5.3. AdA-Filmontologie: Filmanalyse und Semantic Web#
In der vorigen Übung haben wir gezeigt, wie ein Set an filmanalytischen Beschreibungen in eine Ontologie nach Semantic Web Standards überführt werden kann. Schrittweise soll so nachvollzogen werden können, wie mit einem semantischen Modell formalästhetische Relationen als maschinenlesbare Triple hergestellt werden können. Ausgehend von dieser Systematisierung hat die BMBF-geförderte Nachwuchsgruppe “Affektrhetoriken des Audiovisuellen” (kurz: AdA, Laufzeit: 2016-2021) eine Filmontologie entwickelt, die in enger Zusammenarbeit mit Informatiker und Entwickler von Advene, Dr. Olivier Aubert entstanden ist.
5.3.1. Methode#
Die methodische Umsetzung des AdA-Projekts greift zurück auf die eMAEX-Methode. eMAEX steht für electronically based media analysis of expressive-movement-images und beschreibt eine systematisierte Methode, in der das Zuschauendenempfinden über Rhythmus- und Bewegungsprofile als multimodale Ausdrucksbewegungsbilder des Films untersucht wird. Im Fokus steht hierbei die empirische Rekonstruktion einer Zuschauendenaffizierung als ästhetische Muster der Gestaltung audiovisueller Bewegungen. Die in der Ontologie festgelegten analytischen Dimensionen basieren auf dem Konsens der eMAEX-Methode (Freie Universität Berlin, 2007).
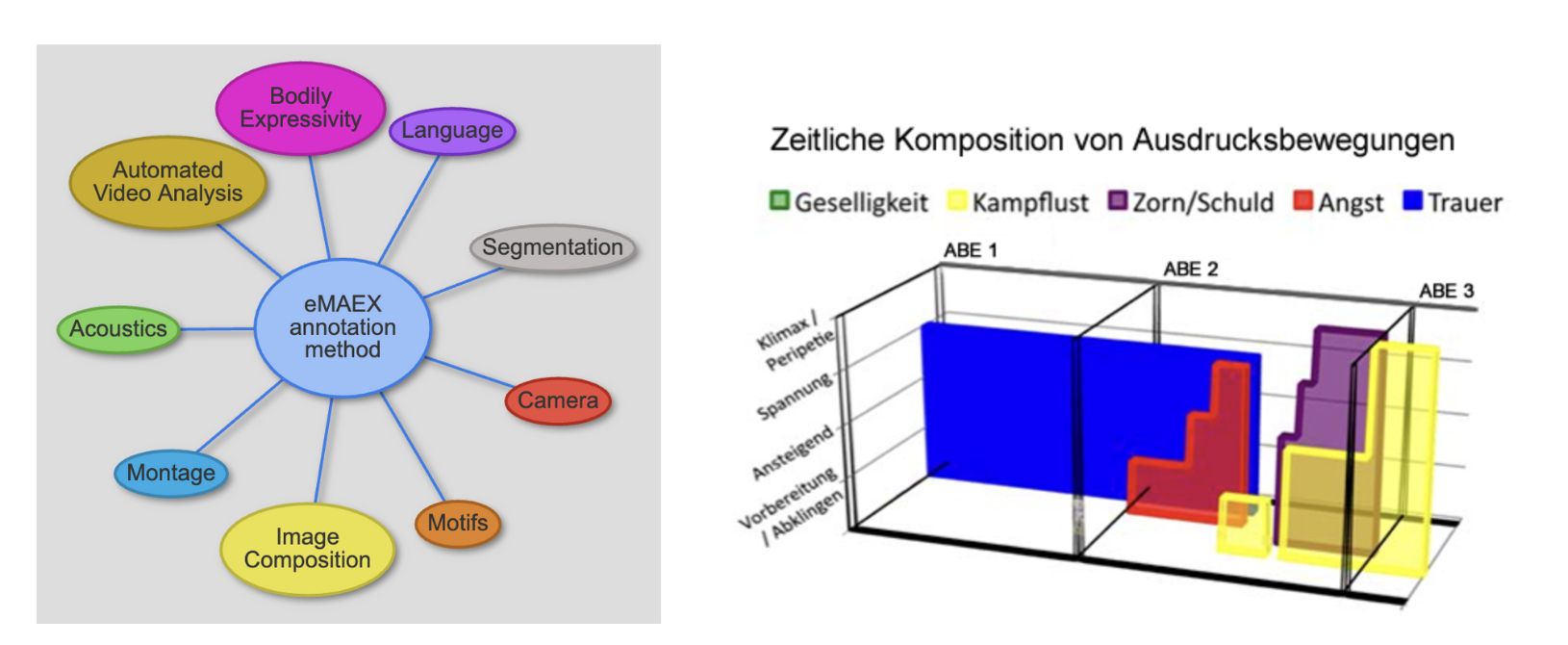
Fig. 5.4 eMAEX-Annotationsmethode: Analyseebenen &
Zeitliche Entfaltung von Ausdrucksbewegungen © Bildquelle: Empirische Medienästhetik – das eMAEX-System#
