder Anhaltspunkte im Raum, durch die eine Skalierung zur Bestimmung einer Einstellungsgröße nach bekannten Systemen möglich wäre, wie es bei dieser Annotation mit der UUID 3fbfc132-00a8-11ef-a9a8-001c42d38318 der Fall ist:

In diesem Beispiel wäre die Möglichkeit für ein kontrastierendes Syntaxelement wie [VS] ebenfalls sinnvoll, da durch die Trennung der verschiedenen Bildgrenzen multiple Elemente zu sehen sind. Wir haben uns für die Werte ‘neither’ sowie ‘extreme long shot’ entschieden. Der Wert ‘extreme long shot’ ist anwendbar auf das rechte Bild im animierten Splitscreen. Die Referenzobjekte zur Bemessung der Entfernung sind hier die Kräne.
Dort, wo Fragen nach Skalierungen und Referenzbestimmungen komplexer werden, zeigen sich jedoch gleichzeitig auch die Grenzen einer Ontologie.
Frame-in-Frame#
In Bezug auf die Frame-in-Frame-Einstellungen gilt folgende Entscheidung innerhalb unseres Workflows:
Sowohl der äußere Rahmen als auch das in diesem Rahmen eingesetzte Bild können als Referenzobjekt bestimmt werden. Daher haben wir uns für den Wert ‘neither’ und dem Wert für die Einstellungsgröße entschieden, der aus dem zweiten Frame hervorgeht. Ein Annotationsbeispiel mit den Werten ‘neither’ und ‘medium close up’ ist hier und unter folgender UUID 3fc06a7e-00a8-11ef-a9a8-001c42d38318 zu sehen:
Annotationstyp Setting#
Das ‘Setting’ wird innerhalb der Ontologie als Ort des narrativen Handlungsgeschehens definiert. Doch wie geht man mit Einstellungen um, die nur schwer narrativ zu fassen sind und deren örtliche Bestimmung kaum möglich ist?
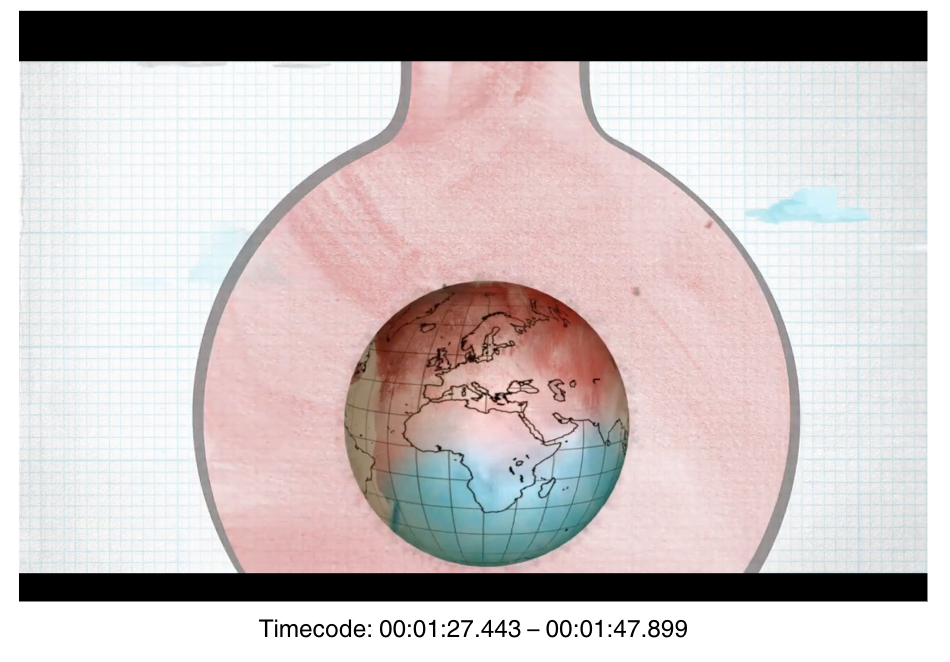
In Bezug auf unser Beispielvideo betrifft dies insbesondere jene Einstellungen, die 2D animiert sind. Denn dort beziehen sich die animierten Elemente – insbesondere die Schriftzüge, die Nummerneinblendungen oder die Simulationen der Weltkugel – auf keine realen Verhältnisse oder räumlichen Anordnungen. Bei Einstellungen, in denen das Setting nicht ohne weiteres bestimmbar war, haben wir keine Annotationen erstellt. Diese leeren Abschnitte verweisen insofern direkt auf die Grenzen bzw. Leerstellen der Ontologie. Folgende Annotation unter der UUID
860166ff-21a4-11ef-a632-90b11c948b9a macht dieses Problem exemplarisch sichtbar:
Annotationstyp: Recording/Playback Speed#
Durch den Annotationstyp Recording/Playback Speed kann die Aufnahmegeschwindigkeit erfasst werden. Es gibt Annotationen von sehr kurzer Dauer, die einen Timelaps markieren. Definiert wird der Timelapse folgendermaßen:
Noticeable acceleration of the viewers’ time perception. Movements appear as unnaturally fast. Objects, such as plants, that may otherwise be perceived as static can get animated through this technique in comparison to everyday perception.
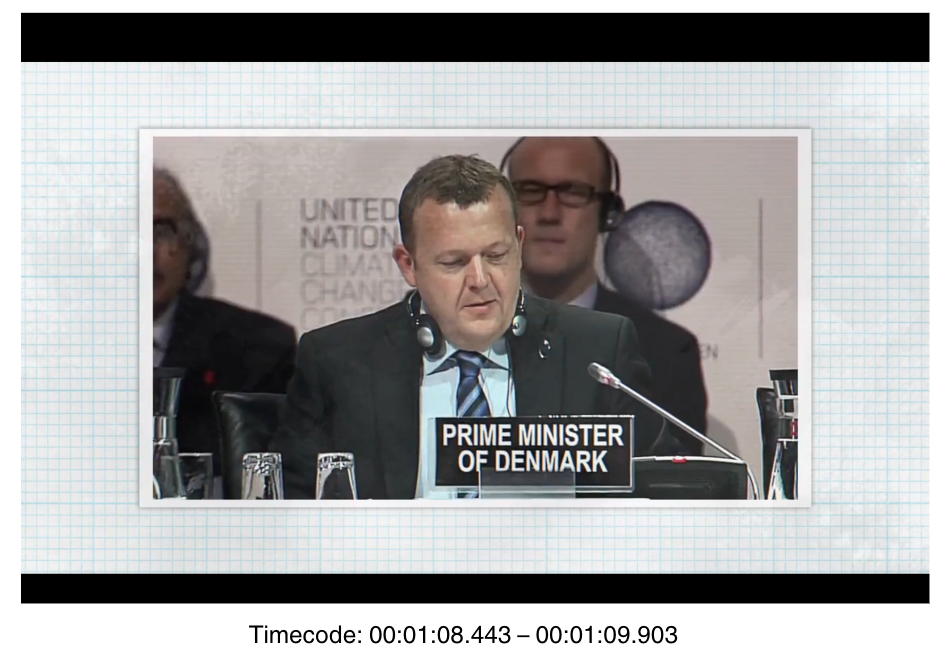
In diesem Screenshot ist die Erfassung solcher Timelapse in der Timeline zu sehen:
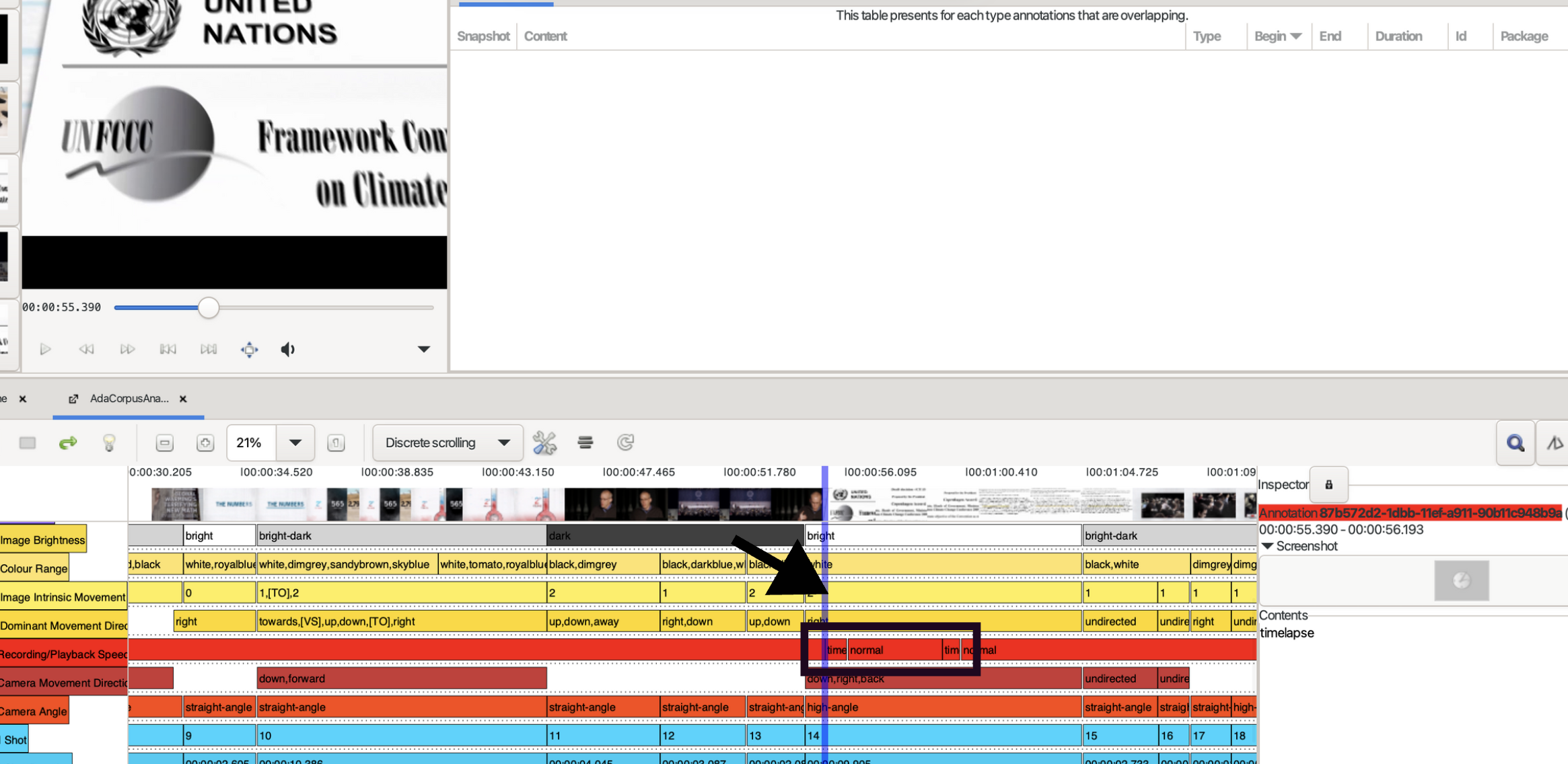
Die dazugehörigen Annotationen können unter folgenden UUIDs gefunden werden: 87b572d2-1dbb-11ef-a911-90b11c948b9a sowie ab1283ac-1dbb-11ef-b029-90b11c948b9a
Den dazugehörigen Video-Ausschnitt blenden wir hier nochmals ein:
Antwort
Die Bewegungsrichtung der Kamera korreliert mit den Timelaps. Mit der Änderung der Bewegungsrichtung synchron zu dem Einsatz des Timelaps entsteht eine dynamische Bildkomposition, die sich durch Geschwindkeitszunahme sowie Bewegungsveränderung von der restlichen zeitlichen Anordnung des Videos unterscheidet. Interessant ist ebenso, dass die markantesten Bewegungsveränderungen der Kamera mit den animierten Einstellungen einhergehen. Die 2D-Animationen wirken, insbesondere im Kontrast zu den im Vergleich recht statischen Szenen auf der Bühne oder im Interview, wesentlich energetischer.