5.3.2. Ontologie#
Ausgehend von diesen Überlegungen wurde auf Grundlage des oben skizzierten Frameworks eine maschinenlesbare Analysesystematik (Ontologie) entwickelt. Die Notwendigkeit einer maschinenlesbaren Systematik ergibt sich zwangsläufig, denn durch die Analyse großer Datenmengen häufen sich Beschreibungsdaten an. Ohne maschinelle Unterstützung bei der Auswertung wären solche Analysen großer Datenkorpora, aufgrund ihres Umfangs, nicht zu bewältigen.
Um eben diese großen Datensätze an multidimensionalen Beschreibungen für einen größeren Korpus überhaupt erst zu ermöglichen, wurde eine auf Semantic Web Prinzipien basierende Systematik entwickelt – die AdA-Filmontologie, eine OWL-basierte-Ontologie (Pfeilschifter et al., 2021).
Durch die Integration (semi-)automatisch erzeugter Annotationen als auch die Möglichkeit der Maschinenlesbarkeit sowie weitere Verknüpfungsmöglichkeiten für semantische Metadaten, können filmanalytische Beschreibungsmuster als semantische Triple formuliert und diese in Form von Linked Open Data zugänglich, durchsuchbar sowie für den Austausch und Vergleich von Analysedaten öffentlich gemacht werden.
Was sind Linked Open Data?
Linked Open Data (LOD) ist ein Konzept nach Semantic Web Prinzipien, welches die Veröffentlichung und Verknüpfung offen zugänglicher Daten im Internet beschreibt. Es ermöglicht, dass Daten aus verschiedenen Quellen miteinander in Relation treten, um diese leichter durchsuchbar wie auch nutzbarer zu machen (Berners-Lee, 2006).
Linked Data: Stellt sicher, dass die Daten miteinander verknüpft sind.
Open Data: Stellt sicher, dass die verknüpften Daten, z.B. Datenbanken von öffentlichen Einrichtungen oder Museen etc., frei und offen zugänglich sind.
Mehr Infos zu den Prinzipien von Linked Open Data gibt es beispielsweise in einem Tutorial von Programming Historian.
Struktur der AdA-Ontologie#
Die AdA-Ontologie umfasst 502 einzelne Annotationswerte, die 78 Annotationstypenzugeordnet sind, welche wiederum auf 8 Beschreibungsebenen, wie z.B. Akustik, Montage, Bildkomposition oder Kamera, organisiert sind:
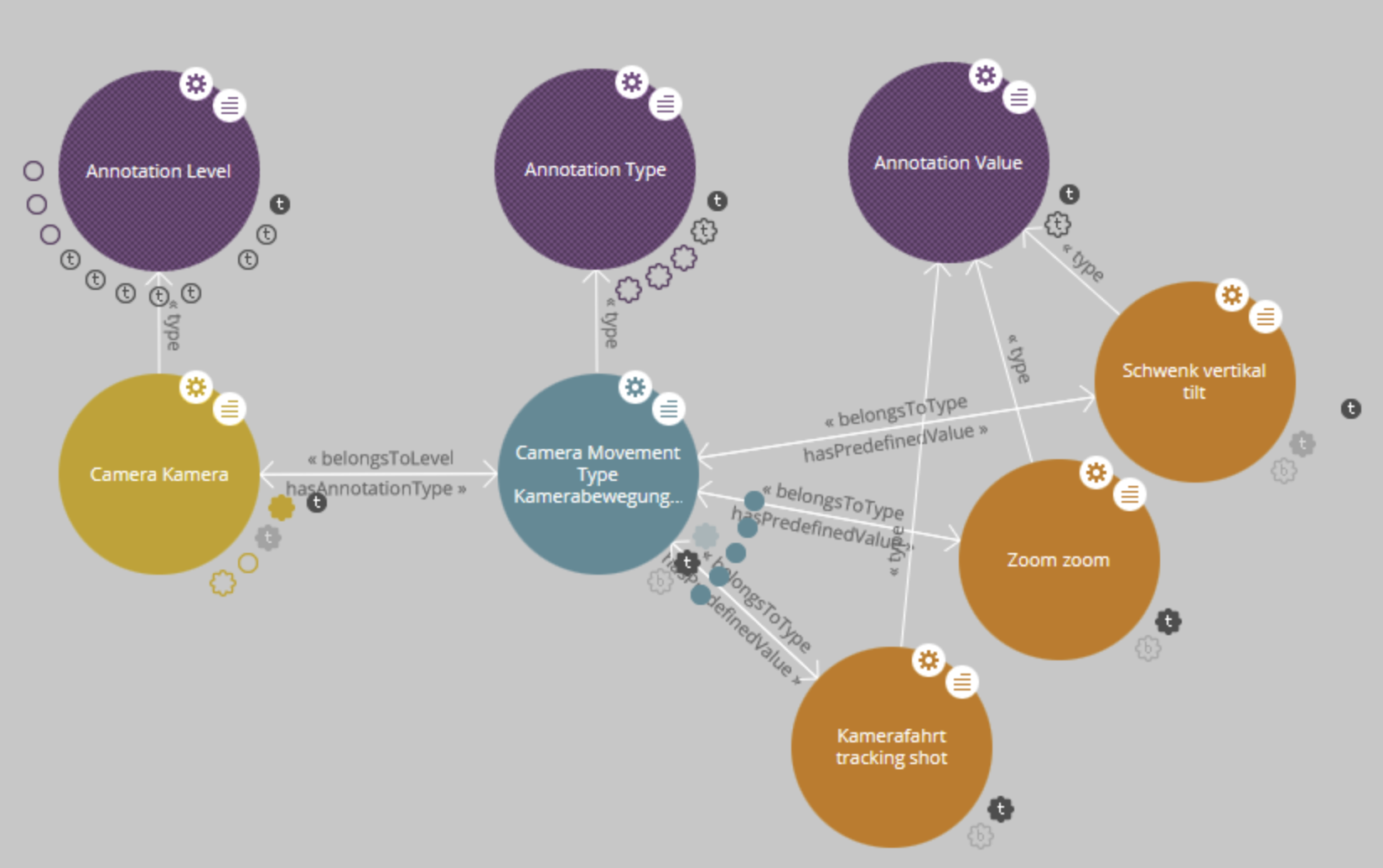
Fig. 5.5 Struktur: Ebenen, Typen, Werte – visualisiert mit LodLive, © Bildquelle: ProjectAdA-Github#
Definiert sind die filmanalytischen Konzepte, Begriffe und Beschreibungen auf der Grundlage von OWL (Web Ontology Language) und RDF (Ressource Description Framework) in einer Klassenstruktur mit dazugehörigen Eigenschaften:
Annotationslevel sind allgemeine Beschreibungskategorien, die aus einem Set ähnlicher Annotationstypen bestehen (z.B. Akustik oder Kamera).
Annotationstypen sind Konzepte der Filmanalyse, unter denen ein Film analysiert wird (z.B. Musik: Stimmung oder Kamerabewegung: Tempo).
Annotationswerte beschreiben die je konkreten Eigenschaften, die ein Annotationstyp haben kann (z.B. Kamerabewegung: Tempo: langsam, mittel, schnell, wechselnd).