Advene-Timeline und Weiterentwicklung der Timeline#
Die Timeline in Advene ist bereits eine Form von Visualisierung, mit der Inszenierungsmuster erkennbar werden. Was die Synchronizität, Temporalität und Multimodalität der einzelnen Spuren angeht, ist sie jedoch nur begrenzt lesbar. Eine speziell entwickelte Visualisierung, die diese Dynamiken unter der Möglichkeit spezifischer Konfigurationsoptionen ins Zentrum der Analyse rückt, ist also ein wichtiger Schritt zur Anpassung der Datenqualifizierung an die konkreten Anforderungen filmwissenschaftlicher Analyse.
Eine ausführliche Datenexploration sowie Hypothesenpräsentation führen wir dahingehend mit der AdA-Timeline im Kapitel Datenvisualisierung durch.
6.3.4. Miteinbeziehung weiterer Annotationstypen#
Für eine präzise und vollständige Annotation empfiehlt es sich mit allen Annotationstypen der Ontologie zu arbeiten. Da die Annotation aller Typen der Ontologie weitaus mehr Zeit in Anspruch nimmt als im Rahmen der Übungen vorgesehen, haben wir uns für die Annotation mit dem AdA Core-Template entschieden.
Wie sieht jedoch mit den Annotationstypen ‘Splitscreen’, ‘Frame-in-Frame’ oder ‘Visual Pattern’ aus? Inwiefern könnten diese Typen die spezifischen Charakteristika unseres Beispielgegenstandes hervorheben?
Splitscreen#
Eine sehr dominante und für das Video entscheidende Inszenierungsmodalität ist die Verwendung von Splitscreens. Insgesamt zwei Splitscreens werden in den Animationsabschnitten eingesetzt und sind in ihrer Darstellung identisch.

In den je abgetrennten Screens werden die drei kritischen Zahlen für eine Einhaltung der 2-Grad-Grenze in Bezug auf den Co2-Austoß als visuelle Einheit inszeniert.
Durch die Miteinbeziehung der Annotationstypen für Splitscreens könnten die Häufigkeit, die Anzahl der verwendeten Splitscreens innerhalb einer Einstellung und darüber hinaus die Splitscreen-Dynamiken erfasst werden.
Frame-in-Frame#
Die auffälligsten Frame-in-Frame Kompositionen finden sich in den Einstellungen, die Found Footage Material einbinden. Die Frame-in-Frame Anordnung markiert somit einen klaren visuellen Bruch in der gesamten Bilddynamik und ordnet das gezeigte Material in den Verwendungszusammenhang des Videos ein.