Die mit OntoViz erstellte interaktive Visualisierung zeigt ebenfalls exemplarisch die dreigliedrige Dimension der Ontologie (hier als Ausschnitt):
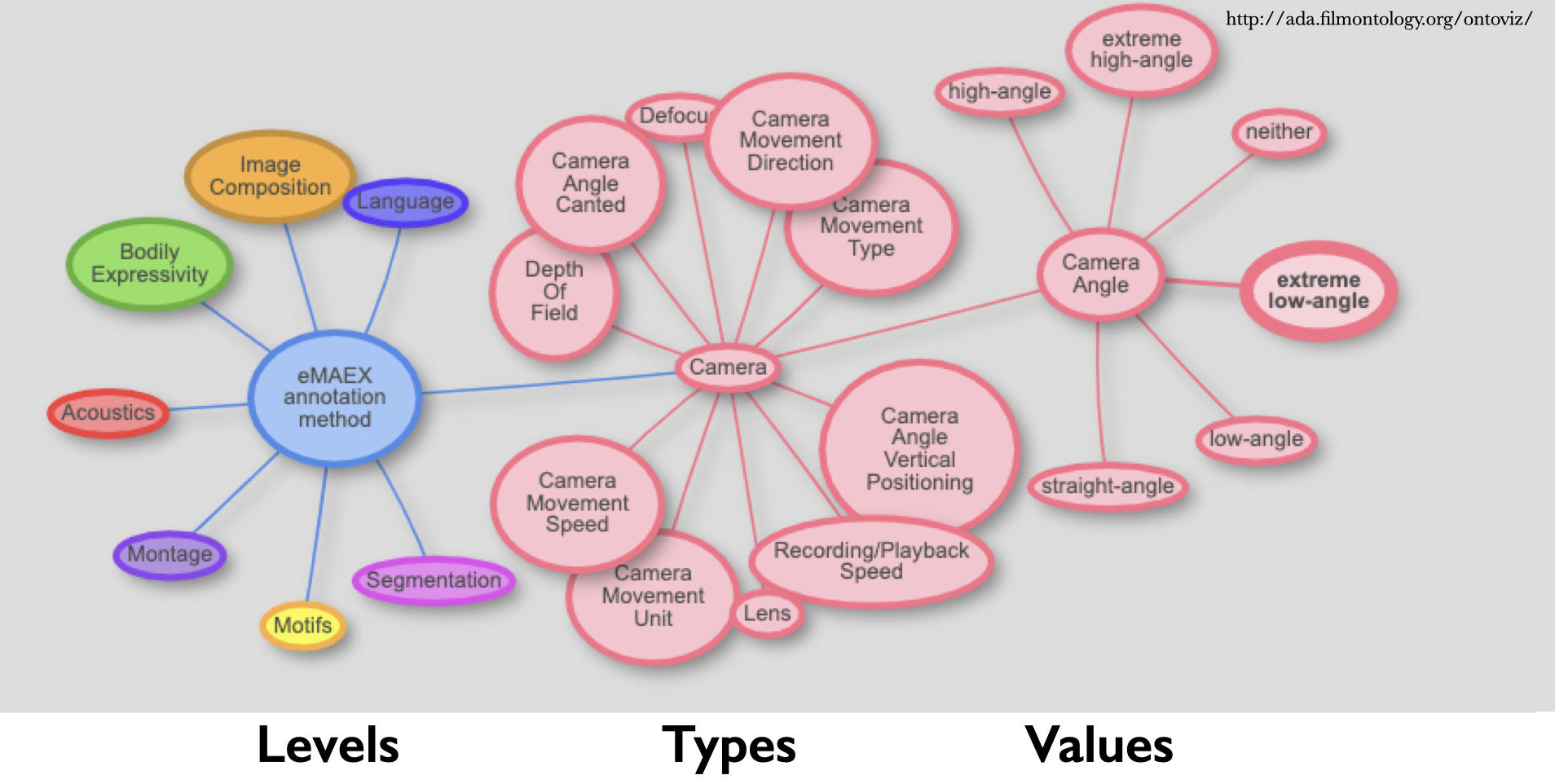
Fig. 5.6 Visualisierung mit OntoViz, © Bildquelle: AdA-Ontoviz#
Annotationsmodell und Architektur#
Die Ontologie umfasst ein Annotationsmodell für semantische Videoannotationen. Annotationsdaten werden auf Basis des WC3 Web Annotation Data Model erstellt. Sie bestehen immer aus einem “Annotationtarget” (also ein Ziel, hier: ein Zeitfragment eines Videos) sowie einen “Annotationbody” (also dem Inhalt der Annotation mit Informationen zu Annotationstypen/-werten, Autor und weiteren Metadaten). Das Videofragment basiert auf der Vewendung des W3C Media Fragment URI Spezifikation (Bakels et al., 2023).
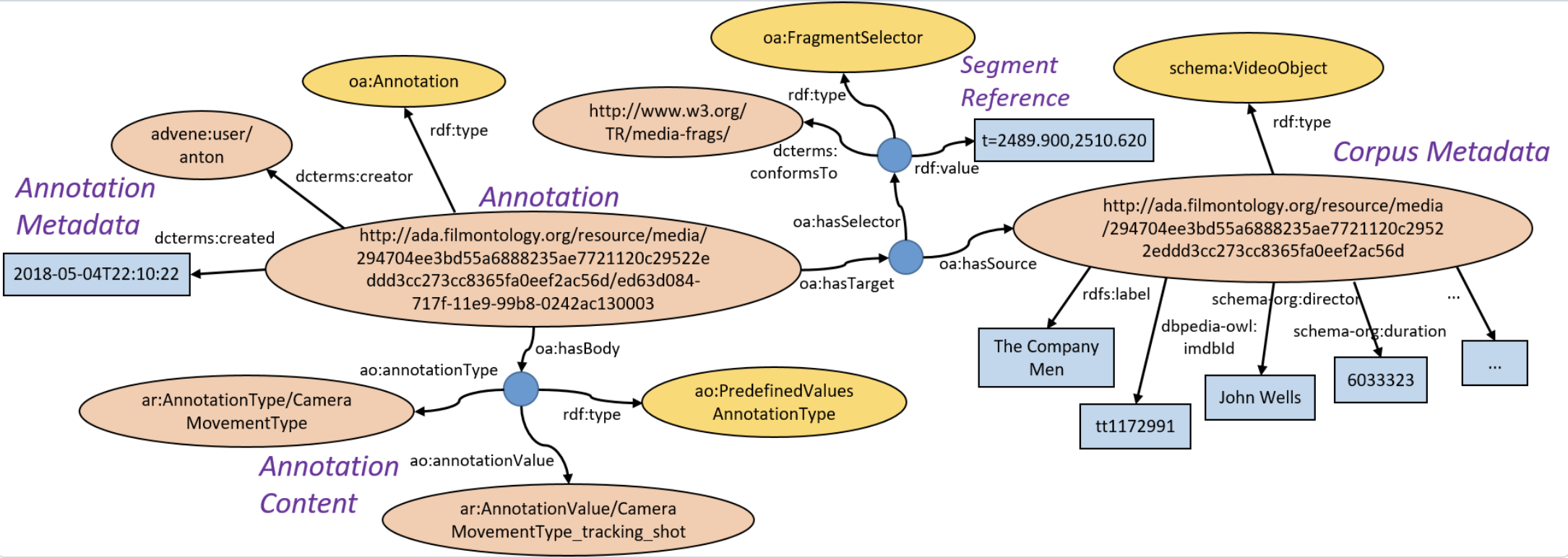
Fig. 5.7 Beispielannotation einer Kamerafahrt als RDF-Graph, © Bildquelle: ProjectAdA-Github#
Die Informationen, wie auf der Abbildung zu sehen, sind in RDF maschinenlesbar gespeichert. Jedes Konzept der Ontologie (und jede einzelne Annotation) hat einen eindeutigen Bezeichner, also eine URI.
Labels und Beschreibungen#
Des weiteren werden die Annotationsarten wie folgt unterschieden:
FreeTextAnnotationType: Annotationen durch Freitexteingabe ohne spezifische Ontologie-Referenz
PredefinedValuesAnnotationType: Annotationen, deren Inhalte sich aus einem oder mehrerer Werte der Ontologie ergeben
ContrastingAnnotationType [VS]: Beschreibt die Möglichkeit, ein Syntaxelement zu verwenden, das zwei kontrastierende Werte aus der Ontologie verbindet
EvolvingAnnotationType [TO]: Beschreibt die Möglichkeit, ein Syntaxelement zu verwenden, das eine kontinuierliche Entwicklung zwischen zwei Werten der Ontologie anzeigt
Ebenso wird unterscheiden in:
Single Value: Nur ein einziger Wert pro Annotation kann gewählt werden
Multiple Value: Mehrere Werte pro Annotation können gewählt werden
Ordered from value1 to value2: Beschreibt eine sequenzielle Ordnungslogik der Werte für einen bestimmten Typ
Die gesamte Ontologie steht auf Github zur Verfügung. Eine PDF-Version, besonders geeignet für die Annotationsarbeit, ist auf der Website als Teil des AdA-Toolkits sowie hier in der deutschen Fassung Version 1.0. (Stand Juli 2021) als Download hinterlegt.