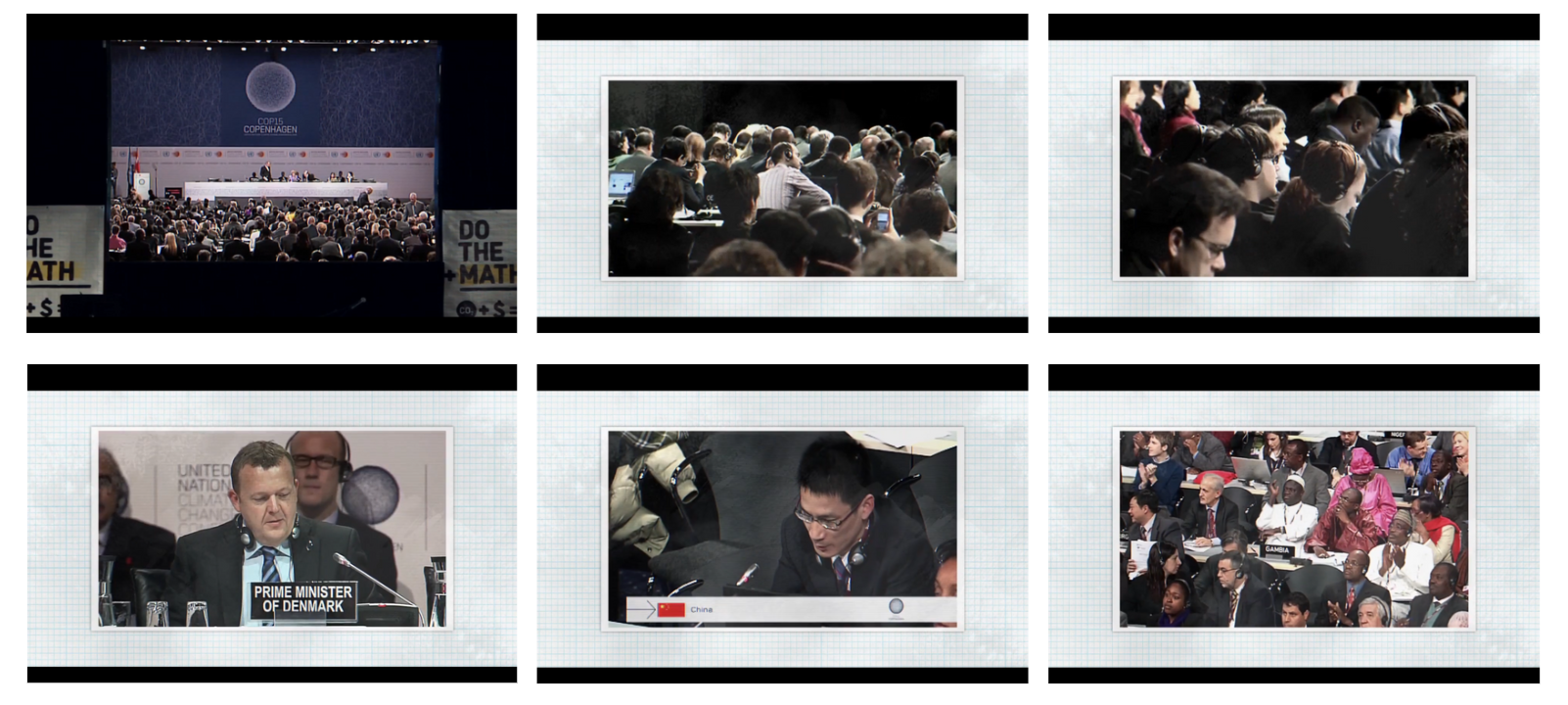
Ebenso könnte diskutiert werden, inwiefern sowohl die Frame-in-Frame Einbindungen des Found Footage Materials als auch die animierten Einstellungen Teil des Vortragsarrangements auf der Bühne sind, wie in dem ersten Bild der Reihe als auch in diesem diesem Beispiel zu sehen ist:

Sichtbar hier wird eine Screen-within-Screen Gestaltung, die unter dem Annotationstyp Frame-in-Frame ebenfalls Berücksichtigung findet und annotiert werden kann.
Eine freitextliche Erhebung von Frame-in-Frame Kompositionen könnte die spezifischen Modalitäten dieser Inszenierungsmuster für eine Datenanalyse insofern sinnvoll ergänzen.
Visual Pattern#
Unter dem Annotationstyp ‘Visual Pattern’ werden abstrakte Muster oder Formen erfasst. Insbesondere in den animierten Einstellungen könnten unter Miteinbeziehung dieses Annotationstyps grafische Elemente, Synchronizitäten von Mustern und abstrakte Visualisierungsstrukturen bestimmt werden. Ein Beispiel für eine Annotation der Werte ‘centre Figure, circular’ wäre folgende Ansicht:

Insgesamt bietet das Framework der Ontologie sehr umfangreiche und spezifische Annotationsoptionen, die an den zu untersuchenden Gegenstand angepasst und jederzeit erweitert werden können. Dies ermöglicht die Herstellung feingliederiger Mikroanalysen auf der Basis von allumfassenden Annotationsdaten.