Lizenzhinweis: “AdA-Filmontologie” von Affektrhetoriken des Audiovisuellen unter der Lizenz CC BY-SA 3.0 via AdA-Toolkit FU Berlin
Eine durchsuchbare Online-Version stellt die Datensätze der Ontologie ebenfalls zur Verfügung. Die Daten werden über den RDF-Triplestore OpenLink Virtuoso und LodView bereitgestellt. Die eMAEX-Methode empfehlen wir als Einstiegspunkt. Weitere Ressourcen sind unten exemplarisch aufgeführt:
Annotation Level |
Annotation Type |
Annotation Value |
|---|---|---|
5.3.3. Videoannotation#
Die Ontologie selbst stellt das methodische Framework bereit, welches als grundlegendes Analysegerüst für die Videoannotation genutzt werden kann. Die Annotationen werden in der frei zugänglichen Videoannotationssoftware Advene angelegt. Hierzu wurden in enger Kollaboration mit dem Entwickler von Advene die Funktionsweisen angepasst und erweitert, um den spezifischen Anforderungen filmwissenschaftlicher Analyse gerecht zu werden und diese direkt mit der entwickelten Ontologie zu verknüpfen.
Wichtig
Grundsätzlich gilt, dass es sich bei dieser Ontologie um ein Datenframework handelt. Das heißt, dass die Ontologie in ihren Prinzipien und ihrer Logik toolagnostisch ist.
Was bedeutet toolagnostisch?
Insbesondere oft im Kontext der Softwareentwicklung oder in der IT-Infrastuktur verwendeter Begriff, meint toolagnostisch, dass bestimmte Methoden, Konzepte oder Frameworks unabhängig von einem spezifischen Werkzeug angewendet werden können. Wichtig ist, dass das Prinzip oder die Methode mit verschiedenen Tools umgesetzt werden kann.
Das Framework ist somit die Entwicklung einer maschinenlesbaren, filmanalytischen Ontologie, welche im Rahmen des AdA-Projekts in die Funktionsweisen von Advene integriert wurde. Die Möglichkeit der Integrierung in andere Tools, wie z.B. ELAN, steht somit offen und ist in der Theorie umsetzbar.
Mit einem Template, das auf der Filmontologie basiert, können in Advene semantisch strukturierte Annotationsdaten hergestellt werden. Zudem gibt es eine AdA Corpus Analysis View, welche ein gebündeltes Set an Annotationstypen für die Annotationsarbeit bereithält.
Im Rahmen dieser Fallstudie zur Auswertung von Affektrhetoriken in Online-Videos zur Klimakrise haben wir Annotationen mit der AdA Corpus Analysis View erstellt.
In der nächsten Aufgabe erläutern wir im Detail, wie wir (semi-)automatisch generierte Annotationen mit dem Core-Template in Advene erstellt und bereinigt haben. Zwei Videotutorials sowie ein umfangreiches Manual sollen dabei helfen, die einzelnen Schritte nachvollziehen und eigenständig ausführen zu können.
5.3.4. Literatur#
Bakels, J.-H., Grotkopp, M., Scherer, T., & Stratil, J. (2023). Screening the Financial Crisis: A Case Study for Ontology-based Film Analytical Video Annotations. Accessed: 2025-03-04.
Berners-Lee, T. (2006). Linked Data. Accessed: 2025-03-12.
Pfeilschifter, Y., Prado, J., Zorko, R., Buzal, A., Scherer, T., Stratil, J., & Bakels, J.-H. (2021). AdA-Filmontologie – Ebenen, Typen Werte. Accessed: 2025-03-04, Lizenz: [CC BY-SA 3.0].
Freie Universität Berlin (2007). Empirische Medienästhetik. Accessed: 2025-03-04.